Spark机器学习(7):KMenas算法
KMenas算法比较简单,不详细介绍了,直接上代码。
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering._
/**
* Created by Administrator on 2017/7/11.
*/
object Kmenas {
def main(args:Array[String]): Unit ={
// 设置运行环境
val conf = new SparkConf().setAppName("KMeans Test")
.setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar"))
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// 读取样本数据并解析
val data = sc.textFile("hdfs://master:9000/ml/data/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// 新建KMeans聚类模型并训练
val initMode = "k-means||"
val numClusters = 2
val numIterations = 500
val model = new KMeans().
setInitializationMode(initMode).
setK(numClusters).
setMaxIterations(numIterations).
run(parsedData)
val centers = model.clusterCenters
println("Centers:")
for (i <- 0 to centers.length - 1) {
println(centers(i)(0) + "\t" + centers(i)(1))
}
// 误差计算
val Error = model.computeCost(parsedData)
println("Errors = " + Error)
}
}
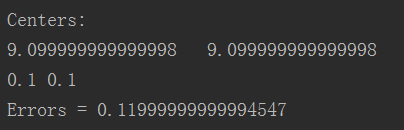
运行结果:
Spark机器学习(7):KMenas算法的更多相关文章
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark机器学习(8):LDA主题模型算法
1. LDA基础知识 LDA(Latent Dirichlet Allocation)是一种主题模型.LDA一个三层贝叶斯概率模型,包含词.主题和文档三层结构. LDA是一个生成模型,可以用来生成一篇 ...
- Spark 机器学习
将Mahout on Spark 中的机器学习算法和MLlib中支持的算法统计如下: 主要针对MLlib进行总结 分类与回归 分类和回归是监督式学习; 监督式学习是指使用有标签的数据(LabeledP ...
- Spark机器学习 Day1 机器学习概述
Spark机器学习 Day1 机器学习概述 今天主要讨论个问题:Spark机器学习的本质是什么,其内部构成到底是什么. 简单来说,机器学习是数据+算法. 数据 在Spark中做机器学习,肯定有数据来源 ...
- Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护模式,主要的机器学习API是spa ...
- Spark机器学习解析下集
上次我们讲过<Spark机器学习(上)>,本文是Spark机器学习的下部分,请点击回顾上部分,再更好地理解本文. 1.机器学习的常见算法 常见的机器学习算法有:l 构造条件概率:回归分 ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- spark机器学习从0到1介绍入门之(一)
一.什么是机器学习 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多门学科.专门研究计算机怎样模拟或实现人类的学习行 ...
随机推荐
- python 全栈开发,Day43(python全栈11期月考题)
python全栈11期月考题 1.常用字符串格式化有哪些?并说明他们的区别 2.请手写一个单例模式(面试题) 3.利用 python 打印前一天的本地时间,格式为‘2018-01-30’(面试题) 4 ...
- 步步为营-53-JavaScript
说明 :JS比较常用 1.1 常见的两种使用方式: 1.1.1 直接使用 <script>alert('Hello,World')</script> 1.1.2 引用 ...
- MyBatis查询,返回值Map或List<Map>
一.返回值Map 1.mapper.xml <select id="selectUserMapLimitOne" resultType="java.util.Has ...
- hdu 1258 从n个数中找和为t的组合 (DFS)
题意:首先给你一个t,然后是n,后面输入n个数,然后让你求的是n个数中和为t的序列总共有多少种,把他们按从左到右的顺序输出来. Sample Input4 6 4 3 2 2 1 15 3 2 1 1 ...
- gulp初探
很多人都在用grunt和gulp,我现在连github都不用..为了说自己是个前端,还是搞搞gulp吧 nodejs很多人都会安装,这个不是问题 npm模块现在好像是自带的..我忘了.. 先全局安装下 ...
- 【Java】 剑指offer(5) 从尾到头打印链表
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 输入一个链表的头结点,从尾到头反过来打印出每个结点的值.结点定义如下: ...
- 063 日志分析(pv uv 登录人数 游客人数 平均访问时间 二跳率 独立IP)
1.需求分析 分析指标 pv uv 登录人数 游客人数 平均访问时间 二跳率 独立IP 2.使用的日志(一号店),会话信息 3.创建数据库 4.创建源表,存储源数据 5.创建我们需要的use表 6.创 ...
- P1510 精卫填海
P1510 精卫填海二分答案二分背包容量,判断能否满足v.判断的话就跑01背包就好了. #include<iostream> #include<cstdio> #include ...
- VUE 打包后关于 -webkit-box-orient: vertical; 消失,导致多行溢出不管用问题
VUE 打包后 -webkit-box-orient: vertical; 样式消失,导致页面样式爆炸,看了看解决方案,在这里总结一下: 实际上是 optimize-css-assets-webpac ...
- nodejs那些事儿
http://www.nodeclass.com/ https://cnodejs.org/ 当前版本,v6.11.2 安装node时,牵扯features的选择,在不了解的情况下,我选择了第1个.网 ...