HBase 高性能获取数据(多线程批量式解决办法) + MySQL和HBase性能测试比较
摘要: 在前篇博客里已经讲述了通过一个自定义 HBase Filter来获取数据的办法,在末尾指出此办法的性能是不能满足应用要求的,很显然对于如此成熟的HBase来说,高性能获取数据应该不是问题。下面首先简单介绍了搜索引擎的性能,然后详细说明了HBase与MySQL的性能对比,这里的数据都是经过实际的测试获得的。最后,给出了采用多线程批量从HBase中取数据的方案,此方案经过测试要比通过自定义Filter的方式性能高出很多。
关键词: HBase, 高性能, 获取数据, 性能对比, 多线程
Solr和HBase专辑
1、“关于Solr的使用总结的心得体会”(http://www.cnblogs.com/wgp13x/p/3742653.html)
2、“中文分词器性能比较”(http://www.cnblogs.com/wgp13x/p/3748764.html)
3、“Solr与HBase架构设计”(http://www.cnblogs.com/wgp13x/p/a8bb8ccd469c96917652201007ad3c50.html)
4、 “大数据架构: 使用HBase和Solr将存储与索引放在不同的机器上”(http://www.cnblogs.com/wgp13x/p/3927979.html)
5、“一个自定义 HBase Filter -通过RowKeys来高性能获取数据”(http://www.cnblogs.com/wgp13x/p/4196466.html)
6、“HBase 高性能获取数据 - 多线程批量式解决办法”(http://www.cnblogs.com/wgp13x/p/4245182.html)
1、 如何存储十亿、百亿数据? 答:使用数据存储集群,增加水平拓展能力,以容纳上百亿数据量
2、 如何保证在十亿、百亿数据上面的查询效率? 答:使用分布式搜索引擎
数据量过亿,无论是存储在关系型数据库还是非关系型数据库,使用非索引字段进行条件查询、模糊查询等复杂查询都是一件极其缓慢甚至是不可能完成的任务,数据库索引建立的是二级索引,大数据查询主要依靠搜索引擎。
根据Solr中国资料显示,在2400亿每条数据大概200字节的数据建立索引,搭建分布式搜索引擎,在50台机器进行搜索测试,其中有条件查询、模糊查询等,其中80%的搜索能够在毫秒内返回结果,剩下一部分能够在20秒内返回,还有5%左右的查询需要在50秒左右的时间完成查询请求,客户端查询请求的并发量为100个客户端。
以下结论均是在同一台服务器上的测试结果。
MySQL单机随机读写能力测试
|
MySQL(InnoDB) |
|
|
运行环境 |
Window Server 2008 x64 |
|
存储引擎 |
InnoDB |
|
最大存储容量 |
64T |
|
列数 |
39列 |
|
每条数据的大小 |
Avg=507Byte |
|
总数据量 |
302,418,176条 |
|
占用的磁盘空间 |
210G |
|
插入效率 |
总共耗时13个小时,每秒约6500条,随着数据量的增大,插入的效率影响不大 |
|
单条数据全表随机读取时间 |
30ms |
|
百条数据全表随机读取时间 |
1,783ms;1,672ms |
|
千条数据全表随机读取时间 |
18,579ms;15,473ms |
|
其他 |
条件查询、Order By、模糊查询基本上是无法响应的 |
HBase基本说明与性能测试
|
HBase |
