Hadoop3.x完全分布式搭建(详细)
环境准备
- vm虚拟机(自行安装Centos7系统)
- hadoop3.x安装包(linux版本)
- java1.8安装包(linux版本)
为了能够按照教程顺利操作,需要注意几点细节
- 不要不看文字直接复制粘贴
- 操作命令的用户很重要,否则后续会引发关于权限的问题
- ftp 与 终端工具需要自己操作使用本教程不涵盖操作,如有需要,自行百度,本教程均使用终端shell工具截图,其性质与linux系统右键打开终端相同。
开始啦!
- 使用root用户登录,用一个单独的用户管理hadoop集群,所以要用管理员(root)用户创建一个名字为hadoop的用户。
[root@hadoop102 ~]# useradd hadoop
- 设置 hadoop 用户的密码
[root@hadoop102 ~]# passwd hadoop
- 给 hadoop 用户提权,编辑如下路径文件
[root@hadoop102 ~]# vim /etc/sudoers
将文件此处修改为这样(在100行左右)
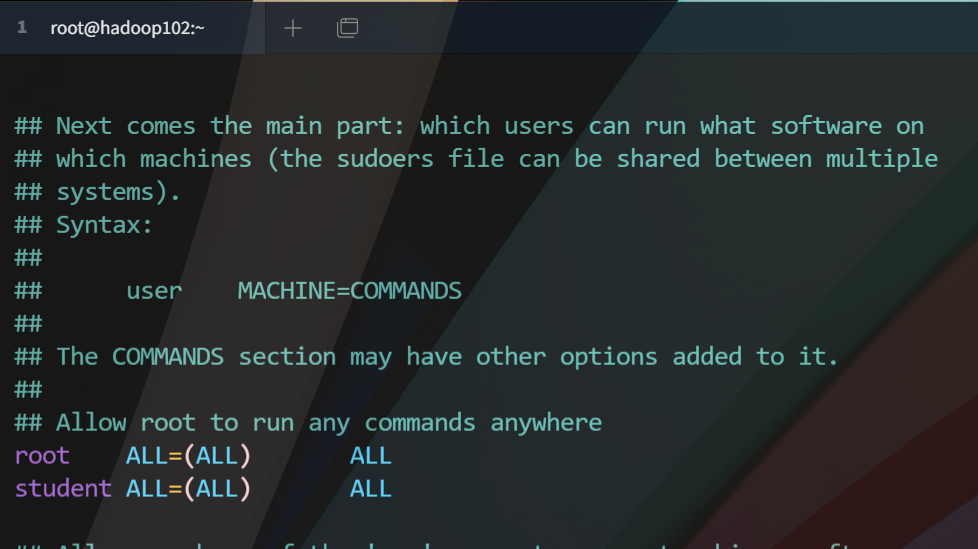
- 修改静态IP
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
静态ip文件修改如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"
DEVICE="ens33"
ONBOOT="yes"
#ip 写自己设置的
IPADDR=192.168.127.112
#子网掩码 固定的
NETMASK=255.255.255.0
#网关 就是将你ip最后一段改成1
GATEWAY=192.168.127.1
- 修改主机名
[root@hadoop102 ~]# vim /etc/hostname
文件内写入自己的主机名字即可
- 
- 修改主机域名映射
[root@hadoop102 ~]# vim /etc/hosts
hosts文件内容如下

关闭防火墙(运行b即可永久关闭)
一次性关闭 -- 重启之后系统会默认打开防火墙
[root@hadoop102 ~]# systemctl stop firewalld
永久关闭防火墙
[root@hadoop102 ~]# systemctl disable firewalld
查看当前防火墙状态
[root@hadoop102 ~]# systemctl status firewalld
状态截图

重启机器,生效所有配置,注意 下次登录直接使用 hadoop 账户信息登录系统,这样子直接创建目录权限就是属于hadoop的
- 如果想要终端连接虚拟机,待重启之后即可输入ip与用户信息即可登录终端。
[root@hadoop102 ~]# reboot
创建javajdk 和 hadoop 安装所需目录
创建软件安装包存放目录
- software目录用于存放安装包
- module目录用于软件的安装目录(或者叫解压目录)
[hadoop@hadoop102 /]$ sudo mkdir /opt/software
[hadoop@hadoop102 /]$ sudo mkdir /opt/module
赋予software目录上传权限,可以看到下面的权限已经允许外部读取写入
[root@hadoop102 opt]# chmod +777 /opt/software /opt/module
[root@hadoop102 opt]# ll
总用量 12
drwxrwxrwx. 2 root root 4096 3月 9 21:56 module
drwxr-xr-x. 2 root root 4096 10月 31 2018 rh
drwxrwxrwx. 2 root root 4096 3月 9 21:56 software
上传hadoop和java安装包(本操作不涵盖,注意:使用任意的ftp工具登录连接时候请使用 hadoop 用户登录操作)
解压至module目录
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module/
[hadoop@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C ../module/
配置java 和 hadoop的环境变量
切换至root用户操作系统文件,操作完成之后切换成hadoop用户
[hadoop@hadoop102 software]$ su root
使用root用户修改环境变量文件,在文件末尾追加如下信息,如果你的安装路径跟我不同这里需要写你自己的,跟着教程走且是同一个版本安装包或者同一个安装文件夹名字的不需要任何修改
#java
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin #hadoop3.1.3
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
切换至hadoop用户,并生效配置文件,查看效果
[hadoop@hadoop102 software]$ source /etc/profile
自行运行如下命令进行环境测试,足够自行不测试也可以的。
[hadoop@hadoop102 software]$ java
[hadoop@hadoop102 software]$ javac
[hadoop@hadoop102 software]$ java -version
