自己动手实现 HashMap(Python字典),彻底系统的学习哈希表(上篇)——不看血亏!!!
HashMap(Python字典)设计原理与实现(上篇)——哈希表的原理
在此前的四篇长文当中我们已经实现了我们自己的ArrayList和LinkedList,并且分析了ArrayList和LinkedList的JDK源代码。 本篇文章主要跟大家介绍我们非常常用的一种数据结构HashMap,在本篇文章当中主要介绍他的实现原理,下篇我们自己动手实现我们自己的HashMap,让他可以像JDK的HashMap一样工作。
如果有公式渲染不了,可查看这篇内容相同且可渲染公式的文章
HashMap初识
如果你使用过HashMap的话,那你肯定很熟悉HashMap给我们提供了一个非常方便的功能就是键值(key, value)查找。比如我们通过学生的姓名查找分数。
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("学生A", 60);
map.put("学生B", 70);
map.put("学生C", 20);
map.put("学生D", 85);
map.put("学生E", 99);
System.out.println("学生B的分数是:" + map.get("学生B"));
}
我们知道HashMap给我们提供查询get函数功能的时间复杂度为O(1),他在常数级别的时间复杂度就可以查询到结果。那它是如何做到的呢?
我们知道在计算机当中一个最基本也是唯一的,能够实现常数级别的查询的类型就是数组,数组的查询时间复杂度为O(1),我们只需要通过下标就能访问对应的数据。比如我们想访问下标为6的数据,就可以这样:
String[] strs = new String[10];
strs[6] = "一无是处的研究僧";
System.out.println(strs[6]);
因此我们要想实现HashMap给我们提供的O(1)级别查询的时间复杂度的话,就必须使用到数组,而在具体的HashMap实现当中,比如说JDK底层也是采用数组实现的。
HashMap整体设计
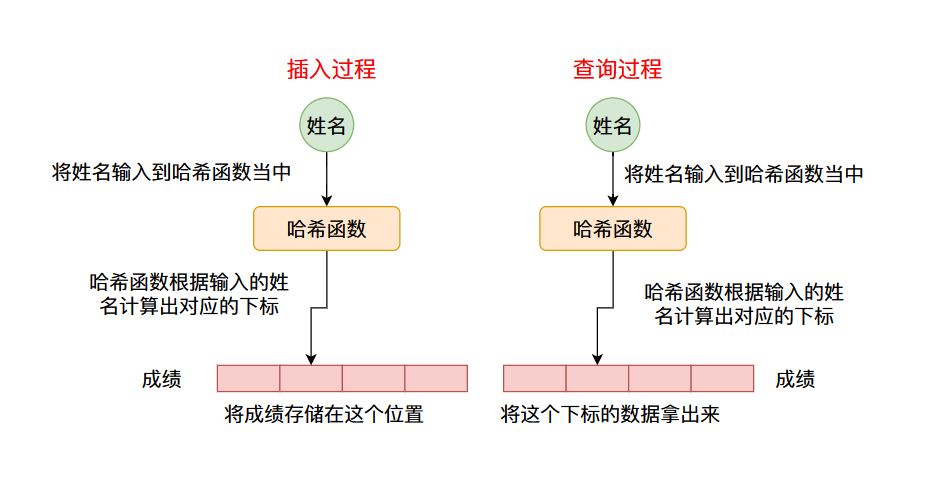
我们实现的HashMap需要满足的最重要的功能是根据键(key)查询到对应的值(value),比如上面提到的根据学生姓名查询成绩。
因此我们可以有一个这样的设计,我们可以根据数据的键值计算出一个数字(像这种可以将一个数据转化成一个数字的叫做哈希函数,计算出来的值叫做哈希值我们后续将会仔细说明),将这个哈希值作为数组的下标,这样的话键值和下标就有了对应关系了,我们可以在数组对应的哈希值为下标的位置存储具体的数据,比如上面谈到的成绩,整个流程如下图所示:
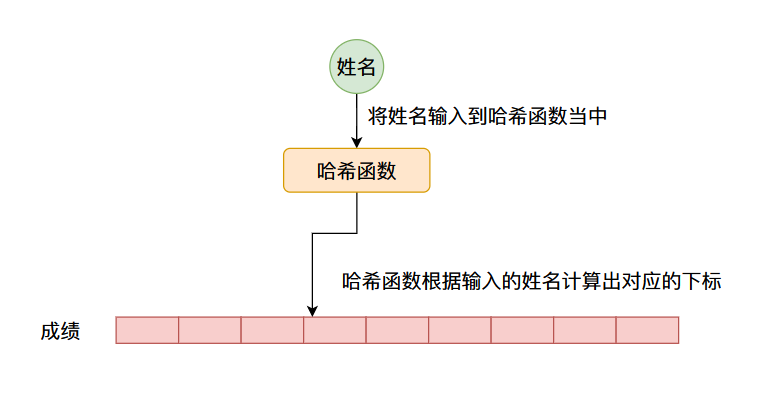
