Similarity calculation
推荐算法入门(相似度计算方法大全)
一、协同过滤算法简介
在推荐系统的众多方法之中,基于用户的协同过滤是诞最早的,原理也比较简单。基于协同过滤的推荐算法被广泛的运用在推荐系统中,比如影视推荐、猜你喜欢等、邮件过滤等。该算法1992年提出并用于邮件过滤系统,两年后1994年被 GroupLens 用于新闻过滤。一直到2000年,该算法都是推荐系统领域最著名的算法。
当用户A需要个性化推荐的时候,可以先找到和他兴趣详细的用户集群G,然后把G喜欢的并且A没有的物品推荐给A,这就是基于用户的协同过滤。
根据上述原理,我们可以将算法分为两个步骤:
找到与目标兴趣相似的用户集群
找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户。
二、常用的相似度计算方法
下面,简单的举例几个机器学习中常用的样本相似性度量方法:
- 欧式距离(Euclidean Distance)
- 余弦相似度(Cosine)
- 皮尔逊相关系数(Pearson)
- 修正余弦相似度(Adjusted Cosine)
- 汉明距离(Hamming Distance)
- 曼哈顿距离(Manhattan Distance)
欧式距离(Euclidean Distance)
欧式距离全称是欧几里距离,是最易于理解的一种距离计算方式,源自欧式空间中两点间的距离公式。
- 平面空间内的
与
间的欧式距离:
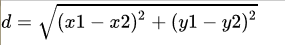
- 三维空间里的欧式距离:
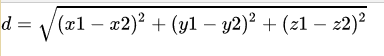
- Python 代码简单实现:
def EuclideanDistance(x,y):
d = 0
for a,b in zip(x,y):
d += (a-b)**2
return d**0.5
- 使用 numpy 简化:
import numpy as np
def EuclideanDistance(dataA,dataB):
# np.linalg.norm 用于范数计算,默认是二范数,相当于平方和开根号
return 1.0/(1.0 + np.linalg.norm(dataA - dataB))
余弦相似度(Cosine)
首先,样本数据的夹角余弦并不是真正几何意义上的夹角余弦,只不过是借了它的名字,实际是借用了它的概念变成了是代数意义上的“夹角余弦”,用来衡量样本向量间的差异。
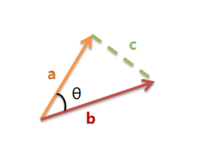
夹角越小,余弦值越接近于1,反之则趋于-1。我们假设有x1与x2两个向量:
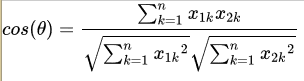
- Python 代码的简单按公式还原:
def Cosine(x,y):
sum_xy = 0.0;
normX = 0.0;
normY = 0.0;
for a,b in zip(x,y):
sum_xy += a*b
normX += a**2
normY += b**2
if normX == 0.0 or normY == 0.0:
return None
else:
return sum_xy / ((normX*normY)**0.5)
- 使用 numpy 简化夹角余弦
def Cosine(dataA,dataB):
sumData = dataA *dataB.T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA) * np.linalg.norm(dataB)
# 归一化
return 0.5 + 0.5 * (sumData / denom)
我们引入一组特殊数据进行测试:
dataA = np.mat([1,2,3,3,2,1])
dataB = np.mat([2,3,4,4,3,2])
print(EuclideanDistance(dataA,dataB)) # 0.28
print(Cosine(dataA,dataB)) # 0.99
欧式距离和夹角余弦的区别:
对比以上的结果的 dataA 与 dataB 这两组数据,会发现 dataA 与 dataB 的欧式距离相似度比较小,而夹角余弦相似度比较大,即夹角余弦更能反映两者之间的变动趋势,两者有很高的变化趋势相似度,而欧式距离较大是因为两者数值有很大的区别,即两者拥有很高的数值差异。
皮尔逊相关系数(Pearson Correlation Coefficient)
假如之不先介绍夹角余弦的话,第一次接触你绝对会对皮尔逊相关系数一脸懵逼。那么现在,让我们再来理解一下皮尔逊相关系数的公式:
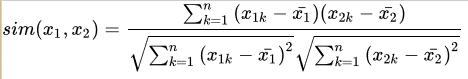
* 这里减去的 每个item被打分的均值
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。从知友的回答可以明白,皮尔逊相关函数是余弦相似度在维度缺失上面的一种改进方法。
- Python 代码实现皮尔逊相关系数:
