【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以
这篇学习笔记就是记录如何解决 故障转移的
启动以后每个都是Standby,选举一个为Active
监控 每个NameNode 都应该监控 (ZKFC Failover Controller 失败故障转移控制器)
开始进行配置
在hdfs-site.xml 文件中配置 :
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site.xml 文件中配置 :
<!--配置zookeeper 集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-senior.zuoyan.com:2181,hadoop-senior02.zuoyan.com:2181,hadoop-senior03.zuoyan.com:2181</value>
</property>
启动:
首先关闭所有HDFS服务: sbin/stop-dfs.sh (可以看到服务关闭的顺序 )
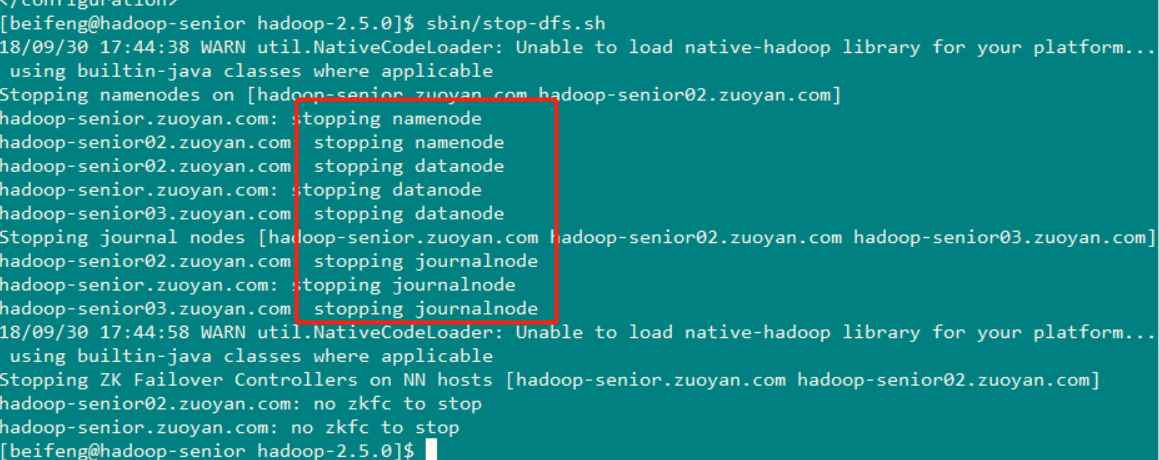
然后将节点一(hadoop-senior.zuoyan.com )上 刚配置好的两个配置文件(core-site.xml 和 hdfs-site.xm ) 同步到其余两台机器上去
