动手实验查看MySQL索引的B+树的高度
一:文中几个概念
h:统称索引的高度;
h1:主键索引的高度;
h2:辅助索引的高度;
k:非叶子节点扇区个数。
二:索引结构
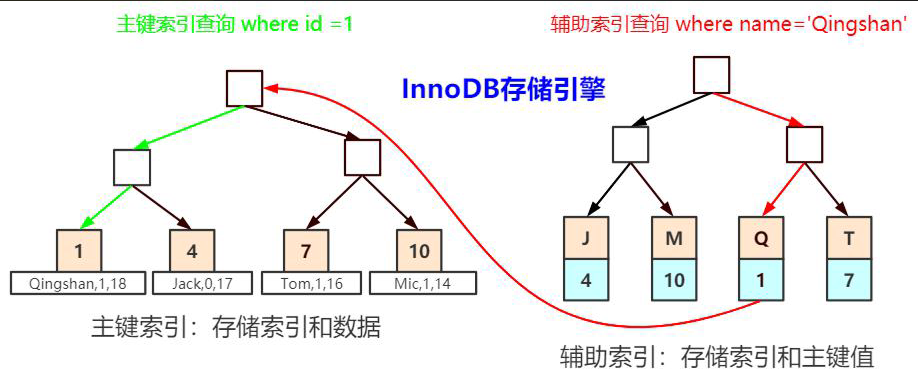
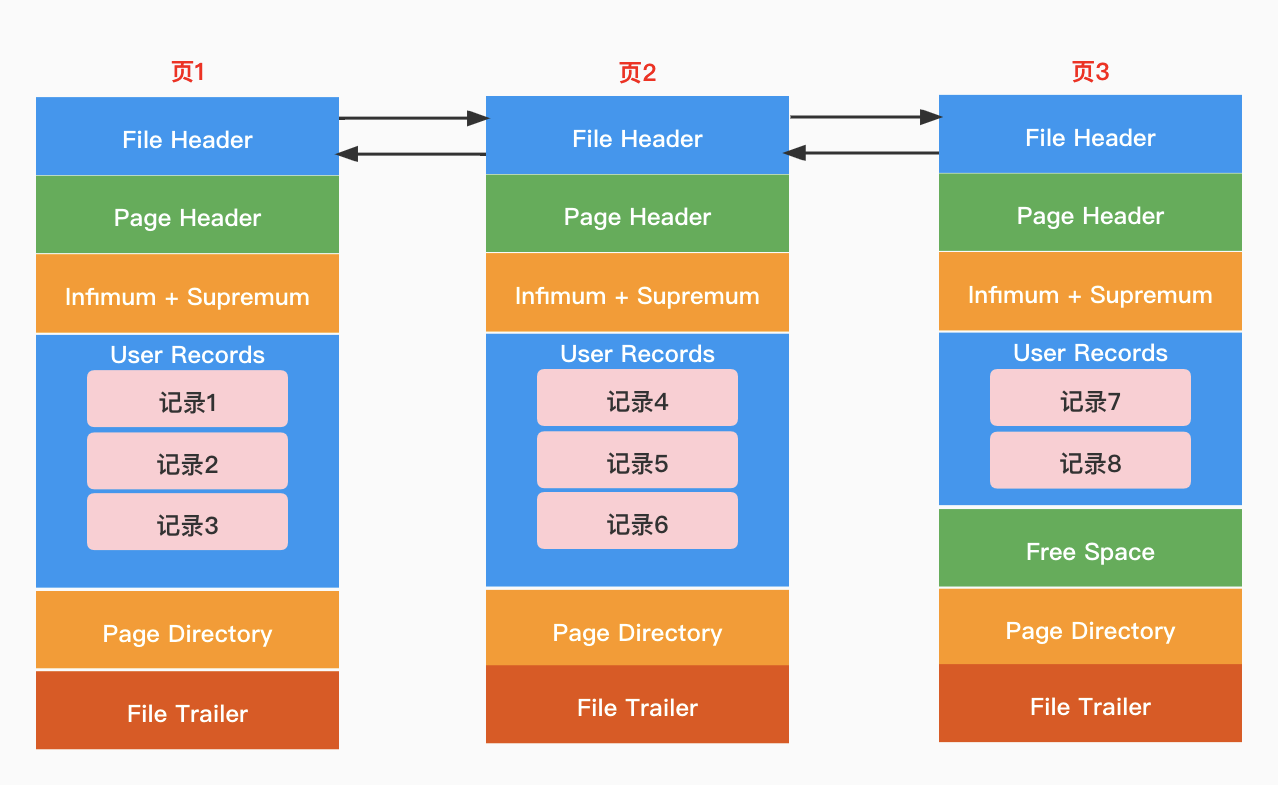
叶子节点其实是双向链表,而叶子节点内的行数据是单向链表,该图未体现。
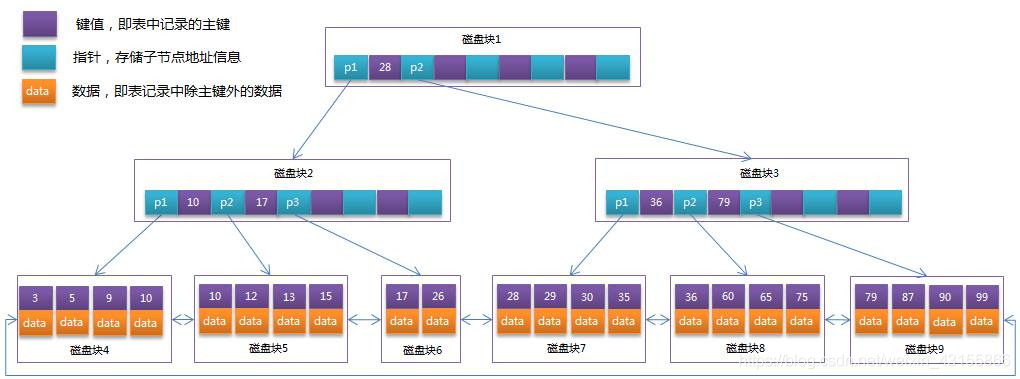
磁盘块其实是页,用操作系统中的术语来表达而已。
InnoDB中使用的是B+树聚集索引,主键索引叶子节点有整行的数据,辅助索引有主键值(用于回表查询)和索引值。
2.1 页的概念
Mysql的InnoDB是以页为存储单位的,每个B+Tree的节点都是一个页的大小,默认一页的大小是16K(与操作系统数据读取相关)。
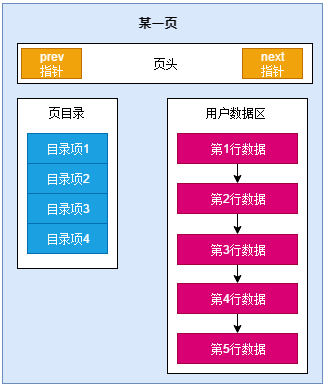
数据页(即叶子节点)
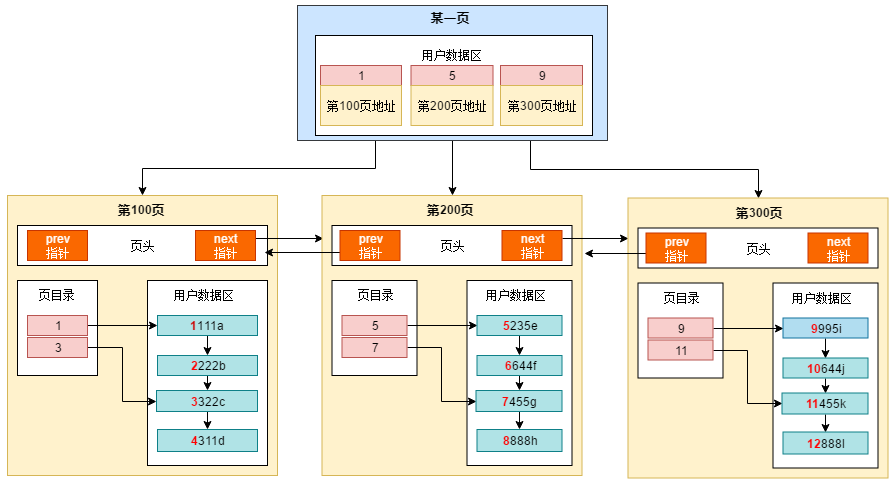
2.2 索引高度h与页面I/O数的关系
每次查询都要访问到叶子结点,其访问的页面数正好就是索引的高度h。例如,一次主键上的点查询SELECT * FROM USER WHERE id=1,那么要查询h1个页面才能找到叶子结点里的行数据,也即进行h1次页面I/O。(另外,二级索引基本都加载在内存里了,这里我们暂忽略这种情况。)
综上,查询对应的页面I/O数跟利用的索引有关,主要分为以下几种情况:
- 点查询:
- 聚族索引:h1
- 二级索引:
- 覆盖索引:h2
- 回表查询:h2+h1
- 范围查询:这种情况相对比较复杂,但跟点查询的原理类似,读者可自行分析;
