golang中的字符串
0.1、索引
https://waterflow.link/articles/1666449874974
1、字符串编码
在go中rune是一个unicode编码点。
我们都知道UTF-8将字符编码为1-4个字节,比如我们常用的汉字,UTF-8编码为3个字节。所以rune也是int32的别名。
type rune = int32
当我们打印一个英文字符hello的时候,我们可以得到s的长度为5,因为英文字母代表1个字节:
package main
import "fmt"
func main() {
s := "hello"
fmt.Println(len(s)) // 5
}
但是当我们打印嗨的时候,会打印3个字节。因为使用UTF-8,这个字符会被编码成3个字节:
package main
import "fmt"
func main() {
s := "嗨"
fmt.Println(len(s)) // 3
}
所以,我们使用len内置函数输出的并不是字符数,而是字节数。
下面看一个有趣的例子,我们都知道汉字符使用3个字节编码,分别是0xE5, 0x97, 0xA8。我们运行下面代码会得到汉字嗨:
package main
import "fmt"
func main() {
s := string([]byte{0xE5, 0x97, 0xA8})
fmt.Println(s) // 嗨
}
所以我们需要知道:
- 字符集是一组字符,而编码描述了如何将字符集转换为二进制
- 在 Go 中,字符串引用任意字节的不可变切片
- Go 源码使用 UTF-8 编码。 因此,所有字符串文字都是 UTF-8 字符串。 但是因为字符串可以包含任意字节,如果它是从其他地方(不是源码)获得的,则不能保证它是基于 UTF-8 编码的
- 使用 UTF-8,一个 Unicode 字符可以编码为 1 到 4 个字节
- 在 Go 中对字符串使用 len 返回字节数,而不是字符数
2、字符串遍历
我们在开发中经常会用到对字符串进行遍历的场景。 也许我们想对字符串中的每个 rune 执行一个操作,或者实现一个自定义函数来搜索特定的子字符串。 在这两种情况下,我们都必须遍历字符串的不同字符。 但往往会得到让我们意想不到的结果。
我们看下下面的例子,打印一个字符串中的不同字符和对应的位置:
package main
import "fmt"
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
我们想要的效果是通过遍历字符串,打印出每个字符的索引。但是我们却得到了一个特殊的字符å,其实我们想要的是嗨。
但是打印的字节数是符合我们的预期的,因为嗨是一个中文占用了3个字节,所以len返回的是7。
3、字符串中的字符数
如果我们想要正确的获取字符串的字符数,可以使用go中的utf8包:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s)) // 获取字符数
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
在这个例子中,可以看到,我们确实遍历了5次,也就是对应字符串的5个字符。但是我们获取到的索引其实是对应每个字符的起始位置。像下面这样

那我们如何打印出正确的结果呢?我们稍微修改下代码:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i, v := range s { // 此处改为获取v,可以获取到字符本身
fmt.Printf("字符位置 %d: %c\n", i, v)
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
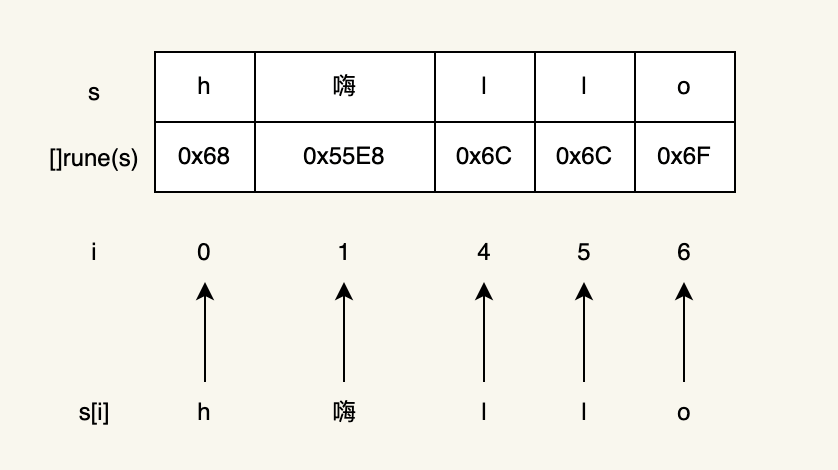
另外一种方法就是把字符串转换成rune切片,这样也会正确打印结果:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
b := []rune(s)
for i := range b {
fmt.Printf("字符位置 %d: %c\n", i, b[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 2: l
字符位置 3: l
字符位置 4: o
len=7
rune len=5
下面是rune切片遍历的过程(中间省略了将字节转换为rune的过程,需要遍历字节,复杂度为O(n))
4、字符串trim
开发中我们经常会遇到去除字符串头部或者尾部字符的操作。比如我们现在有个字符串xohelloxo,现在我们想去除尾部的xo,可能我们会像下面这样写:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimRight(s, "xo")