|
|
数据库类型 |
NoSql—列式数据库 |
|
运行所需要的环境 |
Linux |
|
是否可以搭建集群 |
天然的分布式数据库,具有自动分片功能 |
|
可扩展性 |
强,无缝支持水平拓展 |
|
插入 |
与设置的参数关系很大,批量插入和单条插入差别大,单台机器能够实现1w~3w之间的插入速度 |
|
更新 |
|
|
删除 |
|
|
查询 |
只支持按照rowkey来查询或者全表扫描 |
|
范围查询 |
不支持 |
|
模糊匹配 |
不支持 |
|
时间范围查询 |
不支持 |
|
分页查询 |
可以做到 |
|
数据库安全性 |
低 |
|
大数据量下的查询响应时间 |
各个数据级别下的响应时间: (均为随机读取,不命中缓存) 1、3亿-------------------5ms(单行) 2、3亿-------------------124ms(30行) |
|
大数据量下占用的磁盘空间 |
各个数据级别下的磁盘占用空间(以出租车表为例,17个字段,一行200个字节): 1、1亿-------------------18G(使用GZ压缩) |
|
是否有良好的技术支持 |
社区活跃,但是配置复杂,参数繁多,学习代价比较大 |
|
数据导入和导出 |
有从RDBMS导入数据的工具Sqoop |
|
热备份 |
|
|
异步复制 |
|
|
是否需要商业付费 |
否 |
|
是否开源 |
是 |
|
优点 |
1、 支持高效稳定的大数据存储,上亿行、上百万列、上万个版本,对数据自动分片 2、 列式存储保证了高效的随机读写能力 3、 列数可以动态增长 4、 水平拓展十分容易 5、 拥有良好的生态系统,Sqoop用户数据的导入、Pig可以作为ETL工具,Hadoop作为分布式计算平台 |
|
缺点 |
1、 学习复杂 2、 不支持范围查询、条件查询等查询操作 |
从上面的测试结果表中可以看出,MySQL单表插入速度为每秒6500条,HBase单台机器能够实现1w~3w之间的插入速度,这充分说明HBase插入数据的速度比MySQL高很多。在MySQL单机随机读写能力测试中,单条数据全表随机读取时间是指依据主键去MySQL单表取数据花费的时间;在HBase基本说明与性能测试中,大数据量下查询响应时间是指依照Rowkey到HBase取数据所花费的时间。30ms对5ms,这说明HBase取数据的速度之快也是MySQL望尘莫及的。
在进行上面的性能测试中,无论是从MySQL通过主键读取,还是从HBase通过Rowkey读取,读取的数据量都不大,不超过1000条。当需要一次性读取万级数据时,需要通过设计优化的代码来保证读取速度。
在实现过程中,发现当批量Get的数据量达到一定程度时(如10W),向HBase请求数据会从innerGet发生EOFExeption异常。这里附加上一段从HBase依照多Rowkey获取数据的代码,它采用了性能高的批量Get。在这里,我将这种大批量请求化为每1000个Get的请求,并且采用多线程方式,经过验证,这种方法的效率还是蛮高的。
private ExecutorService pool = Executors.newFixedThreadPool(10); // 这里创建了10个 Active RPC Calls |
|
class HbaseDataGetter implements Callable<List<Data>>
{
private List<String> rowKeys;
private List<String> filterColumn;