但是像这种哈希函数计算出来的数值一般是没有范围的,因此我们通常通过哈希函数计算出来的数值通常会经过一个求余数操作(%),对数组的长度进行求余数,否则求出来的数值将超过数组的长度。比如数组的长度是16,计算出来的哈希值为186,那么求余数之后的结果为186%16=10,那么我们可以将数据存储在数组当中下标为10的位置,下次我们来取的时候就取出下标为10位置的数据即可。
如何设计一个哈希函数?
首先我们需要了解一个知识,那就是在计算机世界当中我们所含有的两种最基本的数据类型就是,整型(short, int, long)和字符串(String),其他的数据类型可以由这些数据类型组合起来,下面我们来分析一下常见的数据类型的哈希函数设计。
整型的哈希函数
对于整型数据,他本来就是一个数值,因此我们可以直接将这个值返回作为他的哈希值,而JDK中也是这么实现的!JDK中实现整型的哈希函数的方法:
/**
* Returns a hash code for a {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for a {@code int} value.
*/
public static int hashCode(int value) {
return value;
}
字符串的哈希函数
我们知道字符串底层存储的还是用整型数据存储的,比说说字符串hello world,就可以使用字符数组['h', 'e', 'l', 'l', 'o' , 'w', 'o', 'r', 'l', 'd']进行存储,因为我们计算出来的这个哈希值需要尽量不和别的数据计算出来的哈希值冲突(这种现象叫做哈希冲突,我们后面会仔细讨论这个问题),因此我们要尽可能的充分利用字符串里面的每个字符信息。我们来看一下JDK当中是怎么实现字符串的哈希函数的
public int hashCode() {
// hash 是 String 类当中一个私有的 int 变量,主要作用即存储计算出来的哈希值
// 避免哈希值重复计算 节约时间
int h = hash; // 如果是第一次调用 hashCode 这个函数 hash 的值为0,也就是说 h 值为 0
// value 就是存储字符的字符数组
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
// 更新 hash 的值
hash = h;
}
return h;
}
上面的计算hashCode的代码,可以用下面这个公式表示:
- 其中
s,表示存储字符串的字符数组 n表示字符数组当中字符的个数
$$
s[0]31^{(n-1)} + s[1]31^{(n-2)} + ... + s[n-1]
$$
自定义类型的哈希函数
比如我们自己定义了一个学生类,我们改设计他的哈希函数,并且计算他的哈希值呢?