- 全表查询:B+树的叶子结点是通过链表连接起来的,对于全表查询,需要从头到尾将所有的叶子结点访问一遍。
2.3 索引高度理论计算
索引页(非叶子节点)中可以分割为多个扇区,每个扇区再指向某子节点(某页)。
假设非叶子节点扇区数为k个、高度h、叶子结点的行记录数为n,则叶子结点数为k(h-1),总记录数为k(h-1)*n。
InnoDB每个页面默认16KB,假设主键是4B的int类型。对于非叶子节点,每个主键值后有个页号4B,还有6B的其他数据(参考《MySQL技术内幕:InnoDB存储引擎》),那么扇区个数k=16KB/(4B+4B+6B)≈1170。
假设每行记录大小为1KB,则每个叶子结点可以容纳的记录数n=16KB/1KB=16。
在高度h=3时,叶子结点数=1170^2 ≈137W,总记录数=1170^2*16=2190W!!也就是说,InnoDB通过三次索引页面的I/O,即可索引2190W行记录。
同理,在高度h=4时,总行数=1170^3*16≈256亿条!
三、动手查看索引真实高度
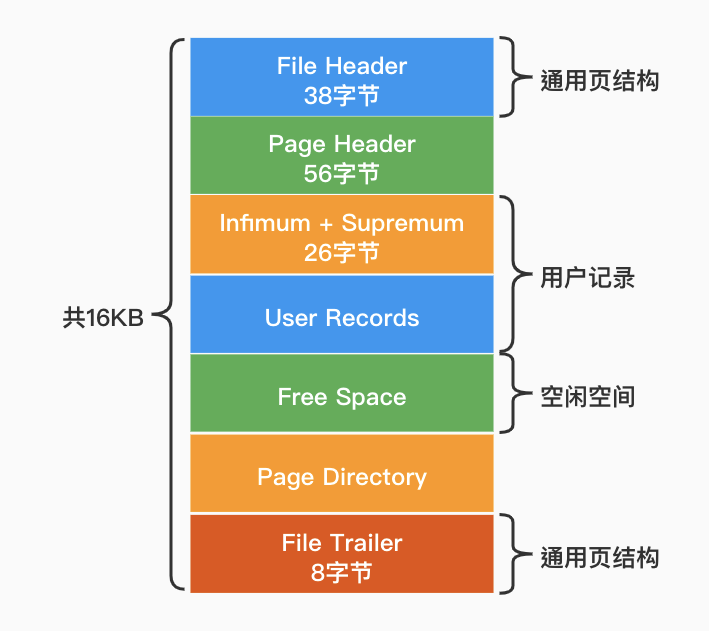
页的Page Header包含一个PAGE_LEVEL的信息,用于表示当前页所在索引中的高度。默认叶子节点的高度为0,那么Root页(根节点)的PAGE_LEVEL+1就是这棵索引的高度。
**怎样得到一张含有所有索引的Root页所在的位置的表呢?在《MySQL技术内幕:InnoDB存储引擎》书中分析过这个页(即ibd文件的第3个页面,从0开始)是聚簇索引的Root页,在《MySQL内核:InnoDB存储引擎 卷1》中也分析,Root页的位置通常是不会更改的。那么其他索引的Root页所在的位置呢?通过下面的SQL语句可以查出表中各索引的Root页信息:
SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO
