Spark机器学习(7):KMenas算法
KMenas算法比较简单,不详细介绍了,直接上代码。
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering._
/**
* Created by Administrator on 2017/7/11.
*/
object Kmenas {
def main(args:Array[String]): Unit ={
// 设置运行环境
val conf = new SparkConf().setAppName("KMeans Test")
.setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar"))
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// 读取样本数据并解析
val data = sc.textFile("hdfs://master:9000/ml/data/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// 新建KMeans聚类模型并训练
val initMode = "k-means||"
val numClusters = 2
val numIterations = 500
val model = new KMeans().
setInitializationMode(initMode).
setK(numClusters).
setMaxIterations(numIterations).
run(parsedData)
val centers = model.clusterCenters
println("Centers:")
for (i <- 0 to centers.length - 1) {
println(centers(i)(0) + "\t" + centers(i)(1))
}
// 误差计算
val Error = model.computeCost(parsedData)
println("Errors = " + Error)
}
}
运行结果:
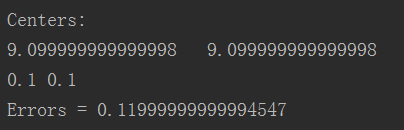
Spark机器学习(7):KMenas算法的更多相关文章
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark机器学习(8):LDA主题模型算法
1. LDA基础知识 LDA(Latent Dirichlet Allocation)是一种主题模型.LDA一个三层贝叶斯概率模型,包含词.主题和文档三层结构. LDA是一个生成模型,可以用来生成一篇 ...
- Spark 机器学习
将Mahout on Spark 中的机器学习算法和MLlib中支持的算法统计如下: 主要针对MLlib进行总结 分类与回归 分类和回归是监督式学习; 监督式学习是指使用有标签的数据(LabeledP ...
- Spark机器学习 Day1 机器学习概述
Spark机器学习 Day1 机器学习概述 今天主要讨论个问题:Spark机器学习的本质是什么,其内部构成到底是什么. 简单来说,机器学习是数据+算法. 数据 在Spark中做机器学习,肯定有数据来源 ...
- Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护模式,主要的机器学习API是spa ...
- Spark机器学习解析下集
上次我们讲过<Spark机器学习(上)>,本文是Spark机器学习的下部分,请点击回顾上部分,再更好地理解本文. 1.机器学习的常见算法 常见的机器学习算法有:l 构造条件概率:回归分 ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- spark机器学习从0到1介绍入门之(一)
一.什么是机器学习 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多门学科.专门研究计算机怎样模拟或实现人类的学习行 ...
随机推荐
- Yahoo的Yslow23条规则
一. CONTENT 减少使用HTTP请求(Minimize HTTP Requests) 通常打开一个页面的时候,大部分的时间都是在下载该页面的图片,css样式,js脚本,flash等等资源,减少这 ...
- 【HTTP】 Fiddler简介
1.为什么是Fiddler? 抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark.为什么使用fiddler?原因如下: a.Firebug虽然可以抓包 ...
- 【C++ Primer | 15】C++类内存分布
C++类内存分布 书上类继承相关章节到这里就结束了,这里不妨说下C++内存分布结构,我们来看看编译器是怎么处理类成员内存分布的,特别是在继承.虚函数存在的情况下. 下面可以定义一个类,像下面这样: c ...
- zjoi 网络
题解: 很显然会发现对于每种颜色分开处理这是一颗树 然后就是裸的lct 有个坑就是判断操作1 可能颜色改成跟原先一样的 代码: #include <bits/stdc++.h> using ...
- 【AtCoder】ARC083
C - Sugar Water 计算一下可以达到水是多少,可以到达的糖是多少 枚举水,然后加最多能加的糖,是\(min(F - i *100,E * 100)\),计算密度,和前一个比较就行 #inc ...
- 【noip模拟赛5】水流
描述 全球气候变暖,小镇A面临水灾.于是你必须买一些泵把水抽走.泵的抽水能力可以认为是无穷大,但你必须把泵放在合适的位置,从而能使所有的水能流到泵里.小镇可以认为是N * M的矩阵.矩阵里的每个单元格 ...
- 【Java】 剑指offer(23) 链表中环的入口结点
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 一个链表中包含环,如何找出环的入口结点?例如,在图3.8的链表中, ...
- DP-hdu1176
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1176 这道题与动态规划中的数塔问题十分类似,因此如果对于数塔问题还不太明白的,可以先参考一下博客: 数 ...
- 使用tortoisegit简化命令
1. 如果希望git保存用户名和密码,后续操作都无需输入密码: git命令: git config --global credential.helper store 或者通过tortoisegit ...
- [洛谷P2258][NOIP2014PJ]子矩阵(dfs)(dp)
NOIP 2014普及组 T4(话说一道PJ组的题就把我卡了一个多小时诶) 这道题在我看第一次的时候是没有意识到这是一道DP题的,然后就摁着DFS敲了好长时间,结果敲了一个TLE 这是DP!!! 下面 ...