【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以
这篇学习笔记就是记录如何解决 故障转移的
启动以后每个都是Standby,选举一个为Active
监控 每个NameNode 都应该监控 (ZKFC Failover Controller 失败故障转移控制器)
开始进行配置
在hdfs-site.xml 文件中配置 :
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site.xml 文件中配置 :
<!--配置zookeeper 集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-senior.zuoyan.com:2181,hadoop-senior02.zuoyan.com:2181,hadoop-senior03.zuoyan.com:2181</value>
</property>
启动:
首先关闭所有HDFS服务: sbin/stop-dfs.sh (可以看到服务关闭的顺序 )
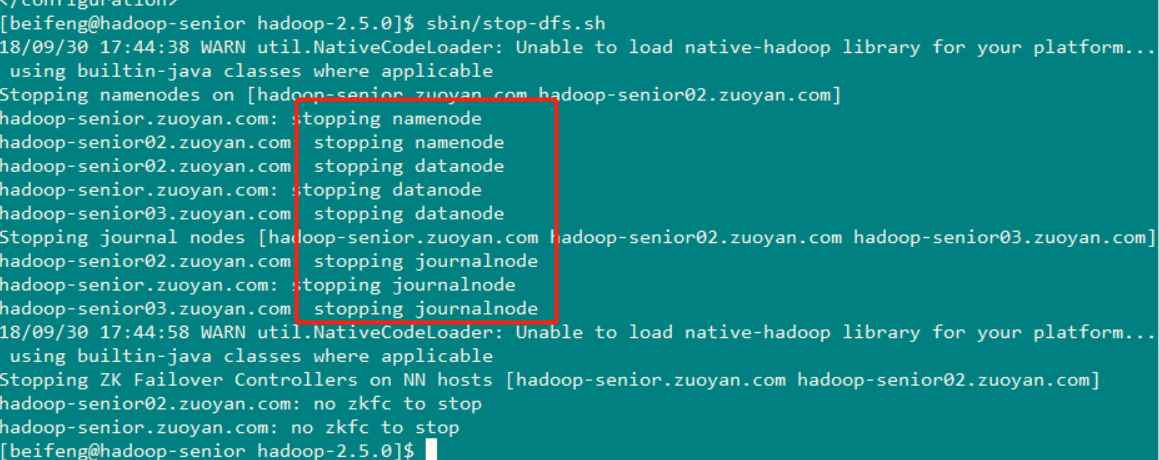
然后将节点一(hadoop-senior.zuoyan.com )上 刚配置好的两个配置文件(core-site.xml 和 hdfs-site.xm ) 同步到其余两台机器上去
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior02.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior03.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/

