【OS_Linux】三大文本处理工具之grep命令
grep(global search regular expression(RE) and print out the line,整行搜索并打印匹配成功的行
语法:grep [选项] 搜索词 搜索的文件
选项:
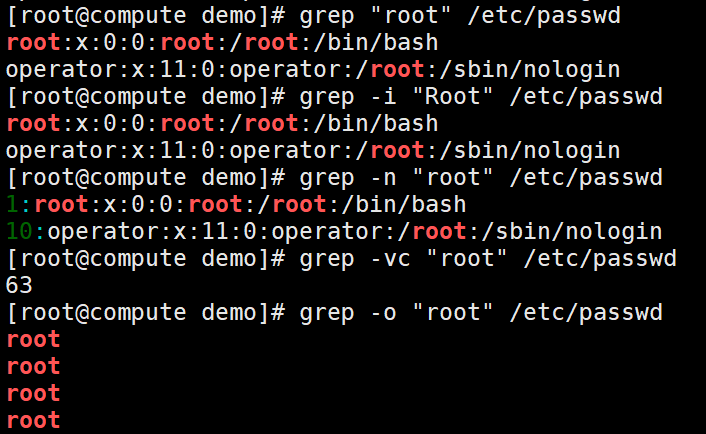
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号(number)
-w :全词(word)匹配,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :统计(count)含有搜索词的行有多少个,仅打印统计的数值而不打印行的内容。注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只(only)显示被匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
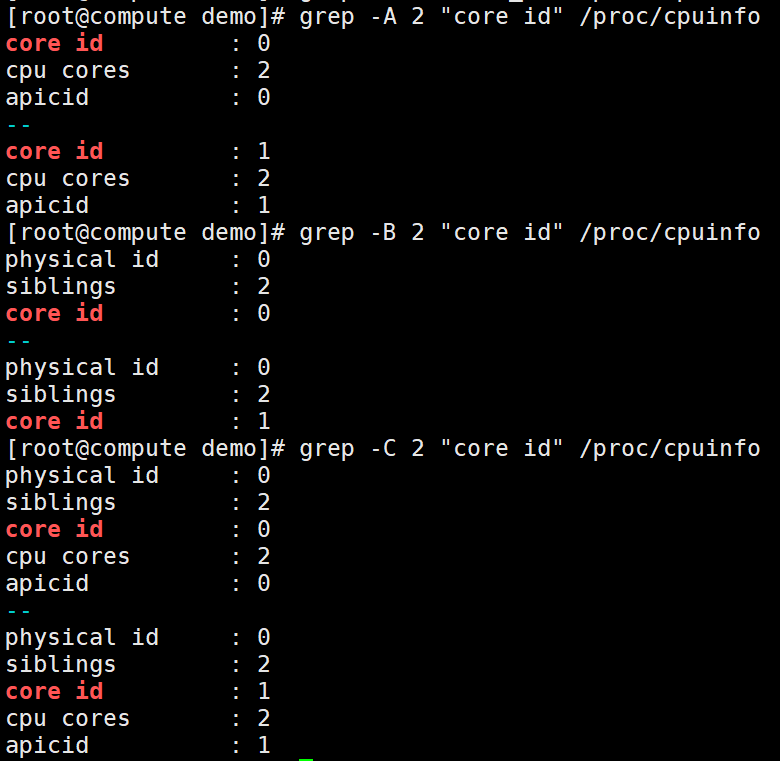
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
-E :开启扩展(Extend)的正则表达式。
示例:
搜索词:
1、直接输入要搜索的字符串,此时可以用fgrep(fast grep)来代替以提高查找速度,比如我要匹配一下hello.c文件中printf的个数:grep -c "printf" hello.c