FROM information_schema.INNODB_SYS_INDEXES a,
information_schema.INNODB_SYS_TABLES b
WHERE a.table_id = b.table_id
AND a.space <> 0;
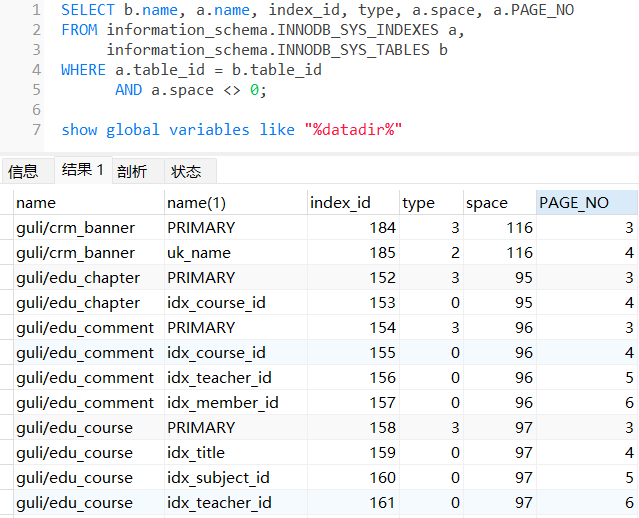
其中就是索引的Root页信息,SPACE可以认为是表的ibd文件,PAGE_NO代表ibd文件中的页面号(从0开始)。有了这些信息就可以方便的定位了,因为PAGE_LEVEL在每个Root页的偏移量64位置处,占用两个字节,这样我们通过hexdump(show global variables like "%datadir%"可以查看MySQL数据文件位置)就可以快速定位到各索引树的高度信息了。例如,我们通过如下命令查看**guli/edu_comment**表主键索引的高度:
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 01 00 00 00 00 00 00 00 9a |..........|
0000c04a
这里,49216表示的是16384*3+64,即从第3个页内偏移量64位置开始读取10个字节,前两个字节为PAGE_LEVEL,后8个字节是index_id,就是上图中看到的index_id=154(0x9a(十六进制) = 154(十进制))的主键索引,这里PAGE_LEVEL为00 01,那么索引树的高度就为2。
四、插入10w条数据查看索引的高度
delimiter;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