接下来就是启动zookeeper ,进入到zookeeper的安装目录中,执行命令 bin/zkServer.sh start

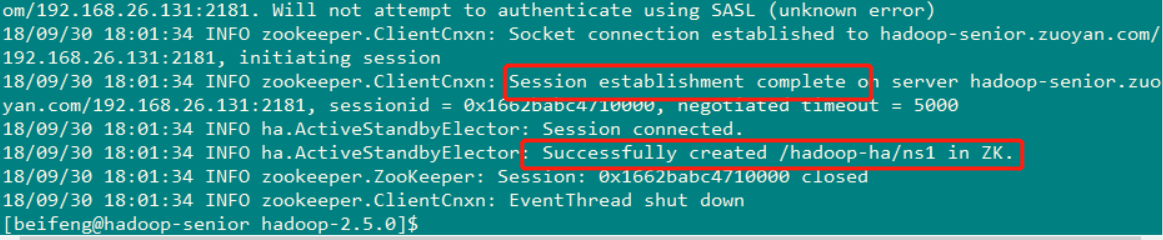
启动完成后要进行的操作:初始化HA在zookeeper 中 ( 第一个节点 ) 状态 bin/hdfs zkfc -formatZk
首先在第二个节点的终端下链接上zookeeper的客户端

然后在第一个节点上进行初始化

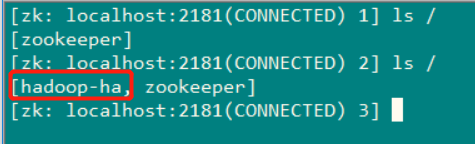
然后在hadoop-senior02.zuoyan.com 主机上的zookeeper 的客户端进行查看 ls /
( 就会发现多了一个节点 )
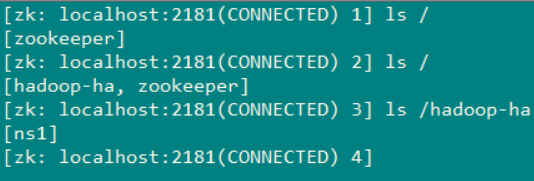
在查看hadoop-ha 这个就是 初始化时创建的那个文件目录
启动HDFS :
命令:sbin/start-dfs.sh
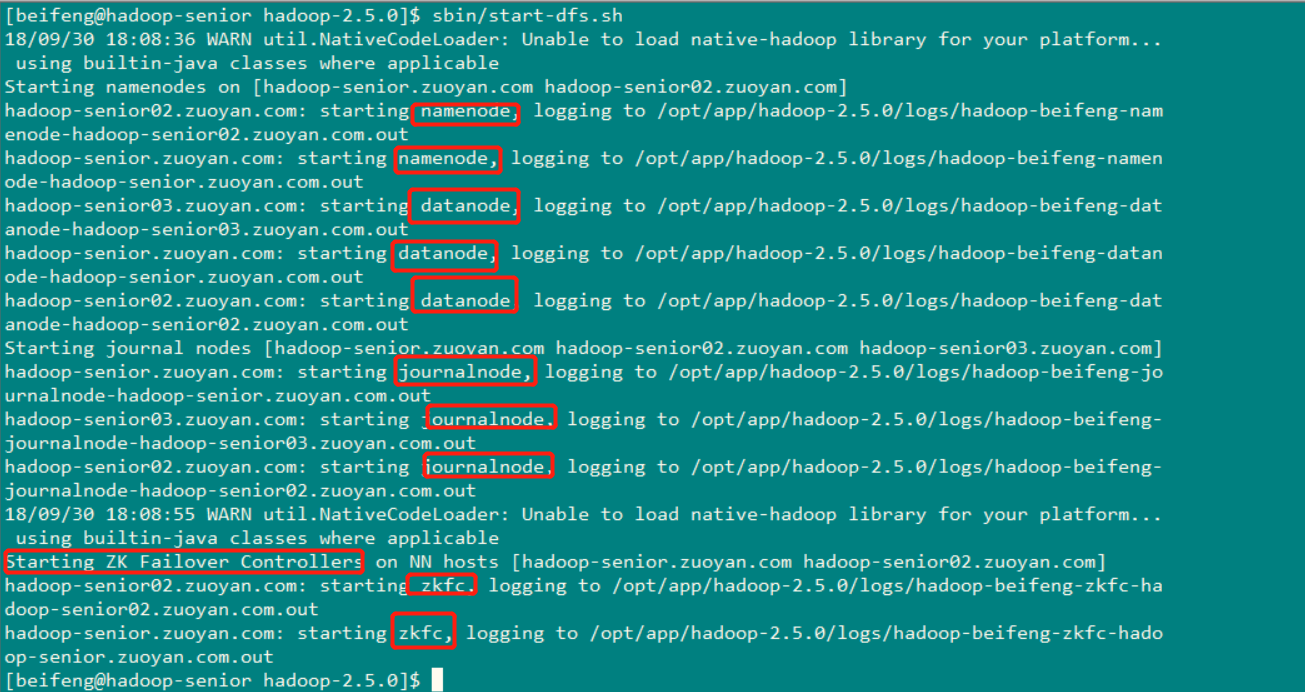
查看启动的服务
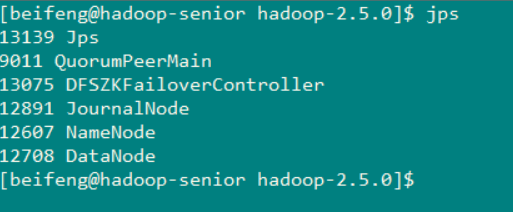
现在主节点 NameNode 和 Standby 的分布情况
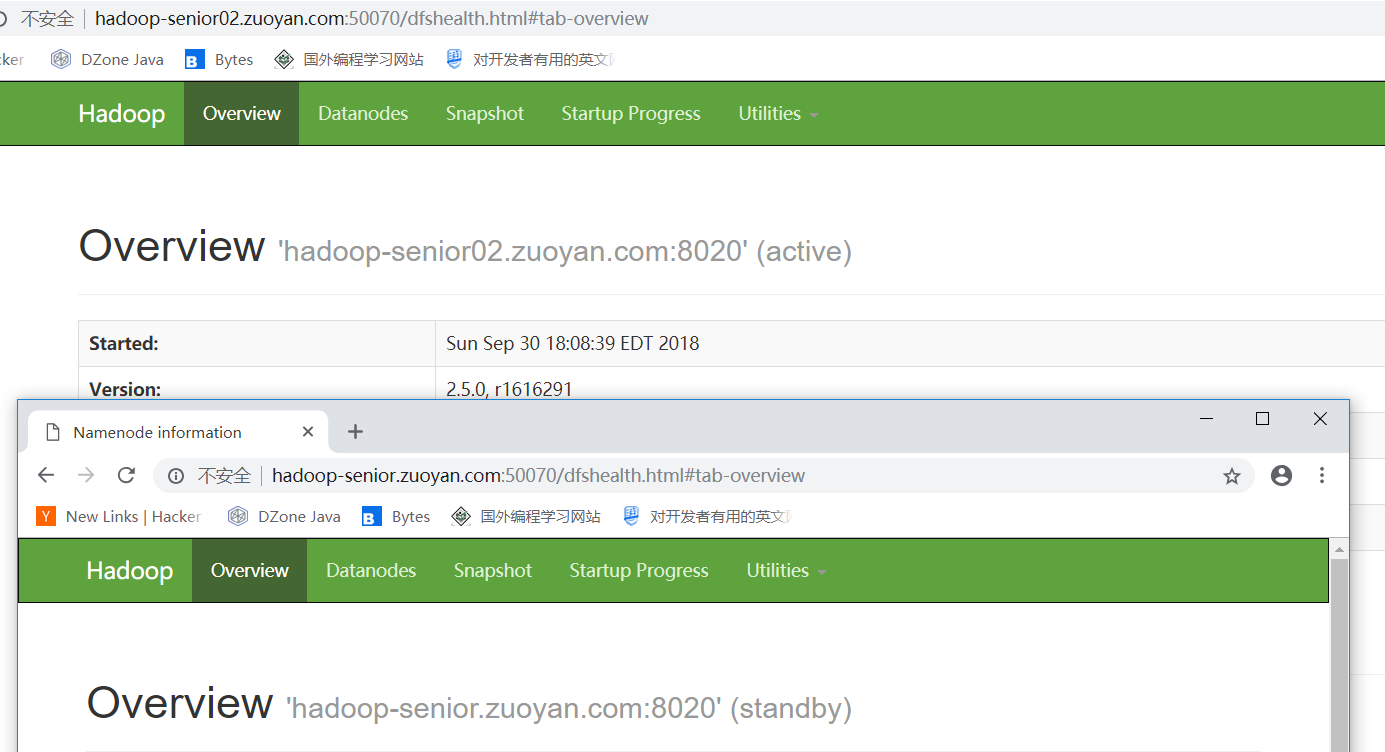
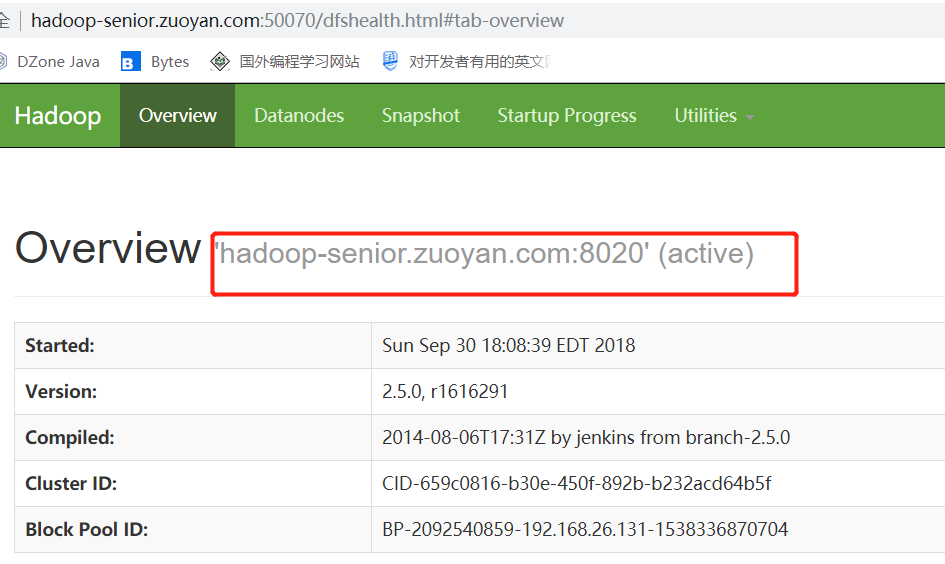
现在要结束掉Active的节点,检查他是否会自己进行故障转移
