python网络爬虫之requests库 二
前面一篇在介绍request登录CSDN网站的时候,是采用的固定cookie的方式,也就是先通过抓包的方式得到cookie值,然后将cookie值加在发送的数据包中发送到服务器进行认证。
就好比获取如下的数据。然后加入到header信息中去

构造的cookie值
cookie={'JSESSIONID':'5543aaaaaaaaaaaaaaaabbbbbB.tomcat2',
'uuid_tt_dd':'-411111111111119_20170926','JSESSIONID':'2222222222222220265C40D8A33CB.tomcat2',
'UN':'XXXXX','UE':'xxxxx@163.com','BT':'334343481','LSSC':'LSSC-145514-7aaaaaaaaaaazgGmhFvHfO9taaaaaaaR-passport.csdn.net',
'Hm_lvt_6bcd52f51bbbbbb2bec4a3997715ac':'15044213,150656493,15064444445,1534488843','Hm_lpvt_6bcd52f51bbbbbbbe32bec4a3997715ac':'1506388843',
'dc_tos':'oabckz','dc_session_id':'15063aaaa027_0.7098840409889817','__message_sys_msg_id':'0','__message_gu_msg_id':'0','__message_cnel_msg_id':'0','__message_district_code':'000000','__message_in_school':'0'}
但是这样的实现方式有一个问题,就是每次都需要获取到服务器发送的cookie值,自动化程度大大减低。其实requests库还有个功能可以在后续的报文交互中保存cookie值并自动发送.我们自管构造post的数据就可以了
首先来看下每次登陆的时候递交的值。有username, password还有lt,execution,_eventId这些字段。
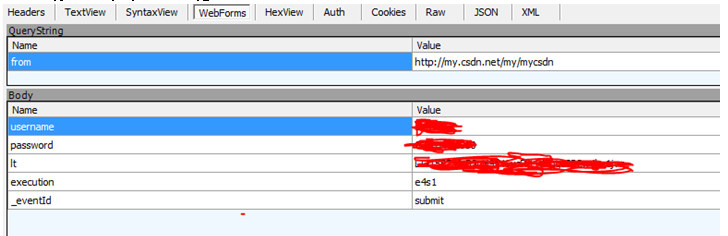
这些字段从哪获取呢, 通过查看CSDN网页登录的数据,找到了这几个字段,原来是输入框元素里面的属性数据

知道了所有数据的来源,那么就来构造程序代码:
header={'Host':'passport.csdn.net','User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36',
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
header1={'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36',
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
url2='http://passport.csdn.net/account/login'
'''建立一个session,这个session会保存交互过程中的cookie并在交互过程中发送'''
r=requests.Session()
s2=r.get(url2)
html=BeautifulSoup(s2.text,"html.parser")
'''通过BeautifulSoup的方法来爬去lt,execution的值'''
for input in html.find_all('input'):
if 'name' in input.attrs and input.attrs['name'] == 'lt':
lt=input.attrs['value']
if 'name' in input.attrs and input.attrs['name'] == 'execution':
e1=input.attrs['value']
pay_load={'username':'xxxxx','password':'xxxxxxx','lt':lt,'execution':e1,'_eventId':'submit'}
s=r.post(url2,headers=header,data=pay_load)
'''获取我的博客内容'''
s1=r.get('http://my.csdn.net/my/mycsdn',headers=header1)
通过这样的方式就避免了每次登陆都需要先获取cookie值,可以在任意时间进行自动登录。比固定cookie值登录的方法要方便很多
python网络爬虫之requests库 二的更多相关文章
- python网络爬虫之requests库
Requests库是用Python编写的HTTP客户端.Requests库比urlopen更加方便.可以节约大量的中间处理过程,从而直接抓取网页数据.来看下具体的例子: def request_fun ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python 网络爬虫的常用库汇总
爬虫的编程语言有不少,但 Python 绝对是其中的主流之一.下面就为大家介绍下 Python 在编写网络爬虫常常用到的一些库. 请求库:实现 HTTP 请求操作 urllib:一系列用于操作URL的 ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- 04,Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
随机推荐
- 你知道如何在springboot中使用redis吗
特别说明:本文针对的是新版 spring boot 2.1.3,其 spring data 依赖为 spring-boot-starter-data-redis,且其默认连接池为 lettuce ...
- Working With Push Buttons In Oracle Forms
Managing push buttons at run time in Oracle Forms is very simple and in this tutorial you will learn ...
- 别名alias——快捷方式
有时候在 linux 或者 windows 上面需要对相关的命令进行快捷处理,这时候可以用到别名—— alias : linux别名设置假设我们需要设置一个 dockers 命令,用来替代 doc ...
- 工程管理,用网页就够了!——Wish3D Earth在线三维地球强势上线
大型工程涉及到众多的施工队.管理单位和相关部门,相互之间需要传递的数据.文件的数量是惊人的,必须建立起有效的信息管理方法,使管理者及时把握工程的信息,全面准确地控制工程施工情况. 现代化的建筑工程管理 ...
- getchar()和getch()的区别
1.getchar();从键盘读取一个字符并输出,该函数的返回值是输入第一个字符的ASCII码:若用户输入的是一连串字符,函数直到用户输入回车时结束,输入的字符连同回车一起存入键盘缓冲区.若程序中有后 ...
- linux中shell script的追踪与调试
Shell调试篇 sh [-nvx] scripts.sh -n:不要执行script,仅查询语法的问题: -v:在执行script前,先将script的内容输出到屏幕上: -x:将使用到的scrip ...
- GTD实用指南
以前通过余弦大牛博客接触到了GTD, 后来我自己接触之后呢, 我是非常讨厌GTD的, 因为太功利化了 反人类 我还是比较懒得··· 可是最近事情真的比较多,不得不做GTD了 = = 郁闷! 时间管理 ...
- vue 组件创建与销毁
vue 组件(如对话框组件)实时创建与销毁: 使用v-if <search-history :show="showSearchHistory" @close="sh ...
- Android开发第一讲之目录结构和程序的执行流程
1.如何在eclipse当中,修改字体 下面的这种办法,可以更改xml的字体 窗口--首选项--常规--外观--颜色和字体--基本--文本字体--编辑Window --> Preferences ...
- iOS_GET_网络请求
同步的 get 请求 #pragma mark - 同步的 get 请求 - (IBAction)GETSynButtonDidClicked:(UIButton *)sender { // 1.网址 ...