Hbase物理模型设计
Hbase的存储结构
1、Hbase宏观架构
从上图可以看hbase集群由一个master和多个RegionServer组成,右下角是一个RegionServer的内部图。
Hbase的服务器角色构成:
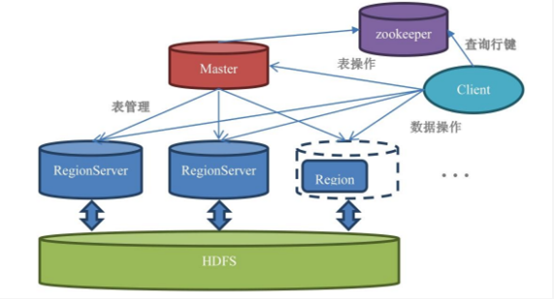
l Master:
负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,比如Region的分割和合并。在hbase中的Master的角色功能比其他类型的集群弱很多。在hbase集群中,master几点宕机之后,业务系统仍旧可以正常运行。但是在其他类似Hadoop和MongoDB的主节点宕机之后,集群无法正常使用。
但是hbase的master也不能宕机太久,很多必要的操作,比如创建表,修改列族配置,一级分割和合并操作,都需要用到master节点。
l RegionServer
RegionServer上有一个或者多个Region,读写的数据就存储在Region上,如果你的Hbase是基于HDFS的,那么Region所有所有数据存取操作都调用了HDFS的客户端来实现的。
l Region
表的一部分数据,Hbase是一个会自动分片的数据库,一个Region就相当于关系数据库中的分区表的一个分区。
l HDFS
Hadoop的一部分。Hbase并不直接跟服务器的硬盘交互,而是和HDFS交互,所以HDFS是真正承载数据的载体。
l ZooKeeper
ZooKeeper索然是虽然是自成一家的第三方组件,不属于Hbase体系,但是他在hbase中的重要性甚至超过了Master。因为读写数据需要的元数据表hbase:meate的位置就存储在ZooKeeper上。
2、RegionServer内部结构
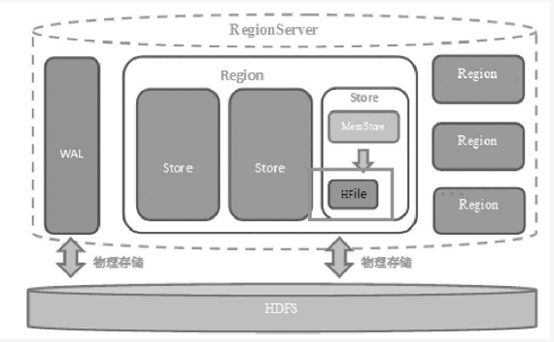
从上图可见,RegionServer内部结构包含:
l WAL
一个WAL:预写日志,是Write-Ahead Log的缩写。从名字可见用途,就是预先写入。当操作到达Region的时候,Hbase先将操作写入到WAL中。Hbase会先把数据放到基于内存实现的Memstore里,等数据到达一定数量时才刷写到最终存储Hfile内。如果这个过程中服务器宕机或者断电,数据就会丢失。WAL是一个保险机制,数在写到Memstore之前,已经被写到WAL。这样,当故障恢复是,可从WAL重恢复数据。
预写日志,就是用来涉及解决宕机之后的操作恢复问题的。数据到达Region的时候是先写入WAL,然后在被加载到Memstore的,就算Region的机器宕机之后,由于WAL的数据是存储在HDFS上的,所以数据并不会丢失。
2.1、Region
多个Region,region相当于一个数据分片,每一个Region都有开始rowkey和结束rowkey,代表了它所存储的rowkey的范围。
Region的内部结构:

一个Region包含:多个Store,每一个Region内部都包含有多个Store实例,一个Store对应一个列族的数据,如果一个表有两个列族,那么在一个Region里面就有两个Store。在最右边的单个Store的结构图上,可以看到Store内部有MemStore和HFile这两部分组成。
2.2、Store内部结构