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior02.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior03.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/

接下来就是启动zookeeper ,进入到zookeeper的安装目录中,执行命令 bin/zkServer.sh start

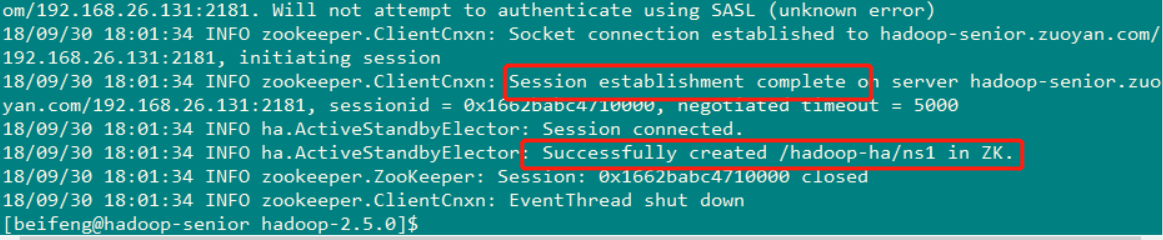
启动完成后要进行的操作:初始化HA在zookeeper 中 ( 第一个节点 ) 状态 bin/hdfs zkfc -formatZk
首先在第二个节点的终端下链接上zookeeper的客户端

然后在第一个节点上进行初始化

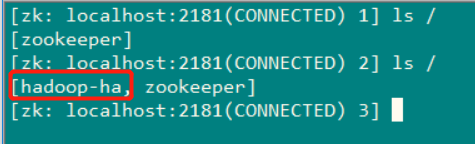
然后在hadoop-senior02.zuoyan.com 主机上的zookeeper 的客户端进行查看 ls /
( 就会发现多了一个节点 )
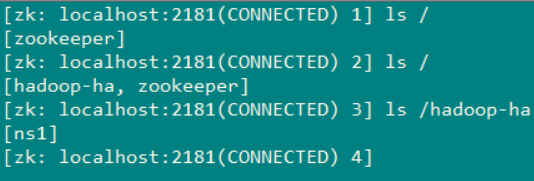
在查看hadoop-ha 这个就是 初始化时创建的那个文件目录
启动HDFS :
命令:sbin/start-dfs.sh
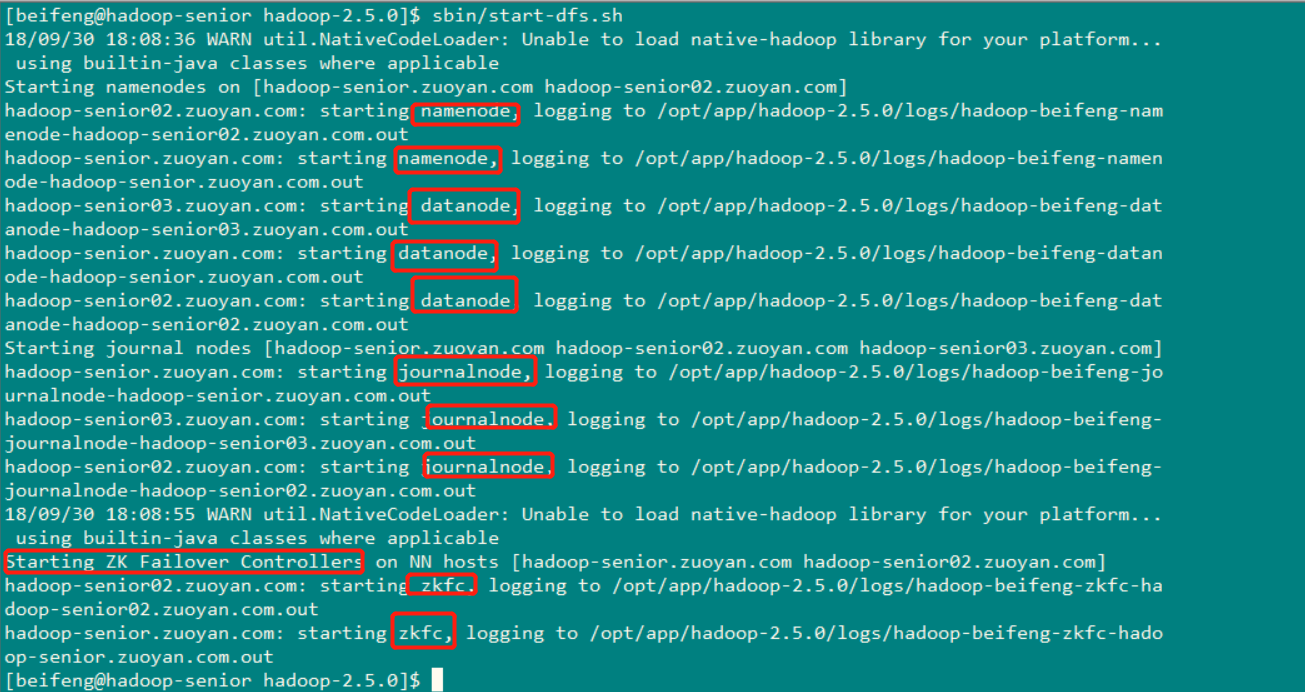