fmt.Println(s)
}
go run 7.go
xohell
可以看到这不是我们期望的结果。我们可以看下TrimRight的工作原理:
- 从右侧取出第一个字符o,判断是否在xo中,在就移除
- 重复步骤1,知道不符合条件
所以就可以解释通了。当然和它相似的TrimLeft和Trim也是一样的原理。
如果我们只想删除最后xo可以使用TrimSuffix函数:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimSuffix(s, "xo")
fmt.Println(s)
}
go run 7.go
xohello
当然也有对应的从前面删除的函数TrimPrefix。
5、字符串连接
开发中我们经常会用到连接字符串的操作,在go中我们一般有2种方式。
我们先看下+号连接的方式:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
s := ""
for _, value := range values {
s += operate
s += value
}
s = strings.TrimPrefix(s, operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
这种方式的缺点就是,由于字符串的不变性,每次+号赋值的时候s不会被更新,而是重新分配内存,所以这种方式对性能有很大影响。
还有一种方式就是使用strings.Builder:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
首先,我们创建了一个 strings.Builder 结构。 在每次遍历中,我们通过调用 WriteString 方法构造结果字符串,该方法将 value 的内容附加到其内部缓冲区,从而最大限度地减少内存复制。
WriteString 的第二个参数返回的是error,但是error的值会一直为nil。 之所以有第二个error参数是因为我 strings.Builder 实现了 io.StringWriter 接口,它包含一个方法:WriteString(s string) (n int, err error)。
我们看下WriteString的内部是什么样的:
func (b *Builder) WriteString(s string) (int, error) {
b.copyCheck()
b.buf = append(b.buf, s...)
return len(s), nil
}
我们可以看到b.buf是一个字节切片,而里面的实现是使用了append方法。我们知道如果切片很大,使用append会让底层数组不断扩容,影响代码执行效率。
我们知道解决这个问题的方法是,如果事先知道切片的大小,我们可以在初始化的时候就分配好切片的容量。
所以上面的字符串连接还有一种优化方案:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
total := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
total += len(operate) * len(values)
sb := strings.Builder{}
sb.Grow(total) // 这里会重新分配b.buf的长度和容量
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
6、字节切片转字符串
需要明确的是,字节切片转换成字符串,需要复制一份副本出来。可以通过下面的代码做验证:
b := []byte{'a', 'b', 'c'}
s := string(b)
b[1] = 'x'
fmt.Println(s)
事实上,上面将会输出abc而不是axc。所以字节切片到字符串的转换是有开销的。
但是我们开发中经常用到的包iio.Read之类的,入参或者返回经常是字节切片类型。而我们调用这些函数时经常是以字符串的形式,导致我们不得不做一些字节切片刀字符串的转换。
所以结论是,当我们需要使用字符串作为入参或者返回时,我们首先要考虑的是能用字节切片的就用字节切片。
golang中的字符串的更多相关文章
- golang中的字符串拼接
go语言中支持的字符串拼接的方法有很多种,这里就来罗列一下 常用的字符串拼接方法 1.最常用的方法肯定是 + 连接两个字符串.这与python类似,不过由于golang中的字符串是不可变的类型,因此用 ...
- golang 中获取字符串个数
golang 中获取字符串个数 在 golang 中不能直接用 len 函数来统计字符串长度,查看了下源码发现字符串是以 UTF-8 为格式存储的,说明 len 函数是取得包含 byte 的个数 // ...