def Pearson(x,y):
sum_XY = 0.0
sum_X = 0.0
sum_Y = 0.0
normX = 0.0
normY = 0.0
count = 0
for a,b in zip(x,y):
count += 1
sum_XY += a * b
sum_X += a
sum_Y += b
normX += a**2
normY += b**2
if count == 0:
return 0
# denominator part
denominator = (normX - sum_X**2 / count)**0.5 * (normY - sum_Y**2 / count)**0.5
if denominator == 0:
return 0
return (sum_XY - (sum_X * sum_Y) / count) / denominator
- numpy 简化实现皮尔逊相关系数
def Pearson(dataA,dataB):
# 皮尔逊相关系数的取值范围(-1 ~ 1),0.5 + 0.5 * result 归一化(0 ~ 1)
return 0.5 + 0.5 * np.corrcoef(dataA,dataB,rowvar = 0)[0][1]
用余弦相似度相同的方法实现皮尔逊:
# 余弦相似度、修正余弦相似度、皮尔逊相关系数的关系
# Pearson 减去的是每个item i 的被打分的均值
def Pearson(dataA,dataB):
avgA = np.mean(dataA)
avgB = np.mean(dataB)
sumData = (dataA - avgA) * (dataB - avgB).T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA - avgA) * np.linalg.norm(dataB - avgB)
# 归一化
return 0.5 + 0.5 * (sumData / denom)
修正余弦相似度
- 为什么需要在余弦相似度的基础上使用修正余弦相似度
X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性
# 修正余弦相似度
# 修正cosine 减去的是对item i打过分的每个user u,其打分的均值
data = np.mat([[1,2,3],[3,4,5]])
avg = np.mean(data[:,0]) # 下标0表示正在打分的用户
def AdjustedCosine(dataA,dataB,avg):
sumData = (dataA - avg) * (dataB - avg).T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA - avg) * np.linalg.norm(dataB - avg)
return 0.5 + 0.5 * (sumData / denom)
print(AdjustedCosine(data[0,:],data[1,:],avg))
汉明距离(Hamming distance)
汉明距离表示的是两个字符串(相同长度)对应位不同的数量。比如有两个等长的字符串 str1 = "11111" 和 str2 = "10001" 那么它们之间的汉明距离就是3(这样说就简单多了吧。哈哈)。汉明距离多用于图像像素的匹配(同图搜索)。
1.Python 的矩阵汉明距离简单运用:
def hammingDistance(dataA,dataB):
distanceArr = dataA - dataB
return np.sum(distanceArr == 0)# 若列为向量则为 shape[0]
曼哈顿距离(Manhattan Distance)
没错,你也是会曼哈顿计量法的人了,现在开始你和秦风只差一张刘昊然的脸了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,那么驾驶的最近距离并不是直线距离,因为你不可能横穿房屋。所以,曼哈顿距离表示的就是你的实际驾驶距离,即两个点在标准坐标系上的绝对轴距总和。
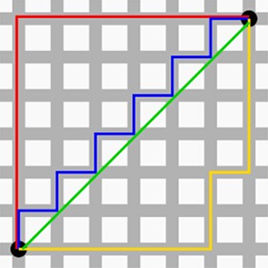
# 曼哈顿距离(Manhattan Distance)
def Manhattan(dataA,dataB):
return np.sum(np.abs(dataA - dataB))
print(Manhattan(dataA,dataB))
本文转自--->:https://zhuanlan.zhihu.com/p/33164335
(如有侵权,联系删除)
Similarity calculation的更多相关文章
- NLTK vs SKLearn vs Gensim vs TextBlob vs spaCy
Generally, NLTK is used primarily for general NLP tasks (tokenization, POS tagging, parsing, etc.) S ...