INSERT INTO `guli`.`edu_comment` (`id`, `course_id`, `teacher_id`,
`member_id`, `nickname`, `avatar`, `content`, `is_deleted`,
`gmt_create`, `gmt_modified`)
VALUES (i, '1192252213659774977', '1189389726308478977', '1', '小三123',
'ht', '课程很好', 0, '2019-11-13 14:16:08', '2019-11-13 14:16:08');
set i=i+1;
end while;
end;;
delimiter;
经过1分多钟的插入,edu_comment表中的数据已经达到了10w条,再次查看主键索引的高度。
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 02 00 00 00 00 00 00 00 9a |..........|
0000c04a
可以看到主键索引的高度来到了3层,由于服务器硬盘容量较小,插入了1900w条数据。主键索引在数据量达到3w左右会从2层高度上升到3层(辅助索引会在数据量为数万到数十万时上升到3层高度,因为仅含主键值和索引值,没有整行数据)。根据网上资料,数据量在2000w左右时,树的高度会达到4层,数据库性能下降较为明显,2000w分库分表的由来。
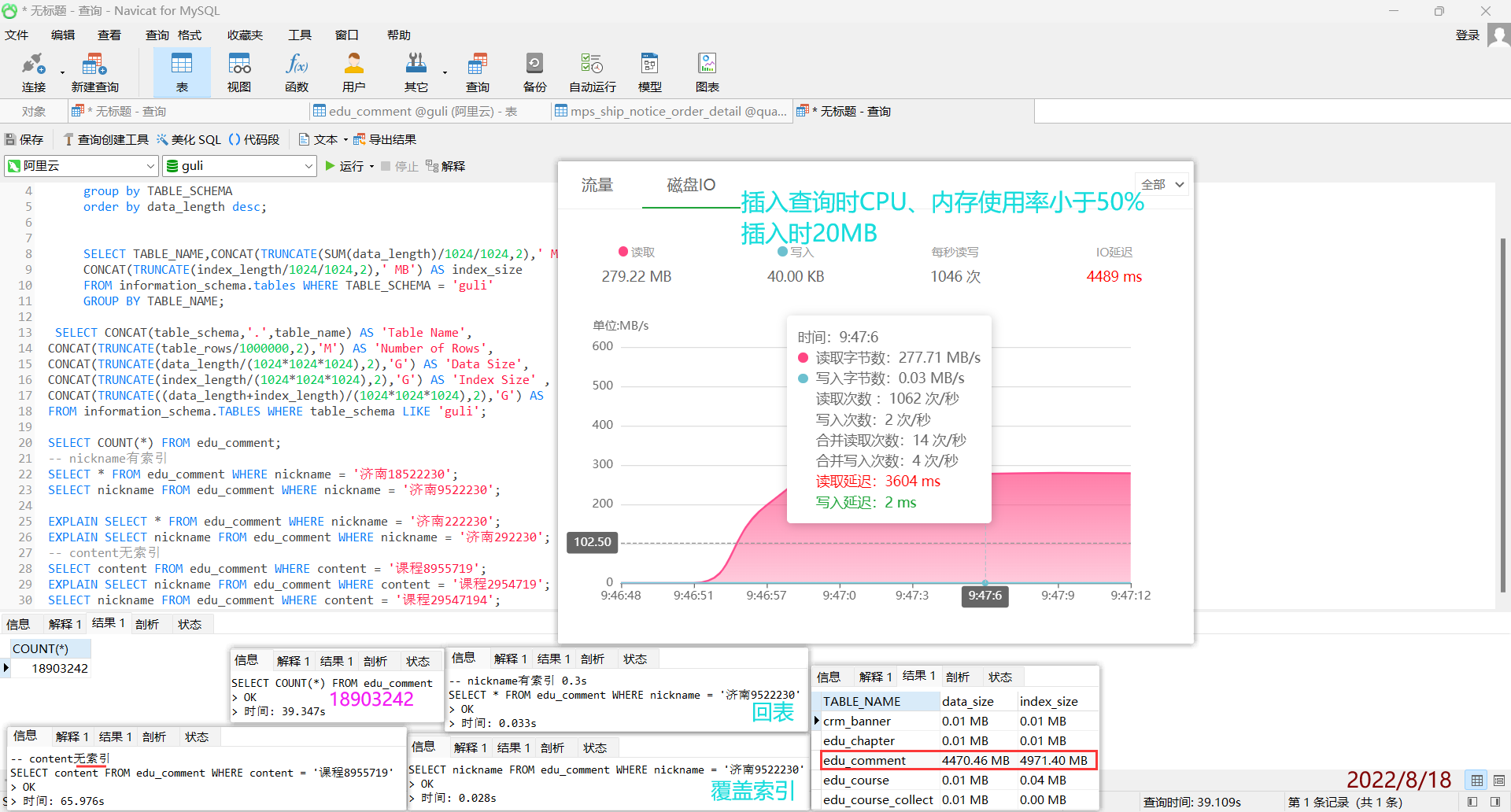
$hexdump -C -s 49216 -n 10 edu_comment.ibd