2、使用正则表达式描述搜索词,下面谈关于基本正则表达式的使用:
字符匹配:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[^123] :反向匹配,这个字符不能是1、2、3中的任意一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]

次数匹配:
x\{m\}:m 个连续的字符x
x\{m,\}:m个以上连续的字符x
x\{m,n\}:m~n个连续的字符x
x*:连续任意个字符x,例如: /[abc] */表示abc中任意字符的若干次
位置匹配:
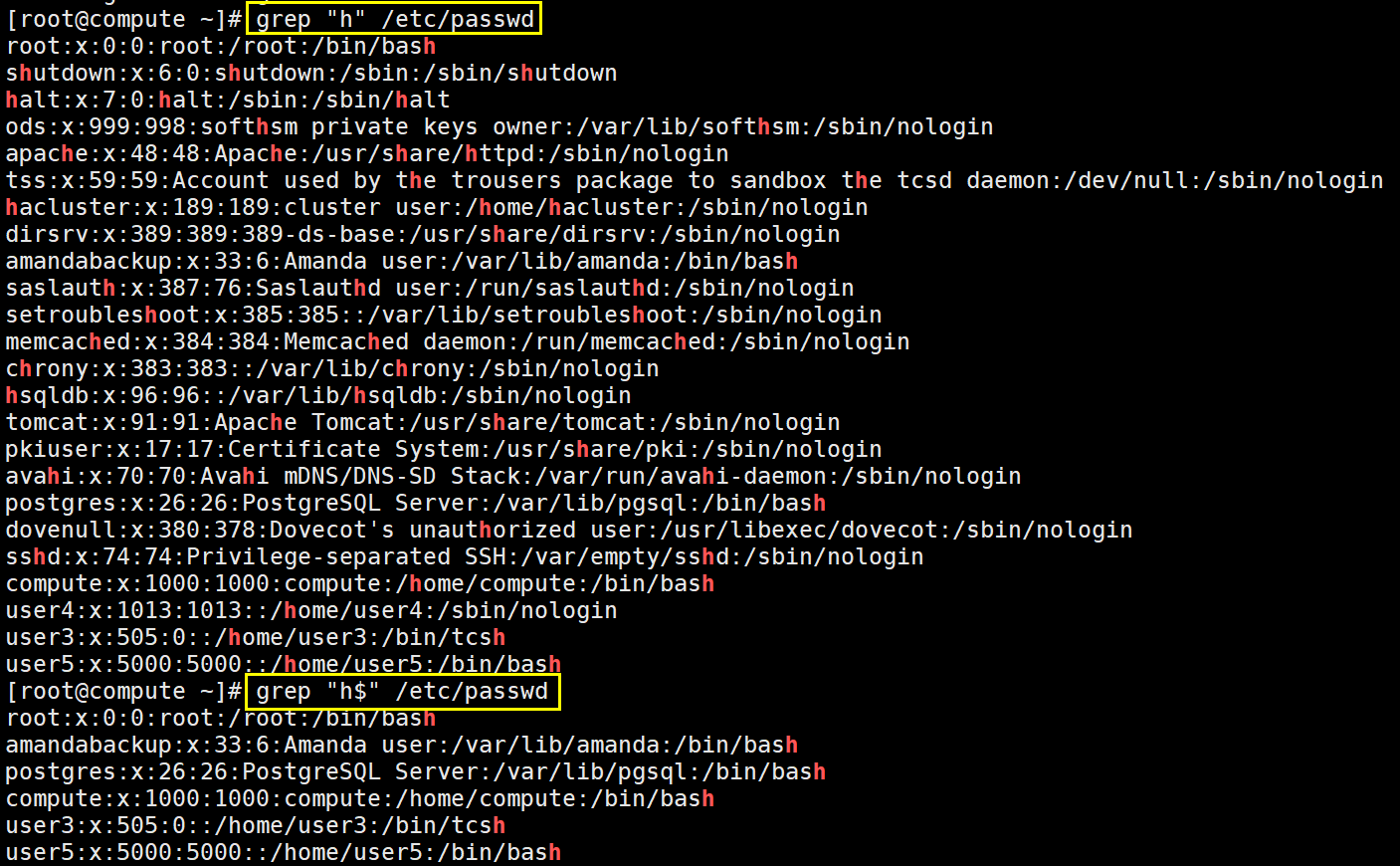
^ :锚定行首
$ :锚定行尾。技巧:"^$"用于匹配空白行。
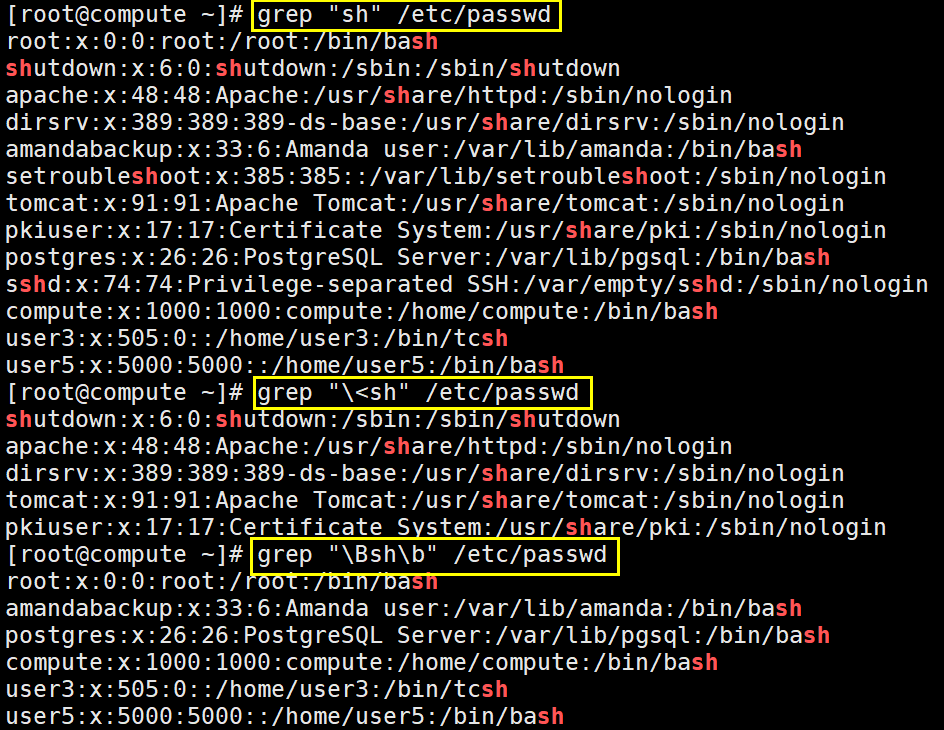
\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b待匹配的字符串\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
本博客参照与:linux中grep命令的用法
【OS_Linux】三大文本处理工具之grep命令的更多相关文章
- 【OS_Linux】三大文本处理工具之sed命令
1.sed命令的简介及用法 sed:即为流编辑器,“stream editor”的缩写.他先将源文件读取到临时缓存区(也叫模式空间)中,再对满足匹配条件的各行执行sed命令.sed命令只针对缓存区中的 ...
