跟我一起云计算(1)——storm
概述
最近要做一个实时分析的项目,所以需要深入一下storm。
为什么storm
综合下来,有以下几点:
1. 生逢其时
MapReduce 计算模型打开了分布式计算的另一扇大门,极大的降低了实现分布式计算的门槛。有了MapReduce架构的支持,开发者只需要把注意力集中在如何使用 MapReduce的语义来解决具体的业务逻辑,而不用头疼诸如容错,可扩展性,可靠性等一系列硬骨头。一时间,人们拿着MapReduce这把榔头去敲 各种各样的钉子,自然而然的也试图用MapReduce计算模型来解决流处理想要解决的问题。各种失败的尝试之后,人们意识到,改良MapReduce并 不能使之适应于流处理的场景,必须发展出全新的架构来完成这一任务(MapReduce不适合做流处理的原因Yahoo!在其S4的介绍论文里面有比较详 细的阐述,而UCBerkeley的SparkStreaming项目现在正在尝试挑战这一结论,感兴趣的同志请自行查看)。另一方面,人们对传统的 CEP解决方案心存疑虑,认为其非分布式的架构可扩展性不够,无法scaleout来满足海量的数据处理要求。这时候,Yahoo!的S4以及 Twitter的Storm恰到好处的挠到了人们的痒处。
2. 可扩展性
更加明确的说,是scaleout的能力。所谓Scale out (http://en.wikipedia.org/wiki/Scalability#Scale_horizontally_.28scale_out.29), 简单来说就是当一个集群的处理能力不够用的时候,只要往里面再追加一些新的节点,计算有能力迁移到这些新的节点来满足需要。可能的情况下,选择 Scaleout 而非Scale up,这个观念已经深入人心。一般来说,实现Scaleout的关键是Shared nothing architecture,即计算所需要的各种状态都是自满足的,不存在对特定节点强依赖,这样,计算就可以很容易的在节点间迁移,整个系统计算能力不够 用的时候,加入新的节点就可以了。Storm的计算模型本身是Scaleout友好的,Topology 对应的Spout和Bolt并不需要和特定节点绑定,可以很容易的分布在多个节点上。此外,Storm还提供了一个非常强大的命令 (rebalance),可以动态调整特定Topology中各组成元素(Spout/Bolt)的数量以及其和实际计算节点的对应关系。
3. 系统可靠性
Storm 这个分布式流计算框架是建立在Zookeeper的基础上的,大量系统运行状态的元信息都序列化在Zookeeper中。这样,当某一个节点出错时,对应 的关键状态信息并不会丢失,换言之Zookeeper的高可用保证了Storm的高可用。文档(https://github.com /nathanmarz/storm/wiki/Fault-tolerance)讨论了Storm各个子系统的错误冗余行为,可以进一步参考。
4. 计算的可靠性
分 布式计算涉及到多节点/进程之间的通信和依赖,正确的维护所有参与者的状态和依赖关系,是一件非常有挑战性的任务。Storm实现了一整套机制,确保消息 会被完整处理(https://github.com/nathanmarz/storm/wiki/Guaranteeing-message- processing)。 此外,通过TransactionalTopology(https://github.com/nathanmarz/storm/wiki /Transactional-topologies) ,Storm可以保证每个tuple“被且仅被处理一次”。
5. Opensource
这个就不用多说了,开源使得Storm社区及其活跃,到本文写作的时候,Storm已经发展到了0.81,Storm的使用者已经有了一个长长的名单(https://github.com/nathanmarz/storm/wiki/Powered-By),其中不乏比如淘宝,支付宝,Twitter,Groupon这种互联网巨头。
6. Clojure基础上的实现
Storm的核心代码是Clojure和Java。Clojure是一门JVM基础上的函数式编程语言(http://clojure.org/), 是支持STM(SoftwareTransactional Memory)的少数几门语言之一。Clojure推出以来,得到了广泛关注,人们普遍认为,其函数式编程所具有的各种特性能在分布式环境中大有用武之 地, 而Storm则给出了一个很好的实例。从另一个角度来说,Storm也能大大的推动Clojure的普及。
总言之,时势造英雄,Storm在正确的时间出现在了正确的地点,而且刚刚好做了正确的事情,想不红都没有道理。
高层架构
从高来看storm的架构:

指南
在这个指南中,你将学到如何创建strom架构和部署它的集群。Java将是示例中用到的主要语言,在其它的一些示例中将使用python来描述strom支持多语言的能力。
先安装strom,可以参考:
http://my.oschina.net/leejun2005/blog/147607?from=20130804
上面的文章里面已经描述的很清楚了。
可以先从示例storm-starter开始学习strom。
地址是:
https://github.com/nathanmarz/storm-starter
先决条件
你需要安装git和java然后设置这个用户的环境变量。另外还有两个示例需要安装python和ruby。
然后创建新目录下载storm-starter
$ git clone git://github.com/nathanmarz/storm-starter.git && cd storm-starter
storm-starter概述
storm-starter包含很多使用storm的示例。如果你第一次使用storm,首先了解一下它的架构:
- ExclamationTopology: Java编写的基本示例
- WordCountTopology: 和python一起使用的例子
- ReachTopology: 复杂的DRPC的例子
当你熟悉了上面的示例之后,可以在in src/jvm/storm/starter/ 下例如RollingTopWords 去熟悉一些更高级的实现。
如果你要学习更多的示例,可以到Storm project page.