0000c040 00 03 00 00 00 00 00 00 00 9a |..........|
0000c04a
主键索引高度来到了4层,主键类型为char(19)。
索引高度h也跟索引字段的数据类型有关。如果是int或short,扇区多,索引效率更好,整个索引看起来属于“矮胖”型;而如果是varchar(32)等,那扇区少,整个索引看起来属于“瘦高”型,索引效率自然要低些。所以我们在字段选取类型时,其类型越简单效率越好。
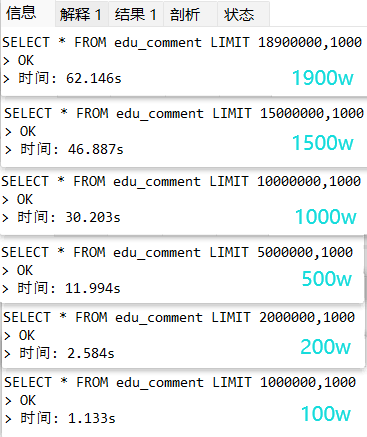
分页查询效率:
参考资料:
[1]MySQL索引的B+树到底有多高?
https://mp.weixin.qq.com/s/VmgpA3fZlv0JxERYB2tt5g
[2]面试官:MYSQL单表数据达2000万性能严重下降,为什么?
https://mp.weixin.qq.com/s/7_Wv3wZX5sOxF17iSM436A
[3]一文搞懂MySQL索引页结构
http://www.cppcns.com/shujuku/mysql/463625.html
[4]再有人问你为什么MySQL用B+树做索引,就把这篇文章发给她
https://mp.weixin.qq.com/s/8nx4yLOg542p_fmqjKDrKw
[5]http://blog.codinglabs.org/articles/theory-of-mysql-index.html
动手实验查看MySQL索引的B+树的高度的更多相关文章
- 为什么MySQL索引使用B+树
为什么MySQL索引使用B+树 聚簇索引与非聚簇索引 不同的存储引擎,数据文件和索引文件位置是不同的,但是都是在磁盘上而不是内存上,根据索引文件.数据文件是否放在一起而有了分类: 聚簇索引:数据文件和 ...
