(数据科学学习手札138)使用sklearnex大幅加速scikit-learn运算
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
大家好我是费老师,scikit-learn作为经典的机器学习框架,从诞生至今已发展了十余年,但其运算速度一直广受用户的诟病。熟悉scikit-learn的朋友应该清楚,scikit-learn中自带的一些基于joblib等库的运算加速功能效果有限,并不能很充分地利用算力。
而今天我要给大家介绍的知识,可以帮助我们在不改变原有代码的基础上,获得数十倍甚至上千倍的scikit-learn运算效率提升,let's go!

2 利用sklearnex加速scikit-learn
为了达到加速运算的效果,我们只需要额外安装sklearnex这个拓展库,就可以帮助我们在拥有intel处理器的设备上,获得大幅度的运算效率提升。
抱着谨慎尝鲜的态度,我们可以在单独的conda虚拟环境中做实验,全部命令如下,我们顺便安装jupyterlab作为IDE:
conda create -n scikit-learn-intelex-demo python=3.8 -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/main -y
conda activate scikit-learn-intelex-demo
pip install scikit-learn scikit-learn-intelex jupyterlab -i https://pypi.douban.com/simple/
完成实验环境的准备后,我们在jupyter lab中编写测试用代码来看看加速效果如何,使用方式很简单,我们只需要在代码中导入scikit-learn相关功能模块之前,运行下列代码即可:
from sklearnex import patch_sklearn, unpatch_sklearn
patch_sklearn()
成功开启加速模式后会打印以下信息:
其他要做的仅仅是将你原本的scikit-learn代码在后面继续执行即可,我在自己平时写作以及开发开源项目的老款拯救者笔记本上简单测试了一下。
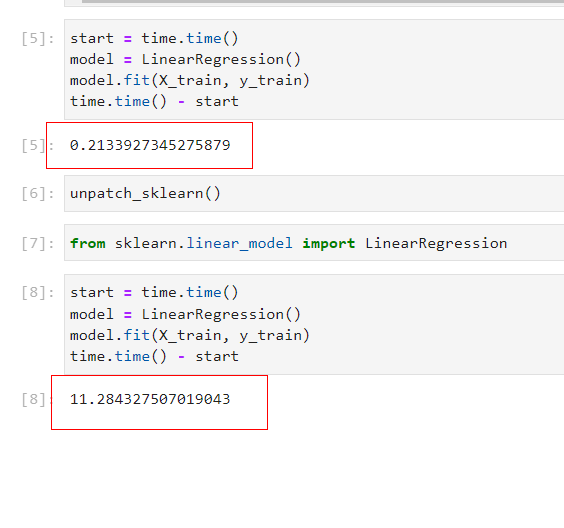
以线性回归为例,在百万级别样本量以及上百个特征的示例数据集上,开启加速后仅耗时0.21秒就完成对训练集的训练,而使用unpatch_sklearn()强制关闭加速模式后(注意scikit-learn相关模块需要重新导入),训练耗时随即上升到11.28秒,意味着通过sklearnex我们获得了50多倍的运算速度提升!
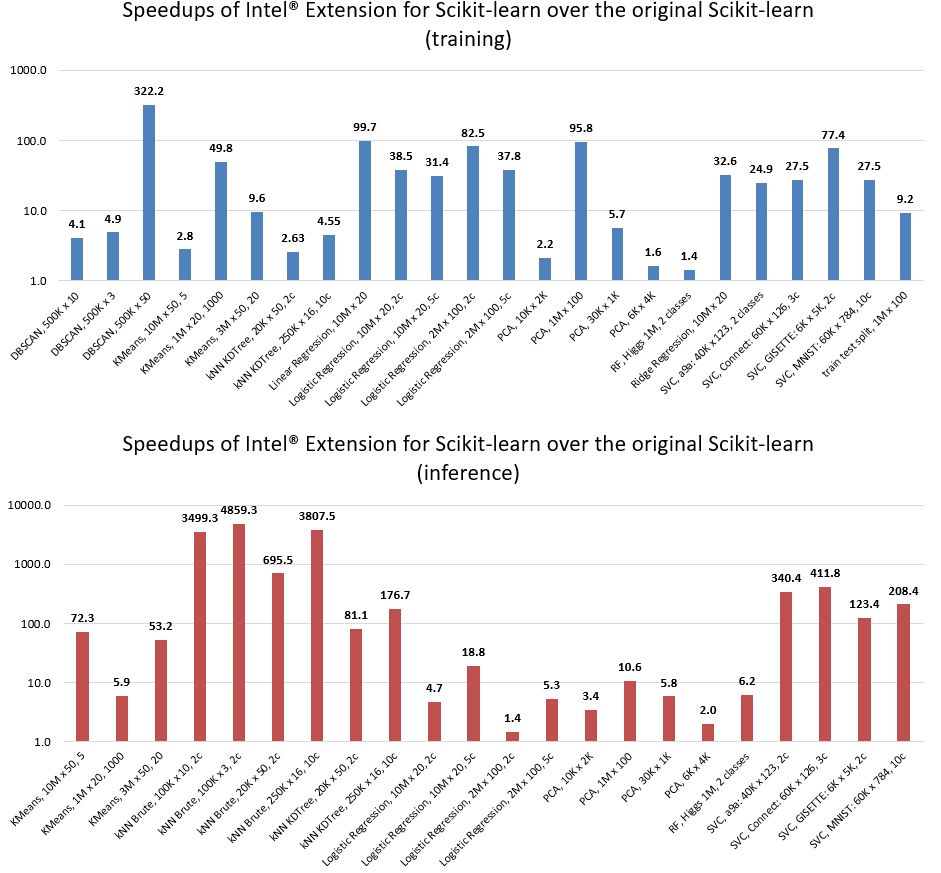
而按照官方的说法,越强劲的CPU可以获得的性能提升比例也会更高,下图是官方在Intel Xeon Platinum 8275CL处理器下测试了一系列算法后得出的性能提升结果,不仅可以提升训练速度,还可以提升模型推理预测速度,在某些场景下甚至达到数千倍的性能提升:
官方也提供了一些ipynb示例(https://github.com/intel/scikit-learn-intelex/tree/master/examples/notebooks),展示了包含K-means、DBSCAN、随机森林、逻辑回归、岭回归等多种常用算法示例,感兴趣的读者朋友们可以自行下载学习。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札138)使用sklearnex大幅加速scikit-learn运算的更多相关文章