使用storm-starter
使用storm-starter有多种方式,可以使用Leiningen或者maven。这里使用maven。
首先编译:
mvn -f m2-pom.xml compile exec:java -Dexec.classpathScope=compile -Dexec.mainClass=storm.starter.WordCountTopology
然后打包:
mvn -f m2-pom.xml package
运行测试:
mvn -f m2-pom.xml test
然后就是把打包的jar包发送到storm里运行了。
正在讨论的架构
下面就是我们正在处理的项目中使用的架构,还在讨论阶段,也希望对这个有见解的童鞋发表一下自己的观点:
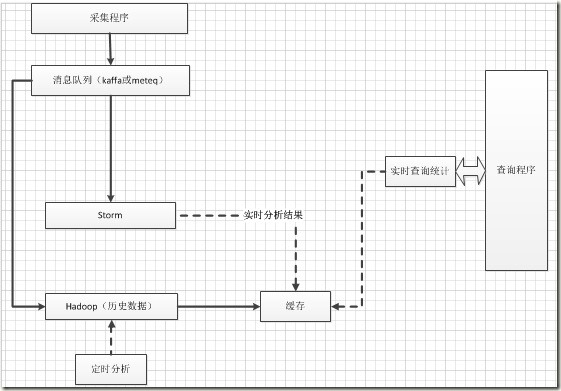
古有“即生瑜,何生亮”,不过我觉得如果没有瑜和亮,可能谁都无法打败曹操,和现在的架构一下,如果不是把流框架storm和任务处理框架hadoop结合起来,也许处理实时的大数据真的很难!
跟我一起云计算(1)——storm的更多相关文章
- Storm构建分布式实时处理应用初探
最近利用闲暇时间,又重新研读了一下Storm.认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算.对于Hadoop, ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- 【转】OpenStack和Docker、ServerLess能不能决定云计算胜负吗?
还记得在十多年前,SaaS鼻祖SalesForce喊出的口号『No Software』吗?SalesForce在这个口号声中开创了SaaS行业,并成为当今市值460亿美元的SaaS之王.今天谈谈『No ...
- Storm:最火的流式处理框架
伴随着信息科技日新月异的发展,信息呈现出爆发式的膨胀,人们获取信息的途径也更加多样.更加便捷,同时对于信息的时效性要求也越来越高.举个搜索场景中的例子,当一个卖家发布了一条宝贝信息时,他希望的当然是这 ...
- Storm实战:在云上搭建大规模实时数据流处理系统(Storm+Kafka)
在大数据时代,数据规模变得越来越大.由于数据的增长速度和非结构化的特性,常用的软硬件工具已无法在用户可容忍的时间内对数据进行采集.管理和处理.本文主要介绍如何在阿里云上使用Kafka和Storm搭建大 ...
- Hadoop、Pig、Hive、Storm、NOSQL 学习资源收集
(一)hadoop 相关安装部署 1.hadoop在windows cygwin下的部署: http://lib.open-open.com/view/1333428291655 http://blo ...
- storm流式大数据处理流行吗
在如今这个信息高速增长的今天,信息实时计算处理能力已经是一项专业技能了,正是因为有了这些需求的存在才使得分布式,同时具备高容错的实时计算系统Storm才变得如此受欢迎,为什么这么说呢?下面看看新霸哥的 ...
- storm入门教程 第一章 前言[转]
1.1 实时流计算 互联网从诞生的第一时间起,对世界的最大的改变就是让信息能够实时交互,从而大大加速了各个环节的效率.正因为大家对信息实时响应.实时交互的需求,软件行业除了个人操作系统之外,数据库 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
随机推荐
- 数据库.bak文件还原报错的处理办法
今天从网上下了个Demo,里面有个.bak文件,就试着还原了一下,结果发现报了错.是了两种方式导入,都不行. 最终找到了解决办法: 可以直接用sql语句对.bak文件进行还原. RESTORE DAT ...
- select值的获取及修改
例子: <select id="a" name="a"> <options value="1">a</opti ...
- 【转载】Adapter用法总结大全
下面的是看到的比较好的地址: Android各种Adapter的用法: http://my.oschina.net/u/658933/blog/372151 Andro ...
- html给div加超链接的方法
1.通过window.open函数 <div onclick="window.open('www.baidu.com')">在新窗口跳转至百度</div> ...
- Fix git 提交代码错误
今天用git clone下代码,修改,push提交,发现以下错误 [root@localhost gocache]# git push origin master error: The request ...
- 【解题报告】BZOJ2550: [Ctsc2004]公式编辑器
题意:给定一个可视化计算器的操作序列,包括插入数字.字母.运算符.分数.矩阵以及移动光标.矩阵插入行.插入列,输出操作序列结束后的屏显(数学输出). 解法:这题既可以用来提升OI/ACM写大代码模拟题 ...
- zmq中zmq_poll()函数介绍
功能: 查看指定的多个socket上哪些socket发生了指定的事件, 事件有: ZMQ_POLLIN: 有消息到来 ZMQ_POLLOUT: 当前无阻塞可以发送消息 ZMQ_POLLERR: 只对标 ...
- easyui 》 radio取值,checkbox取值,select取值,radio选中,checkbox选中,select选中
获取一组radio被选中项的值var item = $('input[@name=items][@checked]').val();获取select被选中项的文本var item = $(" ...
- ELb表达式
主要用于servlet的4个作用域取值:pageScope.requestScope.sessionScope.applicationScope 取值顺序依次从小到大.取值方式如:操作javabean ...
- iOS CGContextRef画图时的常用方法
UIView的drawRect方法 CoreGraphics绘图 综述:描述系统会调用UIView的drawRect方法,所以coreGraphics的所有实现代码放在该函数内,setNeedsDis ...