class Student {
String name;
int grade;
}
我们可以根据上面提到的两种哈希函数,仿照他们的设计,设计我们自己的哈希函数,比如像下面这样。
class Student {
String name;
int grade;
// 我们自己要实现的哈希函数
@Override
public int hashCode() {
return name.hashCode() * 31 + grade;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return grade == student.grade &&
Objects.equals(name, student.name);
}
}
事实上JDK也贴心的为我们实现了一个类,去计算我们自定义类的哈希函数。
// 下面这个函数是我们自己设计的类 Student 的哈希函数
@Override
public int hashCode() {
return Objects.hash(name, grade);
}
// 下面这个函数为 Objects.hash 函数
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
// 下面这个函数为 Arrays.hashCode 函数
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
JDK帮助我们实现的哈希函数,本质上就是将类当中所有的字段封装成一个数组,然后像计算字符串的哈希值那样去计算我们自定义类的哈希值。
集合类型的哈希函数
其实集合类型的哈希函数也可以像字符串那样设计哈希函数,我们来看一下JDK内部是如何实现集合类的哈希函数的。
public int hashCode() {
int hashCode = 1;
// 遍历集合当中的对象,进行哈希值的计算
for (E e : this)
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
}
上述代码也可以用之前的公式来表示,其中s[i]表示集合当中第i个数据对象:
$$
s[0]31^{(n-1)} + s[1]31^{(n-2)} + ... + s[n-1]
$$
哈希冲突
因为我们用的最终的数组的下标是通过哈希值取余数得到的,那么就有可能产生冲突。比如说我们的数组长度为10,有两个数据他们的哈希值分别为8和28,他们对10取余之后得到的结果都为8那么改如何解决这个问题呢?
开放地址法(再散列法)
线性探测再散列
假设我们的哈希函数为H,我们的数组长度为m,我们的键为key,那么我计算出来的下标为:
$$
h_i = H(key) % m
$$
当我们有哈希冲突的时候,我们计算下标的方法变为:
$$
h_i = (H(key) + d_i) % m, d_i = i
$$
当我们第一次冲突的时候$d_1 = 1$,如果重新进行计算仍然冲突那么$d_2 = 2$ ......
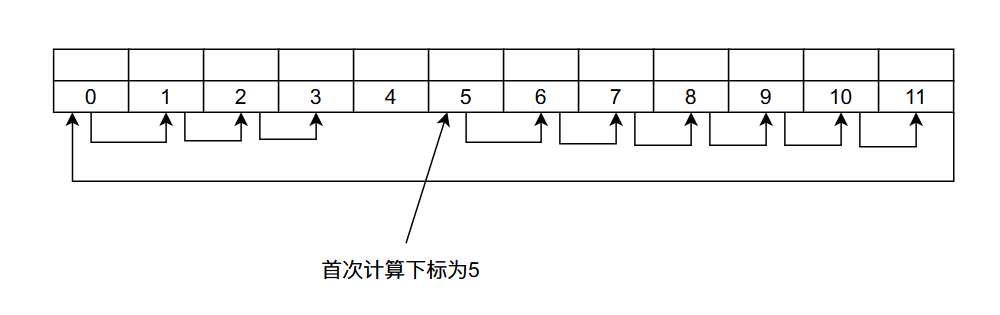
比如在上图当中我们首次计算的哈希值$H(key) = 5$的结果等于5,如果有哈希冲突,那么下次计算出来的哈希值为$(H(key) + 1) % 12 = 6$,如果还是冲突那么计算出来的哈希值为$(H(key) + 2) % 12 = 7$ ......,直到找到一个空位置。谈到这里你可能会问,万一都满了呢?我们在下一小节再谈这个问题。
二次探测再散列
$$
h_i = (H(key) + d_i) % m, d_i = (-1)^{i - 1} i^2
$$