- (数据科学学习手札86)全平台支持的pandas运算加速神器
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 随着其功能的不断优化与扩充,pandas已然成为 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
随机推荐
- python函数基础算法简介
一.多层语法糖本质 """ 语法糖会将紧挨着的被装饰对象名字当参数自动传入装饰器函数中""" def outter(func_name): ...
- (十一)React Ant Design Pro + .Net5 WebApi:后端环境搭建-IdentityServer4(三)持久化
一.前言 IdentityServer配合EFCore持久化,框架已经为我们准备了两个上下文: ConfigurationDbContext:配置数据(资源.客户端.身份等) PersistedGra ...
- 企业级 Web 开发的挑战
本文翻译自土牛Halil ibrahim Kalkan的<Mastering ABP Framework>,是系列翻译的起头,适合ABP开发人员或者想对ABP框架进行深入演进的准架构师. ...
- JVM垃圾回收篇
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 基础概念 GC=jvm垃圾回收,垃圾回收机制是由垃圾回收器Garbage ...
- .NET MAUI RC2 发布,支持 Tizen 平台
在.NET多平台应用程序UI(.NET MAUI)RC1之后仅两周,微软已经发布了RC2,并以新的Tizen支持为亮点..NET MAUI是微软对Xamarin.Forms的演变,因为它除了iOS和A ...
- systemd进程管理工具实战教程
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 1. systemd介绍 systemd是目前Linux系统上主要的系统守护进程管理工具,由于 ...
- 用 Docker 快速搭建 Kafka 集群
开源Linux 一个执着于技术的公众号 版本 •JDK 14•Zookeeper•Kafka 安装 Zookeeper 和 Kafka Kafka 依赖 Zookeeper,所以我们需要在安装 Kaf ...
- drools session理解
一.理解 在drools中存在2种session,一种是有状态的Session (Stateful Session),另外一种一种是无状态的Session (Stateless Session). 1 ...
- 羽夏 Bash 简明教程(下)
写在前面 该文章根据 the unix workbench 中的 Bash Programming 进行汉化处理并作出自己的整理,并参考 Bash 脚本教程 和 BashPitfalls 相关内容 ...
- 零基础学Java第四节(字符串相关类)
本篇文章是<零基础学Java>专栏的第四篇文章,文章采用通俗易懂的文字.图示及代码实战,从零基础开始带大家走上高薪之路! String 本文章首发于公众号[编程攻略] 在Java中,我们经 ...