[hadoop@hadoop102 software]$ hadoop version
配置hadoop
编辑core-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property> <!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
编辑hdfs-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
编辑yarn-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property> <!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
编辑mapred-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
编辑hadoop-env.sh文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
- 文件末尾追加一行
export JAVA_HOME=/opt/module/jdk1.8.0_212
编辑workers文件
[hadoop@hadoop102 hadoop]$ vim workers
- 写入如下内容
hadoop102
hadoop103
hadoop104
到此步骤,关闭虚拟机,克隆两台,请自行百度,待克隆完成之后,开启两个克隆的机器,不要通过终端连接,然后做下面操作,在vm中进行。
三台主机都使用root用户登录
修改克隆1机器的主机名
[root@hadoop102 hadoop]# vim /etc/hostname
内容如下
hadoop103
修改克隆1的ip
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
内容如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.127.113
NETMASK=255.255.255.0
GATEWAY=192.168.127.1
修改克隆2机器的主机名
[root@hadoop102 hadoop]# vim /etc/hostname
内容如下
hadoop104
修改克隆2机器的ip
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
内容如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.127.114
NETMASK=255.255.255.0
GATEWAY=192.168.127.1
重启两台克隆机器,使配置重新加载生效。
[root@hadoop102 ~]#reboot
配置免密登录
hadoop102生成免密并发送给其余两个节点(hadoop102,hadoop103,hadoop104)
[hadoop@hadoop102 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop102
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop103
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop104
hadoop103生成免密并发送给其余两个节点(hadoop102,hadoop103,hadoop104)
[hadoop@hadoop103 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop103 .ssh]$ ssh-copy-id hadoop102
[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop103
[hadoop@hadoop103 .ssh]$ ssh-copy-id hadoop104
hadoop104生成免密并发送给其余两个节点(hadoop102,hadoop104,hadoop103)
[hadoop@hadoop104 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop102
[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop103
[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop104
格式化(必须主节点操作,既hadoop102这个节点)
[hadoop@hadoop102 sbin]$ hdfs namenode -format
然后可以通过如下文本查看对应的信息
192.168.127.112:9870 --访问hadoop集群前台页面
192.168.127.113:8088 --访问hadoop的所有应用页面
还可以通过各个节点jps命令查看启动的任务节点状态。
Hadoop3.x完全分布式搭建(详细)的更多相关文章
- VM上Hadoop3.1伪分布式模式搭建
https://www.cnblogs.com/asker009/p/9126354.html 最近要搭建一个Hadoop做实验,因为版本的问题遇到不少的坑,本文记录VM上搭建的CentOS7.0+H ...