- OpenCASCADE Curve Length Calculation
OpenCASCADE Curve Length Calculation eryar@163.com Abstract. The natural parametric equations of a c ...
- 机器学习中的相似性度量(Similarity Measurement)
机器学习中的相似性度量(Similarity Measurement) 在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间 ...
- cosine similarity
Cosine similarity is a measure of similarity between two non zero vectors of an inner product space ...
- [SimHash] find the percentage of similarity between two given data
SimHash algorithm, introduced by Charikarand is patented by Google. Simhash 5 steps: Tokenize, Hash, ...
- 自定义评分器Similarity,提高搜索体验(转)
文章转自:http://blog.csdn.net/duck_genuine/article/details/6257540 首先说一下lucene对文档的评分规则: score(q,d) = ...
- jaccard similarity coefficient 相似度计算
Jaccard index From Wikipedia, the free encyclopedia The Jaccard index, also known as the Jaccard ...
- hdu4965 Fast Matrix Calculation (矩阵快速幂 结合律
http://acm.hdu.edu.cn/showproblem.php?pid=4965 2014 Multi-University Training Contest 9 1006 Fast Ma ...
- 1063. Set Similarity (25)
1063. Set Similarity (25) 时间限制 300 ms 内存限制 32000 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given ...
随机推荐
- Message: 'geckodriver' executable needs to be in PATH
1.下载geckodriver.exe:下载地址:mozilla/geckodriver请根据系统版本选择下载:(如Windows 64位系统) 2.下载解压后将getckodriver.exe复制到 ...
- SpringMVC异常(404,接收参数类型转换错误)
内容 一.异常信息 HTTP Status 400 - type Status report message description The request sent by the client wa ...
- maven导入依赖了提示can't resolved
maven导入依赖显红报错 网上有很多解决方案,我试过几个但是都不是很好用,推荐一个我自己一直在用的解决方案 在终端执行命令 mvn idea:idea 无法解析的原因基本上是因为包没下载完整,执行这 ...
- Python入门-异常处理
异常处理 #try----else---- 会一起执行 #finally无论如何,最后都会执行 def main(): try: res = 10/2 print("开始执行计算:" ...
- Python入门-初识变量类型
上一篇我们学习了第一行代码,我们print()了很多代码,我们可以print哪些东西呢,这一篇来讲. print()括号里面可以放哪些东西呢?..可以放很多东西,只要是Python的全部数据类型都可以 ...
- nginx服务优化大全
第18章 nginx服务优化 18.1 复习以前的nginx知识 18.1.1 复习nginx编译安装的3部曲 ./configure 配置(开启/关闭功能),指定安装目录 make ...
- JavaWeb和WebGIS学习笔记(七)——MapGuide Open Source安装、配置以及MapGuide Maestro发布地图——超详细!目前最保姆级的MapGuide上手指南!
JavaWeb和WebGIS学习笔记(七)--MapGuide Open Source安装.配置以及MapGuide Maestro发布地图 超详细!目前最保姆级的MapGuide上手指南! 系列链接 ...
- Python 一网打尽<排序算法>之堆排序算法中的树
本文从树数据结构说到二叉堆数据结构,再使用二叉堆的有序性对无序数列排序. 1. 树 树是最基本的数据结构,可以用树映射现实世界中一对多的群体关系.如公司的组织结构.网页中标签之间的关系.操作系统中文件 ...
- Python工程打包
Python项目打包 我是自己写了一个项目,然后需要打包成问一个exe文件,这样直接打开这个文件就可以运行,而不需要在pycharm中打开相应文件才能运行,也可以将打包好的文件发给其他人,不需要pyc ...
- Vue3 setup详解
setup执行的时机 在beforeCreate之前执行(一次),此时组件对象还没创建: this是undefined,不能通过this来访问data/computed/methods/props: ...