在Store中有两个组成部分,
l MemStore:每个Store中有一个MemStore实例。数据写入WAL之后就会被放入MemStore。MemStore是内存的存储对象,只有当MemStore满了的时候才会将数据刷写到HFile中。
l HFile:在Store中有多和HFile。当MemStore满了之后Hbase会在HDFS上新生成一个新的Hfile,然后把MemStore中的内容写到这个Hfile中。Hfile直接和HDFS打交道,是数据的存储实体。
2.3、MemStore内部结构
数据被写入到WAL之后就会被加载到MemStore中去。MemStore的大小增加到超过一定阈值的时候就会被刷写到HDFS 上,以Hfile的形式被持久化起来。
MemStore涉及思想:
1)由于HDFS上的文件不可修改,为了让数据顺序存储从而提高读取效率,Hbase使用了LSM树结构来存储数据。数据会现在MemStore中整理成LSM树,最后在刷写到Hfile上。但是在读数据时,先读取BlockCache缓存,如果读不到,在读取HFILE+MemStore。
2)优化数据存储效率;如果一个数据被添加后马上就又被删除,这个在刷写时就可以直接不用刷写到HDFS了。Hbase是一个随机读写数据库,MemStore会在数据被最终刷写到HDFS上之前对文件进行排序处理,这样随机写入的数据就变成了顺序存储的顺序,可以提高读写效率,也可以实现Hbase的LSM树数据结构。
2.4、HFile内部结构
Hfile是数据存储的实际载体,我们所创建的表,列等数据都存储在Hfile里面,Hfile类似于Hadoop的Tfile。Hfile的结构图如下:
Hfile是由一个一个的块组成的,在Hbase中一个快的大小默认为64kb,有列族上的BLOCKSIZE属性定于。这些快区分不同的角色。

Data:数据块。每个HFile有多个Data块。我们存储在Hbase表中的数据就在数据块中。Data块其实是可选的,但是几乎很难看到不包含Date块的HFile。
Meta:元数据块。Meta也是可选的,Meta块只有在文件关闭的时候才会写入,Meta存储了该文件的元数据信息。
FileInfo:文件信息,其实也是一种数据存储快,FileInfo是HFile的必要组成部分。它只有在文件关闭的时候写入,存储的是这个文件的信息。比如最后一个Key。平均的key长度等。
DataIndex:存储Date块索引信息的块文件。索引的信息其实也就是Date块的偏移量。DateIndex也是可选的,有Daye块才有DateIndex.
Trailer:必选的,它存储了FileInfo,DateIndex,MetaIndex块的偏移量。
2.5、Data的内部结构

Data数据块的第一位存储的是块的类型,后面存储的是多个KeyValue键值对,也就是单元格(Cell)的实现类。Cell是一个接口,KeyValue是它的实现类。
2.6、KeyValue的结构