- hadoop3自学入门笔记(2)—— HDFS分布式搭建
一些介绍 Hadoop 2和Hadoop 3的端口区别 Hadoop 3 HDFS集群架构 我的集群规划 name ip role 61 192.168.3.61 namenode,datanode ...
- Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备 1,hadoop-2.7.3.tar.gz(包) 2,三台机器装有cetos7的机子 (二)安装步骤 1,给每台机子配相同的用户 进入root : su root ---------& ...
- Solr集群搭建详细教程(一)
一.Solr集群的系统架构 注:欢迎大家转载,非商业用途请在醒目位置注明本文链接和作者名dijia478,商业用途请联系本人dijia478@163.com. SolrCloud(solr 云)是So ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
- Solr集群搭建详细教程(二)
注:欢迎大家转载,非商业用途请在醒目位置注明本文链接和作者名dijia478,商业用途请联系本人dijia478@163.com. 之前步骤:Solr集群搭建详细教程(一) 三.solr集群搭建 注意 ...
- hadoop分布式搭建
1.新建三台机器,分别为: hadoop分布式搭建至少需要三台机器: master extension1 extension2 本文利用在VMware Workstation下安装Linux cent ...
随机推荐
- Spring源码-IOC部分-Spring是如何解决Bean循环依赖的【6】
实验环境:spring-framework-5.0.2.jdk8.gradle4.3.1 Spring源码-IOC部分-容器简介[1] Spring源码-IOC部分-容器初始化过程[2] Spring ...
- Mysql自序整理集
1.事务 mysql事务是用于处理操作量大.复杂性高的数据 1. 事务特性 原子性:保证每个事务所有操作要么全部完成或全部不完成,不可能停滞在中间环节:如事务在执行过程中出现错误,则会回滚到事务开始之 ...
- HBuilderX频繁关闭,导致启动不了?
根据官方给出的指南(http://ask.dcloud.net.cn/article/35583),在我的电脑打开%appdata%下面的会有HBuilderX目录,把这个目录删除或改名就可以启动了:
- Git .gitignore 不起作用的解决办法
解决方法的原理:.gitignore只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的. 解决方案:git rm -r --cached . ...
- Xcode 插件推荐
1. Alcatraz(建议安装,以下插件都可以在Alcatraz下载安装) 使用Alcatraz来下载管理Xcode插件, 2.下载安装注释插件VVDocumenter-Xcode. 3.使用代码对 ...
- docker 介绍及安装操作
docker 介绍及安装操作 1.docker概述 2.docker安装及操作 1.docker概述: Docker是一个开源的应用容器引擎,基于go语言开发并遵循了apache2.0协议开源 是在L ...
- MindSpore多元自动微分
技术背景 当前主流的深度学习框架,除了能够便捷高效的搭建机器学习的模型之外,其自动并行和自动微分等功能还为其他领域的科学计算带来了模式的变革.本文我们将探索如何用MindSpore去实现一个多维的自动 ...
- Solution -「NOI.AC 省选膜你赛」T2
这道题就叫 T2 我有什么办法www 题目 题意简述 给定一个字符串 \(s\),其长度为 \(n\),求无序子串对 \((u,v)\) 的个数,其中 \((u,v)\) 满足 \(u,v\) ...
- Solution -「CF 1361E」James and the Chase
\(\mathcal{Description}\) Link. 给定 \(n\) 个点 \(m\) 条边的有向弱连通图.称一个点是"好点"当且仅当从该点出发,不存在到同一点 ...
- 麦克风阵列波束形成之DSB原理与实现
语音识别有近场和远场之分,且很多场景下都会用到麦克风阵列(micphone array).所谓麦克风阵列是一组位于空间不同位置的麦克风按一定的形状规则布置形成的阵列,是对空间传播声音信号进行空间采样的 ...