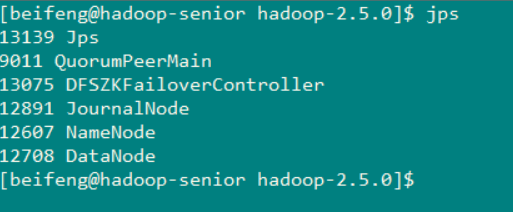
查看启动的服务
现在主节点 NameNode 和 Standby 的分布情况
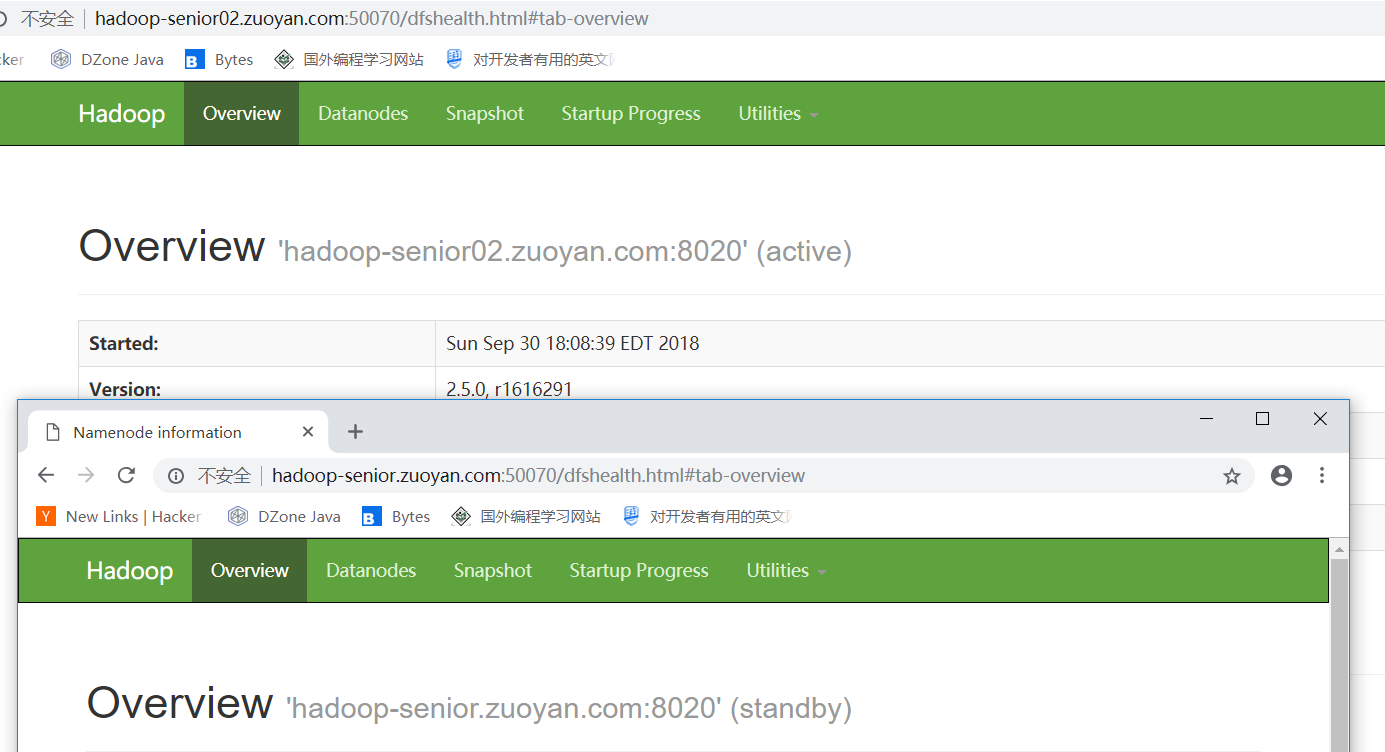
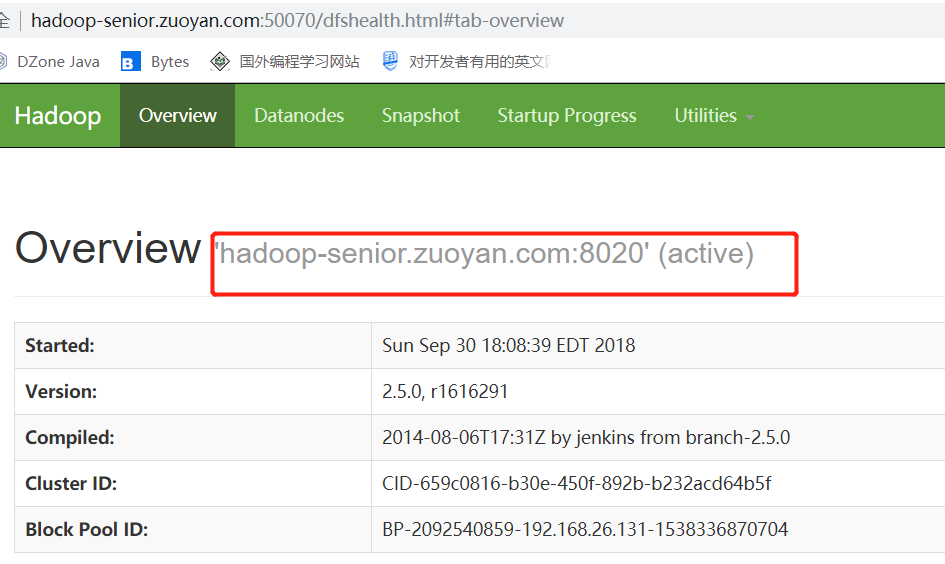
现在要结束掉Active的节点,检查他是否会自己进行故障转移
jps 查看一下任务运行的 id号 然后使用命令 kill -9 9991

然后去查看Hadoop-senior.zuoyan.com 是否成为了Active
注意:zookeeper 挂了 不会对集群造成影响,就是不能进行故障自动转移,
还有就是zookeeper 需要服务器的时间同步
这种HA的结构 是QJM
【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】的更多相关文章
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
- 3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一.说明 从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换: 接下来看一下用zookeeper进行自动故障转移: # 在启动HA之后,两个NameNode都是s ...
