flink-cdc同步mysql数据到kafka
本文首发于我的个人博客网站 等待下一个秋-Flink
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1. 环境准备
mysql
kafka 2.3
flink 1.13.5 on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
如果你的Flink是其它版本,可以来这里下载。
这里flink-sql-connector-mysql-cdc,前面一篇文章我用的mysq-cdc是1.4的,当时是可以的,但是今天我发现需要mysql-cdc-1.3.0了,否则,整合connector-kafka会有来冲突,目前mysql-cdc-1.3适用性更强,都可以兼容的。
如果你是更高版本的flink,可以自行https://github.com/ververica/flink-cdc-connectors下载新版mvn clean install -DskipTests 自己编译。
这是我编译的最新版2.2,传上去发现太新了,如果重新换个版本,我得去gitee下载源码,不然github速度太慢了,然后用IDEA编译打包,又得下载一堆依赖。我投降,我直接去网上下载了个1.3的直接用了。
我下载的jar包,放在flink的lib目录下面:
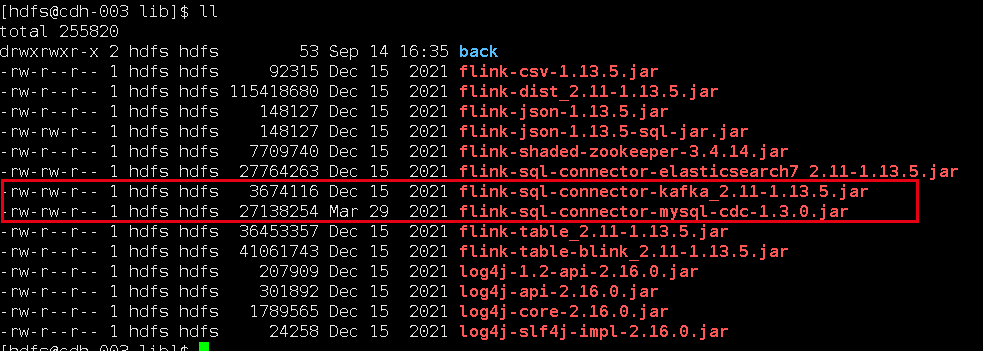
flink-sql-connector-kafka_2.11-1.13.5.jar
flink-sql-connector-mysql-cdc-1.3.0.jar
3. 启动flink-sql client
- 先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-kafka
- 进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc-kafka

4. 同步数据
这里有一张mysql表:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 样本数据
INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');
INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');
INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
- 创建数据表关联mysql
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.2',
'port' = '3306',
'username' = 'bigdata',
'password' = 'bigdata',
'database-name' = 'test',
'table-name' = 'product_view'
);
这样,我们在flink sql client操作这个表相当于操作mysql里面的对应表。
- 创建数据表关联kafka
CREATE TABLE product_view_kafka_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = '192.168.1.2:9092',
'properties.group.id' = 'flink-cdc-kafka-group',
'key.format' = 'json',
'value.format' = 'json'
);
这样,kafka里面的flink-cdc-kafka这个主题会被自动创建,如果想指定一些属性,可以提前手动创建好主题,我们操作表product_view_kafka_sink,往里面插入数据,可以发现kafka中已经有数据了。
- 同步数据

建立同步任务,可以使用sql如下:
insert into product_view_kafka_sink select * from product_view_source;
这个时候是可以退出flink sql-client的,然后进入flink web-ui,可以看到mysql表数据已经同步到kafka中了,对mysql进行插入,kafka都是同步更新的。
通过kafka控制台消费,可以看到数据已经从mysql同步到kafka了:

参考资料
https://ververica.github.io/flink-cdc-connectors/master/content/about.html
flink-cdc同步mysql数据到kafka的更多相关文章
- 使用maxwell实时同步mysql数据到kafka
一.软件环境: 操作系统:CentOS release 6.5 (Final) java版本: jdk1.8 zookeeper版本: zookeeper-3.4.11 kafka 版本: kafka ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
随机推荐
- bat实现删除BCUnrar.dll实现无限使用
删除项目:计算机\HKEY_CURRENT_USER\Software\Scooter Software\Beyond Compare 4下的CacheId 项可以实现Beyond Compare 4 ...
- Linux 磁盘挂载和swap空间管理
挂载:把指定的设备和根下面的某个文件夹建立关联 卸载:解除两者关系的过程 挂载文件系统:mount 格式:mount device mountpoint --- mount 设备名 挂载点 mount ...
- charles(CA证书)的app端安装
在使用charles进行的app抓包的时候势必需要对他进行配置: 1. pc端: 第一步: http请求接收charles > proxy > proxy setting > por ...
- 编写可维护的webpack配置
为什么要构建配置抽离成npm包 通用性 业务开发者无需挂住配置 统一团队构建脚本 可维护性 构建配置合理的拆分 README文档, chan 构建配置管理的可选方案 通过多个配置管理不同环境的构建, ...
- NIO.2中Path、 Paths、Files类的使用
- MySQL--创建计算字段
存储在数据库表中的数据一般不是应用程序所需要的格式.下面举几个例子. 如果想在一个字段中既显示公司名,又显示公司的地址,但这两个信息一般包含在不同的表列中. 城市.州和邮政编码存储在不同的列中 ...
- esp8266模拟输入(ADC)检测问题
今天使用esp12f读取A0数据时一直出现错误; Serial.println(analogRead(A0));读取值一直为1024 因为前段时间一直用的是开发板,读取电压值正常 而从昨天换为了esp ...
- python3学习笔记之字符串
字符串 1.一个个字符组成的有序的序列,是字符的集合: 2.使用单引号.双引号.三引号引住的字符序列 3.字符串是不可变对象 4.python3起,字符串就是Unicode类型: 字符串特殊举例: 不 ...
- WPF 截图控件之绘制方框与椭圆(四) 「仿微信」
前言 接着上周写的截图控件继续更新 绘制方框与椭圆. 1.WPF实现截屏「仿微信」 2.WPF 实现截屏控件之移动(二)「仿微信」 3.WPF 截图控件之伸缩(三) 「仿微信」 正文 有开发者在B站反 ...
- MMDetection 使用示例:从入门到出门
前言 最近对目标识别感兴趣,想做一些有趣目标识别项目自己玩耍,本来选择的是 YOLOV5 的,但无奈自己使用 YOLOV5 环境训练模型时,不管训练多少次 mAP 指标总是为 0,而其它 pytorc ...