- 三大文本处理工具grep、sed及awk的简单介绍
grep.sed和awk都是文本处理工具,虽然都是文本处理工具单却都有各自的优缺点,一种文本处理命令是不能被另一个完全替换的,否则也不会出现三个文本处理命令了.只不过,相比较而言,sed和awk功能更 ...
- shell之三大文本处理工具grep、sed及awk
grep.sed和awk都是文本处理工具,虽然都是文本处理工具单却都有各自的优缺点,一种文本处理命令是不能被另一个完全替换的,否则也不会出现三个文本处理命令了.只不过,相比较而言,sed和awk功能更 ...
- 三大文本处理工具grep、sed及awk
一. 用grep在文件中搜索文本 grep能够接受正则表达式,生成各种格式的输出.除此之外,它还有大量有趣的选项. 1. 搜索包含特定模式的文本行: 2. 从stdin中读取: 3. 单个g ...
- 文本处理工具(grep)
文本处理工具: Linux上文本处理三剑客: 文本过滤工具(模式:pattern)工具: 1.grep:支持基本正则表达式; 2.egrep: ...
- awk、sed、grep三大shell文本处理工具之grep的应用
1.基本格式grep pattern [file...](1)grep 搜索字符串 [filename](2)grep 正则表达式 [filename]在文件中搜索所有 pattern 出现的位置, ...
- 【Linux相识相知】文本处理工具之grep\egrep\fgrep及正则表达式
常说Linux上有文本处理的三剑客,grep.sed和awk,本文就grep做出详细的描述,并引出正则表达式. grep NAME:打印模式匹配的行 SYNOPISIS: grep [OPTIONS] ...
- Linux 文本处理工具(grep sed awk )
^test: 以test开头; test$: 以test结尾: ^$: 表示空行,不是空格: . :代表且只代表任意一个字符(其他功能:当前目录,加载文件): \ : 代表转义字符,表示特殊字符: * ...
- linux(centos8):用grep命令查找文件内容
一,grep的用途: linux平台有最常用的三大文本处理工具:awk/sed/grep grep的功能:搜索指定文件的内容,按照指定的模式匹配,并输出匹配内容所在的行. 需要注意的地方:grep只支 ...
随机推荐
- 浅谈Nginx服务器的内部核心架构设计
前言 Nginx 是一个 免费的 , 开源的 , 高性能 的 HTTP 服务器和 反向代理 ,以及 IMAP / POP3代理服务器. Nginx 以其高性能,稳定性,丰富的功能,简单的配置和低资源消 ...
- CSS之html元素与body元素的范围
- Day2课后作业:购物车简单版
PRODUCT_LIST = [ ['iphone7',6500], ['macbook',12000], ['pythonbook',66], ['bike',999], ['coffee',31] ...
- Codeforces Round #390 (Div. 2) A
One spring day on his way to university Lesha found an array A. Lesha likes to split arrays into sev ...
- AtCoder Beginner Contest 051 ABCD题
A - Haiku Time limit : 2sec / Memory limit : 256MB Score : 100 points Problem Statement As a New Yea ...
- memcpy/memmove?快速乘?
memcpy?memmove? //#pragma GCC optimize(2) #include<bits/stdc++.h> using namespace std; ; ],b[n ...
- 修复在unix系统里的文件打开不能显示正常的颜色问题
在mac上面看到mysql的配置文件的颜色永远是白色,为了让配置文件的颜色更加分明些,这个时候只需进入到home目录下新建一个.vimrc文件, vim .vimrc set nu syntax o ...
- linux下svn服务器搭建步骤
安装步骤如下: 1.yum install subversion 2.输入rpm -ql subversion查看安装位置,如下图: 我们知道svn在bin目录下生成了几个二进制文件. 输入 sv ...
- python入门之前面内容拾遗
int n1 = 123 #根据int类,创建了一个对象 n2 = int(123) #根据int类,创建了一个对象,这里实际上调用了int类里的内置函数__int__(x,2),其中x为定义的对象, ...
- js获取窗口参数
window.onscroll=function getScrollTop(){ console.log(scrollTop) if(document.documentElement&& ...