private boolean isContiansRowkeys;
private boolean isContainsList;
public HbaseDataGetter(List<String> rowKeys, List<String> filterColumn,
boolean isContiansRowkeys, boolean isContainsList)
{
this.rowKeys = rowKeys;
this.filterColumn = filterColumn;
this.isContiansRowkeys = isContiansRowkeys;
this.isContainsList = isContainsList;
}
@Override
public List<Data> call() throws Exception
{
Object[] objects = getDatasFromHbase(rowKeys, filterColumn);
List<Data> listData = new ArrayList<Data>();
for (Object object : objects)
{
Result r = (Result) object;
Data data = assembleData(r, filterColumn, isContiansRowkeys,
isContainsList);
listData.add(data);
}
return listData;
}
} |
|
private Object[] getDatasFromHbase(List<String> rowKeys,
List<String> filterColumn)
{
createTable(tableName);
Object[] objects = null;
HTableInterface hTableInterface = createTable(tableName);
List<Get> listGets = new ArrayList<Get>();
for (String rk : rowKeys)
{
Get get = new Get(Bytes.toBytes(rk));
if (filterColumn != null)
{
for (String column : filterColumn)
{
get.addColumn(columnFamilyName.getBytes(),
column.getBytes());
}
}
listGets.add(get);
}
try
{
objects = hTableInterface.get(listGets);
}
catch (IOException e1)
{
e1.printStackTrace();
}
finally
{
try
{
listGets.clear();
hTableInterface.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
return objects;
} |
private HTableInterface createTable(String tableName) |