- MySQL索引之B+树
MySQL索引大都存储在B+树中,除此还有R树和hash索引.B+树的基础还是B树. B树由2部分组成,节点和索引.下面将构建一个B树,每个节点存2个数据,每个节点有前,中,后三个索引.插入数字的顺序 ...
- 如何查看mysql索引
show index from tableName; show keys from tableName; · Table表的名称.· Non_unique如果MySQL索引不能包括重复词,则为0.如果 ...
- mysql在innodb索引下b+树的高度问题。
B+树索引介绍 B+树索引的本质是B+树在数据库中的实现.但是B+树索引有一个特点是高扇出性,因此在数据库中,B+树的高度一般在2到3层.也就是说查找某一键值的记录,最多只需要2到3次IO开销.按磁盘 ...
- [转] MySQL索引原理
MySQL索引原理 B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引.B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- MySQL索引由浅入深
索引是SQL优化中最重要的手段之一,本文从基础到原理,带你深度掌握索引. 一.索引基础 1.什么是索引 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,索引对于 ...
- 聊聊Mysql索引和redis跳表
摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这 ...
- 浅谈Mysql索引
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 我们都知道,数据库索引可以帮助我们更加快速的找出符合的数据,但是如果不使用索引,Mysql则会从第一条开始查询 ...
- 从MongoDB及mysql 谈B/B+树
一 B树的由来 B树指的是一类树,包括B-树,B+树,B*树等,是一种自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B树允许每个节点有更多的子节点.B树是专门为外部存储器设计的,如磁盘,它对于读 ...
随机推荐
- PAT (Basic Level) Practice 1008 数组元素循环右移问题 分数 20
一个数组A中存有N(>0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥0)个位置,即将A中的数据由(A0A1⋯AN−1)变换为(AN−M⋯AN−1A0A1⋯AN ...
- NSIS 去除字串中的汉字
!include "LogicLib.nsh" XPStyle on !include "WordFunc.nsh" #编写,水晶石 #去除字串中的汉字 #本例 ...
- [CG从零开始] 5. 搞清 MVP 矩阵理论 + 实践
在 4 中成功绘制了三角形以后,下面我们来加载一个 fbx 文件,然后构建 MVP 变换(model-view-projection).简单介绍一下: 从我们拿到模型(主要是网格信息)文件开始,模型网 ...
- MatrixOne从入门到实践01——初识MatrixOne
初识MatrixOne 简介 MatrixOrigin 矩阵起源 是一家数据智能领域的创新企业,其愿景是成为数字世界的核心技术提供者. 物理世界的数字化和智能化无处不在.我们致力于建设开放的技术开源社 ...
- 齐博x1钩子自动添加频道参数变量
频道或插件,增加功能的时候,可能要在后台增加开关参数.这个时候只需要增强对应的接口文件即可,比如创建这样一个文件\application\shop\ext\setting_get\give_jifen ...
- C语言两个升序递增链表逆序合并为一个降序递减链表,并去除重复元素
#include"stdafx.h" #include<stdlib.h> #define LEN sizeof(struct student) struct stud ...
- pip cmd下载速度慢解决方案
cmd下载速度慢不是电脑问题,而是下载的网站有网速限制,如pip,虽然没被墙,但由于是外网,网速极差,经常是几KB一秒,所以我们可以采用镜像服务器,即在命令后加上 -i https://pypi.tu ...
- Gitea 1.18 功能前瞻(其三):增强文本预览效果、继续扩展软件包注册中心、增强工单实用功能、完善了用户邀请机制和SEO
今天是 10 月 26 日星期三,Gitea 周期性地发布了 1.18 的第一个 RC0 版本,在此阶段会收集一些功能和使用上的问题,随后还会发布 RC1,新功能的完整性和健壮性会逐步趋近正式版. 继 ...
- C#中ref和out关键字的应用以及区别(参数修饰符)
ref ref的定义 ref是reference的缩写,通过引用来传递参数的地址,ref基本上是服务于值类型的 ref的使用 //不使用 ref; void Method(int myRefInt) ...
- Kubeadm部署Kubernetes
Kubeadm部署Kubernetes 1.环境准备 主机名 IP 说明 宿主机系统 k8s-master 10.0.0.101 Kubernetes集群的master节点 Ubuntu2004 k8 ...