一个KeyValue类里面最后一个部分是存储数据的Value,而前面的部分都是存储跟该单元格相关的元数据信息。如果你存储的value很小,那么这个单元格的绝大部分空间就是rowkey,cf,column等的元数据。
采用适当的压缩算法可以极大的节省存储列族,列等信息的空间。
3、Hbase的增删改
Hbase的数据持久化基于HDFS,但是HDFS只能新增和删除,hbase却可以增删改查。实际上,真实的情况是,Hbase几乎总是在做新增操作。
当新增一个单元格的时候,Hbase会在HDFS上新增一条数据。
当修改一个单元格的时候,Hbase会在HDFS又新增一条数据,只是版本号比之前那个大。
当删除一个单元格的时候,Hbase还是会新增一条数据。只是这条数据没有value,类型为DELETE,这条数据较墓碑标记。
实际上在Hbase中真正的数据删除发生在Hfile合并的时候。
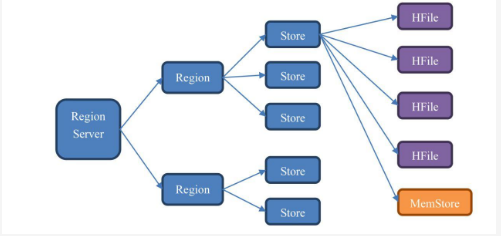
4、Hbase的模型结构图
其实就是
Hbase物理模型设计的更多相关文章
- Hbase物理存储
物理模型 每个column family存储在HDFS上的一个单独文件中,空值不会被保存. Key 和 Version number在每个column family中均有一份: HBase为每个值维护 ...
- HBase 物理视图
- HBase数据模型剖析
出处:http://wuyudong.com/1987.html HBase 进行数据建模的方式和你熟悉的关系型数据库有些不同.关系型数据库围绕表.列和数据类型——数据的形态使用严格的规则.遵守这些严 ...
- Hbase学习笔记01
最近做项目接触到了HDFS.mapreduce以及Hbase,有了实战机会,今天打算将这些知识好好总结下,以备不时之需.首先从Hbase开始吧. Hbase是建立在HDFS上的分布式数据库,下图是Hb ...
- 在powerdesigner中创建物理数据模型
物理数据模型(PDM)是以常用的DBMS(数据库管理系统)理论为基础,将CDM/LDM中所建立的现实世界模型生成相应的DBMS的SQL语言脚本.PDM叙述数据库的物理实现,是对真实数据库的描述 PDM ...
- Hbase随笔2
Hbase是建立在HDFS上的分布式数据库,下图是Hbase表的模型: Hbase这个数据库其实和传统关系数据库还是有很多类似之处,而不是像mongodb,memcached以及redis完全脱离了表 ...
- hbase概念解析
hbase是一种nosql数据库.是一个高可靠,高性能,面向列,可伸缩,实时读取的分布式数据库. hbase一般由行键,时间戳,列族,列,表格单元,行组成. 行一般由一个行键和一个或多个具有关联关系值 ...
- HBase详细概述
原文地址:https://blog.csdn.net/u010270403/article/details/51648462 本文首先简单介绍了HBase,然后重点讲述了HBase的高并发和实时处理数 ...
- Hbase记录-Hbase介绍
Hbase是什么 HBase是一种构建在HDFS之上的分布式.面向列的存储系统,适用于实时读写.随机访问超大规模数据的集群. HBase的特点 大:一个表可以有上亿行,上百万列. 面向列:面向列表(簇 ...
随机推荐
- hdu4135 Co-prime 容斥原理
Given a number N, you are asked to count the number of integers between A and B inclusive which are ...
- LOJ2135 「ZJOI2015」幻想乡战略游戏
题意 题目描述 傲娇少女幽香正在玩一个非常有趣的战略类游戏,本来这个游戏的地图其实还不算太大,幽香还能管得过来,但是不知道为什么现在的网游厂商把游戏的地图越做越大,以至于幽香一眼根本看不过来,更别说和 ...
- !!!!---linux常见问题和解决方案--我的
-------------------------------------------------------------磁盘 ---------------------------文件.目录1.删除 ...
- React中jquery引用
安装jQuery npm i jquery -S 在那个地方使用jQuery就在什么地方引入jQuery import $ from 'jquery'
- 配置文件schema约束
解释:https://blog.csdn.net/zh15732621679/article/details/79074380 操作:https://blog.csdn.net/lhg_55/arti ...
- hive 分隔符替换
Hive建表的时候虽然可以指定字段分隔符,不过用insert overwrite local directory这种方式导出文件时,字段的分割符会被默认置为\001,一般都需要将字段分隔符转换为其它字 ...
- CodeBlocks中去掉下划线的方法
[问题] 如上图所示,某些字符下面会出现红色下划线,看着挺难受后的,决定想办法去掉. 这是拼写检查插件在作怪,把这个插件屏蔽掉就OK了. [步骤一]点击[插件]下的[管理插件]按钮 [步骤二]点击[管 ...
- 递归和非递归分别实现strlen
思路:strlren主要是字符串是以'\0'为结尾标识来计算字符串的长度,所以要实现自己去写strlen也要从这方面下手. 非递归思想:应用循环的思路,以'\0'为循环结束的标识,每循环一次计数加一. ...
- 设置 sideload Outlook Add-ins
上期,我们讲到了用前端技术去建立一个outlook add-ins 我们今天来讲解一下怎样测试一个sideload outlook add-ins. 1. 我们需要登录Outlook在Office 3 ...
- python datetime学习
Python中处理时间的模块datetime, 这个模块里包含的类也叫datetime,所以要使用需要先import from datetime import datetime 获取当前日期和时间 d ...