这个散列方法和线性探测散列差不多,只不过$d_i$的值变化情况不一样而已,大家可以参考线性探测进行分析,这个方法可以往数组的两个方法走,因为前面有一个而线性探测只能往数组的一个方向走。此外这个方法走的距离比线性探测更大,因此可能可以在更小的冲突次数当中找到一个空位置。
伪随机数再散列
$$
h_i = (H(key) + d_i) % m, d_i = 一个随机数
$$
这个方式的大致策略和前面差不多,只不过$d_i$上稍微有所差异。
再哈希法
我们可以准备多个哈希函数,当使用一个哈希函数产生冲突的时候,我们可以换一个哈希函数,希望通过不同的哈希函数得到不同的哈希值,以解决哈希冲突的问题。
链地址法
这个方法是目前使用比较多的方法,当产生哈希冲突的时候,数据用一个链表将冲突的数据链接起来,比如像下面这样:
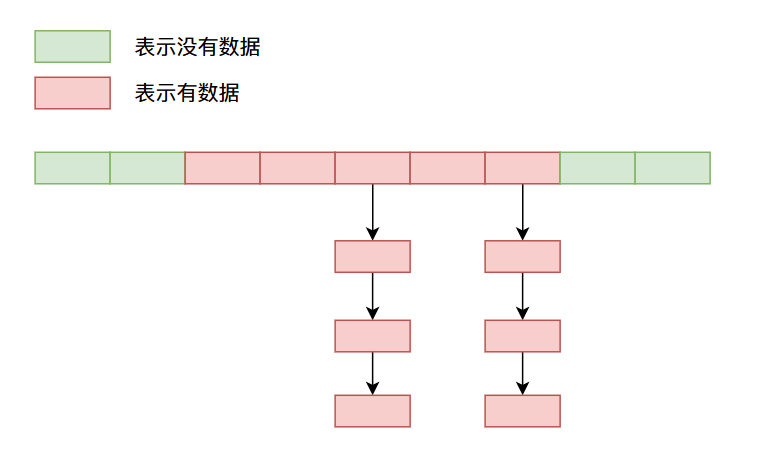
以上就是一些常见的解决哈希冲突的方法,因为都是文字说明没有代码,你可能稍微有些难以理解,比如说我通过上面的方法存储数据,那么我之后怎么拿到我存进去的数据呢?好像放进去就拿不出来了呀!没事儿,这些疑问我们在下篇自己实现哈希表的时候会一一解开,到时候你就发现原来这些算法的设计如此巧妙。
扩容
在上面的文章当中我们并没有谈到当数组满了之后怎么办。很简单嘛,我可以使用一个变量记录数组当中已经使用了的空间,如果全部使用过了,我们就进行扩容,扩大我们的数组就可以了嘛!然后将原数组当中的数据重新进行哈希存放到新数组当中即可!因为我们在计算存储下标的时候需要对数组长度进行取余,而当我们申请新数组的时候数组长度已经发生变化了,因此需要重新对数据进行哈希操作。这里面仍然有很多需要考虑的细节问题,这些问题我们在下篇当中进行代码实现的时候会仔细讨论。
总结
在本篇文章当中,我们主要谈到了如何去设计一个可以使用的哈希表,同时介绍了我们改如何设计一个哈希函数,最终谈到了解决哈希冲突和数组满了的问题!!!
HashMap整体的设计结构。设计一个好的哈希函数。
- 整型数据的哈希函数。
- 字符串的哈希函数。
- 自定义类型的哈希函数。
- 集合的哈希函数。
解决哈希冲突的办法。
- 开放地址法
- 线性探测
- 二次探测
- 随机数探测
- 再哈希法
- 链地址地址法
- 开放地址法
扩容方法
以上就是本篇文章的所有内容了,我们将在下篇当中自己动手实现一个自己的哈希表MyHashMap,这其中还有很多非常细节的设计,其中涉及到很多位运算操作和很多其他非常巧妙的操作。我是LeHung我们下期再见!!!
更多精彩内容合集,可访问:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机知识!!!

自己动手实现 HashMap(Python字典),彻底系统的学习哈希表(上篇)——不看血亏!!!的更多相关文章
- python 字典有序无序及查找效率,hash表
刚学python的时候认为字典是无序,通过多次插入,如di = {}, 多次di['testkey']='testvalue' 这样测试来证明无序的.后来接触到了字典查找效率这个东西,查了一下,原来字 ...
- [转载]关于python字典类型最疯狂的表达方式
一个Python字典表达式谜题 让我们探究一下下面这个晦涩的python字典表达式,以找出在python解释器的中未知的内部到底发生了什么. # 一个python谜题:这是一个秘密 # 这个表达式计算 ...
- Python 字典和集合基于哈希表实现
哈希表作为基础数据结构我不多说,有兴趣的可以百度,或者等我出一篇博客来细谈哈希表.我这里就简单讲讲:哈希表不过就是一个定长数组,元素找位置,遇到哈希冲突则利用 hash 算法解决找另一个位置,如果数组 ...