可以肯定的是,此种批量取数据的方法达成的速度,与取一次性数据的数量基本成线性关系,与总数据量相关不大,需要取出的数据越多耗时也就越多,经过测试一次性取1000条数据花费大约在2至3s以内,总数据量为400W。而通过自定义Filter方式取数据的方法的速度,与取一次性数据的数量相关不大,与总数据量成线性关系,总数据量越大取出越慢,即使只需取一条 ,因为此方式对HBase每条数据都过滤一遍。这样,如果在总数不大,需要取数据量较大的情况下,通过自定义Filter取数据的方式可能还占有些优势,但在正常情况下,此种批量取数据的方法还是优势更大。
不得不提的是:在实现过程中,我曾将这种大批量请求化为每4000个Get的多线程请求方式,我们的HBase版本为0.94,这样在一次性请求200000条数据时,HBase直接挂机,client抛出EOFException异常,【processBatchCallback(HConnectionManager.java:1708),processBatch(HConnectionManager.java:1560),(HTable.java:779)】,查看并发连接数与每1000个Get请求一样保持为10个左右,没有异常。查阅相关资料后,我们怀疑,这是由于HTable的非线程安全特性导致的,但经过多时纠缠,最终也没得到可靠结论。后来确定这是由于HBase0.94版自身的问题,在使用0.96版后,此问题便不再出现了。而且我们发现0.94版HBase并不稳定,经常有挂掉情况出现。0.96版HBase要好得多。
这里补充非常重要的一点,在上面的代码中,我通过 private ExecutorService pool = Executors.newFixedThreadPool(10); 创建了一个最多容纳10个线程的线程池,从而创建了10个 Active RPC Calls,有效提高了获取速度。然而,我将此线程池容量扩大至20个后,的确创建了20个 Active RPC Calls,如下图所示,但是会直接引起事故:HBase挂掉。不得不吐cao,HBase实在不稳定,维护极其花费成本。在种种实践验证后,才得到了这个稳定高效的方式,每1000个Get一次批量请求,至多10个线程同时取。

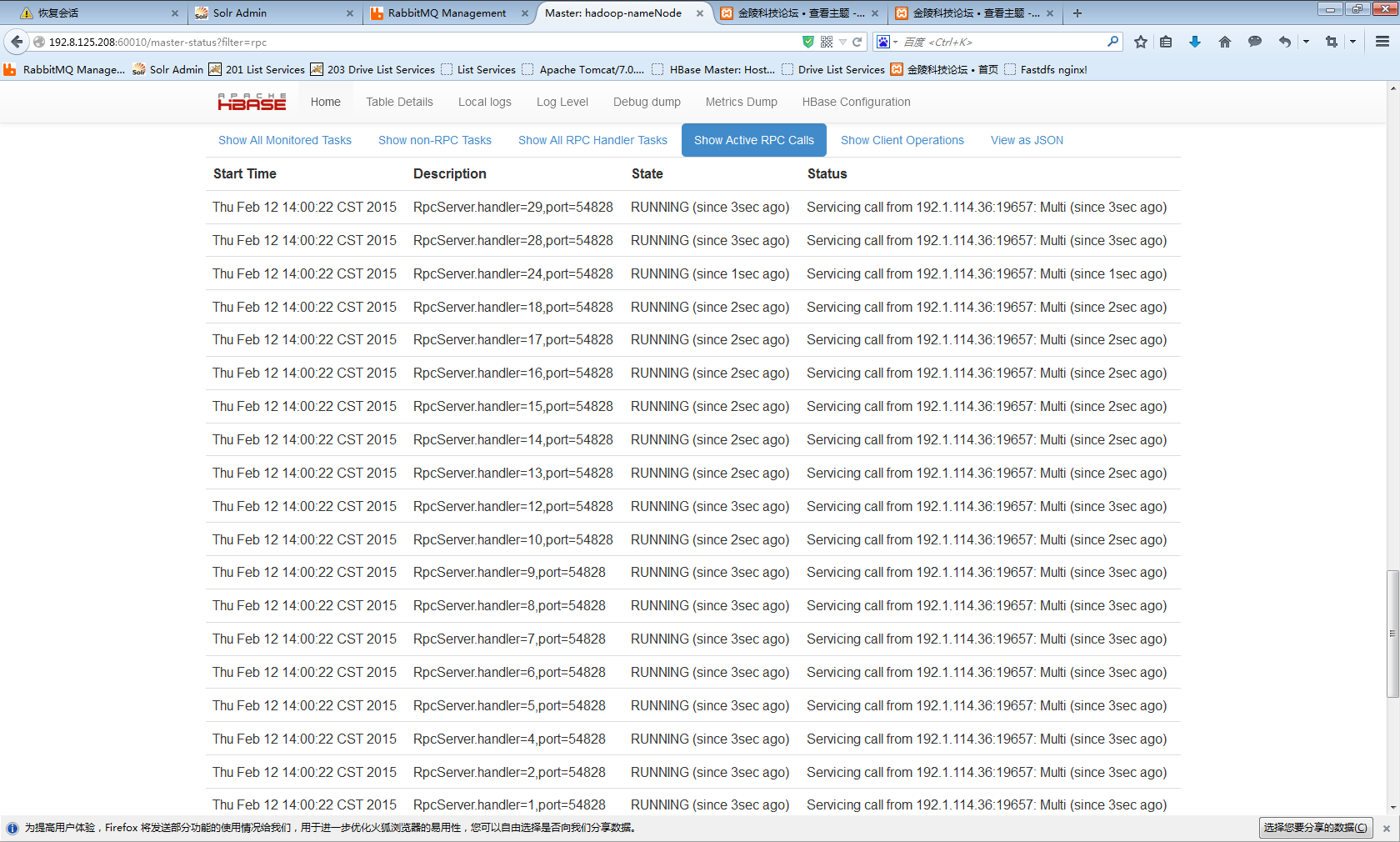
平均效率如下图所示:

更多的HBase及其它的数据存储方案测试情况,HBase高性能插入数据解决方案,正在整理中,敬请批评指正。
HBase 高性能获取数据(多线程批量式解决办法) + MySQL和HBase性能测试比较的更多相关文章
- HBase快照迁移数据失败原因及解决办法
目录 目录 1 1. 背景 1 2. 环境 1 3. 执行语句 1 4. 问题描述 1 5. 错误信息 2 6. 问题原因 3 7. 解决办法 4 1. 背景 机房裁撤,需将源HBase集群的数据迁移 ...
- HBase 高性能加入数据 - 按批多“粮仓”式解决办法
摘要:如何从HBase中的海量数据中,以很快的速度的获取大批量数据,这一议题已经在<HBase 高性能获取数据>(http://www.cnblogs.com/wgp13x/p/42451 ...
- 一个自定义 HBase Filter -“通过RowKeys来高性能获取数据”
摘要: 大家在使用HBase和Solr搭建系统中经常遇到的一个问题就是:“我通过SOLR得到了RowKeys后,该怎样去HBase上取数据”.使用现有的Filter性能差劲,网上也没有现成的自定义Fi ...
- hbase高性能读取数据
有时需要从hbase中一次读取大量的数据,同时对实时性有较高的要求.可以从两方面进行考虑:1.hbase提供的get方法提供了批量获取数据方法,通过组装一个list<Get> gets即可 ...