- golang中获取字符串长度的几种方法
一.获取字符串长度的几种方法 - 使用 bytes.Count() 统计 - 使用 strings.Count() 统计 - 将字符串转换为 []rune 后调用 len 函数进行统计 ...
- golang中字符串的底层实现原理和常见功能
1. 字符串的底层实现原理 package main import ( "fmt" "strconv" "unicode/utf8" ) f ...
- 基础知识 - Golang 中的正则表达式
------------------------------------------------------------ Golang中的正则表达式 ------------------------- ...
- google的grpc在golang中的使用
GRPC是google开源的一个高性能.跨语言的RPC框架,基于HTTP2协议,基于protobuf 3.x,基于Netty 4.x. 前面写过一篇golang标准库的rpc包的用法,这篇文章接着讲一 ...
- Golang中Struct与DB中表字段通过反射自动映射 - sqlmapper
Golang中操作数据库已经有现成的库"database/sql"可以用,但是"database/sql"只提供了最基础的操作接口: 对数据库中一张表的增删改查 ...
- golang 中 string 转换 []byte 的一道笔试题
背景 去面试的时候遇到一道和 string 相关的题目,记录一下用到的知识点.题目如下: s:="123" ps:=&s b:=[]byte(s) pb:=&b s ...
- golang中Context的使用场景
golang中Context的使用场景 context在Go1.7之后就进入标准库中了.它主要的用处如果用一句话来说,是在于控制goroutine的生命周期.当一个计算任务被goroutine承接了之 ...
随机推荐
- 万答#6,MySQL最多只能用到128个逻辑CPU,是真的吗
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 江湖传言MySQL最多只能用到128个逻辑CPU,是真的吗? 同事从客户现场回来,委屈巴巴的说,某PG服务商告诉客户&qu ...
- 关于 java 的动态绑定机制
关于 java 的动态绑定机制 聊一聊动态绑定机制, 相信看完这篇文章,你会对动态绑定机制有所了解. 网上大多一言概括: 当调用对象的时候,该方法会和该对象的内存地址/运行类型绑定. 当调用对象的属性 ...
- mybatis 10: 动态sql --- part2
< foreach >标签 作用 用来进行循环遍历,完成循环条件的查询,批量删除,批量增加,批量更新 用法 循环查询 + 批量删除 + 批量增加 + 批量更新 UsersMapper.ja ...
- HC32L110 在 Ubuntu 下使用 J-Link 烧录
目录 HC32L110(一) HC32L110芯片介绍和Win10下的烧录 HC32L110(二) HC32L110在Ubuntu下的烧录 HC32L110 在 Ubuntu 下使用 J-Link 烧 ...
- GIL互斥锁与线程
GIL互斥锁与线程 GIL互斥锁验证是否存在 """ 昨天我们买票的程序发现很多个线程可能会取到同一个值进行剪除,证明了数据是并发的,但是我们为了证明在Cpython中证 ...
- 给网站添加pjax无刷新,换页音乐不中断
自从博客加了悬浮音乐播放器后就一直在折腾换页音乐不中断的功能 在网上查找后发现想要实现换页音乐不中断的功能必须要为博客加pjax,于是又苦苦寻找并尝试了一番 最后发现网上实现pjax功能基本上是两种方 ...
- MyBatis第一个程序
创建一个maven项目,并且在pom.xml导入myBatis和jdbc的jar包 <dependencies> <dependency> <groupId>org ...
- Java注解系统学习与实战
背景 为什么要再次梳理一下java注解,显而易见,因为重要啊.也是为研究各大类开源框架做铺垫,只有弄清楚Java注解相关原理,才能看懂大部分框架底层的设计. 缘起 注解也叫做元数据,是JDK1.5版本 ...
- kali2020.1修改root密码,以最高权限登录系统
普通用户权限登录系统 sodu su切换为root权限 passwd root 按提示输入密码 再次输入密码 更新密码 右上角点切换用户 root/xxxx 更改成功,下面公布操图片
- centos使用Yum安装postgresql 13
rpm源安装 yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat ...