python网络爬虫之requests库 二
前面一篇在介绍request登录CSDN网站的时候,是采用的固定cookie的方式,也就是先通过抓包的方式得到cookie值,然后将cookie值加在发送的数据包中发送到服务器进行认证。
就好比获取如下的数据。然后加入到header信息中去

构造的cookie值
cookie={'JSESSIONID':'5543aaaaaaaaaaaaaaaabbbbbB.tomcat2',
'uuid_tt_dd':'-411111111111119_20170926','JSESSIONID':'2222222222222220265C40D8A33CB.tomcat2',
'UN':'XXXXX','UE':'xxxxx@163.com','BT':'334343481','LSSC':'LSSC-145514-7aaaaaaaaaaazgGmhFvHfO9taaaaaaaR-passport.csdn.net',
'Hm_lvt_6bcd52f51bbbbbb2bec4a3997715ac':'15044213,150656493,15064444445,1534488843','Hm_lpvt_6bcd52f51bbbbbbbe32bec4a3997715ac':'1506388843',
'dc_tos':'oabckz','dc_session_id':'15063aaaa027_0.7098840409889817','__message_sys_msg_id':'0','__message_gu_msg_id':'0','__message_cnel_msg_id':'0','__message_district_code':'000000','__message_in_school':'0'}
但是这样的实现方式有一个问题,就是每次都需要获取到服务器发送的cookie值,自动化程度大大减低。其实requests库还有个功能可以在后续的报文交互中保存cookie值并自动发送.我们自管构造post的数据就可以了
首先来看下每次登陆的时候递交的值。有username, password还有lt,execution,_eventId这些字段。
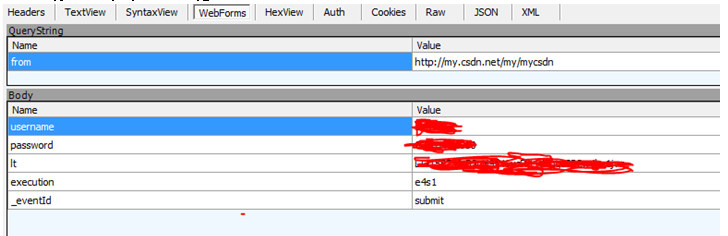
这些字段从哪获取呢, 通过查看CSDN网页登录的数据,找到了这几个字段,原来是输入框元素里面的属性数据

知道了所有数据的来源,那么就来构造程序代码:
header={'Host':'passport.csdn.net','User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36',
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
header1={'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36',
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
url2='http://passport.csdn.net/account/login'
'''建立一个session,这个session会保存交互过程中的cookie并在交互过程中发送'''
r=requests.Session()
s2=r.get(url2)
html=BeautifulSoup(s2.text,"html.parser")
'''通过BeautifulSoup的方法来爬去lt,execution的值'''
for input in html.find_all('input'):
if 'name' in input.attrs and input.attrs['name'] == 'lt':
lt=input.attrs['value']
if 'name' in input.attrs and input.attrs['name'] == 'execution':
e1=input.attrs['value']
pay_load={'username':'xxxxx','password':'xxxxxxx','lt':lt,'execution':e1,'_eventId':'submit'}
s=r.post(url2,headers=header,data=pay_load)
'''获取我的博客内容'''
s1=r.get('http://my.csdn.net/my/mycsdn',headers=header1)
通过这样的方式就避免了每次登陆都需要先获取cookie值,可以在任意时间进行自动登录。比固定cookie值登录的方法要方便很多
python网络爬虫之requests库 二的更多相关文章
- python网络爬虫之requests库
Requests库是用Python编写的HTTP客户端.Requests库比urlopen更加方便.可以节约大量的中间处理过程,从而直接抓取网页数据.来看下具体的例子: def request_fun ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python 网络爬虫的常用库汇总
爬虫的编程语言有不少,但 Python 绝对是其中的主流之一.下面就为大家介绍下 Python 在编写网络爬虫常常用到的一些库. 请求库:实现 HTTP 请求操作 urllib:一系列用于操作URL的 ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- 04,Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
随机推荐
- [HAOI2011]Problem b&&[POI2007]Zap
题目大意: $q(q\leq50000)$组询问,对于给定的$a,b,c,d(a,b,c,d\leq50000)$,求$\displaystyle\sum_{i=a}^b\sum_{j=c}^d[\g ...
- 使用aspnet_regsql.exe 创建ASPState数据库,用来保存session会话
使用aspnet_regsql.exe 创建ASPState数据库,用来保存session会话 因为公司有多台服务器,所以session要保存在sql server上,因此要在数据库中建立存放se ...
- (持续集成)win7上部署Jenkins+MSBuild+Svn+SonarQube+SonarQube Scanner for MSBuild (第二发)
这一篇进入实战,走起.... 登录jenkins,如下图 点击上图中的“新建”按钮,进入下图 输入项目名称,选择“构建一个自由风格的软件项目”即可,点击“ok”,跳转到下图 svn源代码管理(选择代码 ...
- Python--Day2/Day3/Day4(运算符、数据类型及内建函数)
一.昨日内容回顾 Python种类:CPython(Python).JPython.IronPython.PyPy 编码: Unicode.UTF-8.GBK while循环 if...elif... ...
- Windows Server 2008 IE 无法调整安全级别
开始”/“程序”/“管理工具”/“服务器管理器”命令,在弹出的服务器管理器窗口中,找到“安全信息”设置项,单击其中的“配置IE ESC”选项,打开如下图所示的IE增强安全配置窗口.
- 经验分享 | Burpsuite抓取非HTTP流量
使用Burp对安卓应用进行渗透测试的过程中,有时候会遇到某些流量无法拦截的情况,这些流量可能不是HTTP协议的,或者是“比较特殊”的HTTP协议(以下统称非HTTP流量).遇到这种情况,大多数人会选择 ...
- mybatis配置mapperLocations多个路径
<property name="mapperLocations"> <array> <value>classpath*:/mybatis-con ...
- SVN MERGE 方法(原创)
SNV merge操作 1. 创建分支 A
- ElasticSearch和Hive做整合
1.上传elasticsearh-hadoop的jar包到server1-hadoop-namenode-01上 在server1-hadoop-namenode-01上执行: cp /home/d ...
- js 考记忆力得小游戏
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...