- [C#]使用 C# 代码实现拓扑排序 dotNet Core WEB程序使用 Nginx反向代理 C#里面获得应用程序的当前路径 关于Nginx设置端口号,在Asp.net 获取不到的,解决办法 .Net程序员 初学Ubuntu ,配置Nignix 夜深了,写了个JQuery的省市区三级级联效果
[C#]使用 C# 代码实现拓扑排序 目录 0.参考资料 1.介绍 2.原理 3.实现 4.深度优先搜索实现 回到顶部 0.参考资料 尊重他人的劳动成果,贴上参考的资料地址,本文仅作学习记录之用. ...
- ArcGIS客户端API中加载大量数据的几种解决办法
ArcGIS客户端API中加载大量数据的几种解决办法 2011-03-25 18:17 REST风格的一切事物方兴未艾,ArcGIS Server的客户端API(Javascript/Flex/Sil ...
- WCF传输过大的数据导致失败的解决办法
WCF传输过大的数据导致失败的解决办法 WCF服务默认是不配置数据传输的限制大小的,那么默认的大小好像是65535B,这才65KB左右,如果希望传输更大一些的数据呢,就需要手动指定一下缓冲区的大小 ...
- Asp.Net 无法获取IIS拾取目录的解决办法[译]
Asp.Net 无法获取IIS拾取目录的解决办法 作者:Jason Doucette [MCP] 翻译:彭远志 原文地址:Fixing the cannot get IIS pickup direc ...
- 标注工具doccano导出数据为空的解决办法
地址:https://github.com/taishan1994/doccano_export doccano_export 使用doccano标注工具同时导出实体和关系数据为空的解决办法.docc ...
随机推荐
- java.lang.NoSuchMethodError: org.apache.xerces.impl.xs.XMLSchemaLoader.loadGrammar
今天在服务器部署的时候,发生了这个问题,明明在本机上使用的时候,没有发生错误,但是发布到服务器上的时候却发生了这个错误,百度了好久,发现遇到这个问题的人很多,但是却没有一个比较满意的答案,后来还是通过 ...
- CI框架源码阅读笔记5 基准测试 BenchMark.php
上一篇博客(CI框架源码阅读笔记4 引导文件CodeIgniter.php)中,我们已经看到:CI中核心流程的核心功能都是由不同的组件来完成的.这些组件类似于一个一个单独的模块,不同的模块完成不同的功 ...
- Guava学习笔记:Immutable(不可变)集合
不可变集合,顾名思义就是说集合是不可被修改的.集合的数据项是在创建的时候提供,并且在整个生命周期中都不可改变. 为什么要用immutable对象?immutable对象有以下的优点: 1.对不可靠的客 ...
- GJM :JS + CSS3 打造炫酷3D相册 [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- ArcGIS Server开发实践之【Search Widget工具查询本地地图服务】
加载本地地图服务,并实现要素的查询.(不足之处还请指点)具体代码如下: <!DOCTYPE html> <html dir="ltr"> <head& ...
- 20款响应式的 HTML5 网页模板【免费下载】
下面的列表集合了20款响应式的 HTML5 网页模板,这些专业的模板能够让你的网站吸引很多的访客.除了好看的外观,HTML5 模板吸引大家的另一个原因是由于其响应性和流动性.赶紧来看看. 您可能感兴趣 ...
- MyEclipse之无法连接到MySQL数据库
问题描述: 在连接mysql中出现如下警告 Fri Oct 28 02:21:53 CST 2016 WARN: Establishing SSL connection without server' ...
- 小白的CSS基础学习
CSS定义: CSS全称为“层叠样式表 (Cascading Style Sheets)”,它主要是用于定义HTML内容在浏览器内的显示样式. CSS代码语法: css样式选择组成部分:选择符+声明( ...
- MAC下利用Github 、hexo、 多说、百度统计 建立个人博客指南
1.前期准备: (1)注册github账号 (2)安装xcode (3)安装node.js 2.创建repository: (1)开个github的个人主页,点击创建仓库按钮 New reposito ...
- [deviceone开发]-天气demo
一.简介 该demo主要实现定位功能,读取天气信息,语音播报功能.其中定位需要配置key,调试二维码请到论坛中下载! 二.效果图 三.相关讨论 http://bbs.deviceone.net/for ...