- python数据结构与算法——哈希表
哈希表 学习笔记 参考翻译自:<复杂性思考> 及对应的online版本:http://greenteapress.com/complexity/html/thinkcomplexity00 ...
- python数据结构之哈希表
哈希表(Hash table) 众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry.这些个键值对(Entry)分散存储在一个数组当中,这个数组就是Has ...
- Python 散列表查询_进入<哈希函数>为结界的世界
1. 前言 哈希表或称为散列表,是一种常见的.使用频率非常高的数据存储方案. 哈希表属于抽象数据结构,需要开发者按哈希表数据结构的存储要求进行 API 定制,对于大部分高级语言而言,都会提供已经实现好 ...
- Python 字典(Dictionary) 基本操作
Python字典是一种可变容器模型,可存储任意类型对象:如字符串.数字.元组等.它以键值对(key-value)的形式存在,因此相当于Hashmap在python中的实现. §1. 创建字典 字典由 ...
- 'dict_values' object does not support indexing, Python字典dict中由value查key
Python字典dict中由value查key 众所周知,字典dict最大的好处就是查找或插入的速度极快,并且不想列表list一样,随着key的增加越来越复杂.但是dict需要占用较大的内存空间,换句 ...
- python django 路由系统
URL配置 基本格式: from django.conf.urls import url urlpatterns = [ url(正则表达式, views ...
随机推荐
- LVM从VG中删除PV及删除未知PV
当我们的硬盘发被删除掉了,我们的PV卷会变成[unknown] 一.首先我们要备份我们的文件,然后再删除lv分区 二. VG中去除PV unknown device:
- 神经网络 CNN 名词解释
隐藏层 不是输入或输出层的所有层都称为隐藏层. 激活和池化都没有权重 使层与操作区分开的原因在于层具有权重.由于池操作和激活功能没有权重,因此我们将它们称为操作,并将其视为已添加到层操作集合中. 例如 ...
- 《Mybatis 手撸专栏》第7章:SQL执行器的定义和实现
作者:小傅哥 博客:https://bugstack.cn - <手写Mybatis系列> 一.前言 为什么,要读框架源码? 因为手里的业务工程代码太拉胯了!通常作为业务研发,所开发出来的 ...
- CRM项目的整理-----第二篇
1.项目的登录 1.1 app创建二级路由 2.登录页面 http://www.jq22.com/
- python二分法、牛顿法求根
二分法求根 思路:对于一个连续函数,左值f(a)*右值f(b)如果<0,那么在这个区间内[a,b]必存在一个c使得f(c)=0 那么思路便是取中间点,分成两段区间,然后对这两段区间分别再比较,跳 ...
- vs code 终端字体间距过大(全角的样子)
文件-首选项-设置 将 terminal.integrated.fontFamily 配置为 Consolas, 'Courier New', monospace 或其他想要的字体,或者点击齿轮按钮重 ...
- Oracle中通过逗号分割字符串并转换成多行
通过逗号对字符串字段进行分割,并返回多行,通过使用regexp_substr()函数实现. SQL示例: select regexp_substr(q.nums, '[^,]+', 1, rownum ...
- 877. Stone Game - LeetCode
Question 877. Stone Game Solution 题目大意: 说有偶数个数字,alex和lee两个人比赛,每次轮流从第一个数字或最后一个数字中拿走一个(偶数个数字,所以他俩拿的数字个 ...
- .NET MAUI 正式发布,再见了 Xamarin.Forms
David Ortinau 在dotnet 团队博客上发表了一篇文章<Introducing .NET MAUI – One Codebase, Many Platforms>,在这篇文章 ...
- 高危!Fastjson反序列化远程代码执行漏洞风险通告,请尽快升级
据国家网络与信息安全信息通报中心监测发现,开源Java开发组件Fastjson存在反序列化远程代码执行漏洞.攻击者可利用上述漏洞实施任意文件写入.服务端请求伪造等攻击行为,造成服务器权限被窃取.敏感信 ...