- MongoDB 主从复制及 自动故障转移
1.MongoDB 主从复制 MongoDB复制是将数据同步在多个服务器的过程. 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性. 复制还允许您从 ...
- (2)MongoDB副本集自动故障转移原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- (2)MongoDB副本集自动故障转移全流程原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- 非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法
非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法 环境:非域环境 因为是自动故障转移,需要加入见证,事务安全模式是,强安全FULL模式 做到最后一 ...
- keepalive配置mysql自动故障转移
keepalive配置mysql自动故障转移 原创 2016年02月29日 02:16:52 2640 本文先配置了一个双master环境,互为主从,然后通过Keepalive配置了一个虚拟IP,客户 ...
- Redis集群以及自动故障转移测试
在Redis中,与Sentinel(哨兵)实现的高可用相比,集群(cluster)更多的是强调数据的分片或者是节点的伸缩性,如果在集群的主节点上加入对应的从节点,集群还可以自动故障转移,因此相比Sen ...
随机推荐
- XML系列之--解析电文格式的XML(二)
上一节介绍了XML的结构以及如何创建.讲到了XML可作为一种简单文本存储数据,把数据存储起来,以XML的方式进行传递.当接收到XML时,必不可少的就是对其进行解析,捞取有效数据,或者将第三方数据以节点 ...
- highchart应用示例2-上:圆角柱状图,下:多指标曲线图
1.ajax调用接口获取数据 function getCityData() { var date1 = $('#datetimepicker1').val(); var date2 = $('#dat ...
- 案例:Redis在唯品会的大规模应用
目前在唯品会主要负责redis/hbase的运维和开发支持工作,也参与工具开发工作,本文是在Redis中国用户组给大家分享redis cluster的生产实践. 分享大纲 本次分享内容如下: 1.生产 ...
- MyEclipse非正常关闭问题
问题:电脑突然断电,myeclipse非正常关闭,“Package Explorer”非正常显示,出现错误“Could not create the view: An unexpected excep ...
- Shell生成数字序列
转自http://kodango.com/generate-number-sequence-in-shell Shell里怎么输出指定的数字序列: for i in {1..5}; do echo $ ...
- java中的基本数据类型和引用数据类型
java中基本数据类型有8种:byte,short,int,long,char,float,double,boolean 整型有四种:byte short,int,long byte: 1字节 ...
- daemon进程fork一次和fork两次的区别?
守护进程也称为精灵进程(Daemon),是运行在后台的一种特殊的进程.它独立于控制终端并且周期性的执行某种任务负等待处理某些发生的事件.因为他们没有控制终端,所以说他们是在后台运行的. 守护进程的特点 ...
- rhel 6 version `GLIBC_2.14' not found (required by /usr/lib64/libstdc++.so.6)以及libstdc++.so.6: version GLIBCXX_3.4.18 not found解决办法
最近在oracle linux 7.3下开发了个应用,发布到rhel 6.5运行的时候,报version `GLIBC_2.14' not found (required by /usr/lib64/ ...
- oracle审计例子
1.数据库开启审计alter system set audit_trail=db,extended scope=spfile;shutdown immediatestartup 2.对某个表进行审计c ...
- mvc 文件下载
public class DownLoadHelper { /// <summary> /// WriteFile实现下载--测试通过 /// </summary> /// & ...