jps 查看一下任务运行的 id号 然后使用命令 kill -9 9991

然后去查看Hadoop-senior.zuoyan.com 是否成为了Active
注意:zookeeper 挂了 不会对集群造成影响,就是不能进行故障自动转移,
还有就是zookeeper 需要服务器的时间同步
这种HA的结构 是QJM
【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】的更多相关文章
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
- 3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一.说明 从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换: 接下来看一下用zookeeper进行自动故障转移: # 在启动HA之后,两个NameNode都是s ...
- MongoDB 主从复制及 自动故障转移
1.MongoDB 主从复制 MongoDB复制是将数据同步在多个服务器的过程. 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性. 复制还允许您从 ...
- (2)MongoDB副本集自动故障转移原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- (2)MongoDB副本集自动故障转移全流程原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- 非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法
非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法 环境:非域环境 因为是自动故障转移,需要加入见证,事务安全模式是,强安全FULL模式 做到最后一 ...
- keepalive配置mysql自动故障转移
keepalive配置mysql自动故障转移 原创 2016年02月29日 02:16:52 2640 本文先配置了一个双master环境,互为主从,然后通过Keepalive配置了一个虚拟IP,客户 ...
- Redis集群以及自动故障转移测试
在Redis中,与Sentinel(哨兵)实现的高可用相比,集群(cluster)更多的是强调数据的分片或者是节点的伸缩性,如果在集群的主节点上加入对应的从节点,集群还可以自动故障转移,因此相比Sen ...
随机推荐
- CSS选择符-----元素选择符
通配选择符(*) 选定所有对象 通配选择符(Universal Selector) 通常不建议使用通配选择符,因为它会遍历并命中文档中所有的元素,出于性能考虑,需酌情使用 & ...
- python windows安装 SQLServer pymssql,
1.到正儿八经的网站下载文件,找到适合自己的版本 2.把文件放到一个地方,能让pip找到就行, 不放scripts下面的话, 恐怕会报错“FileNotFoundError" 3. 走到pi ...
- PYQT5学习笔记之各模块介绍
Qtwidgets模块包含创造经典桌面风格的用户界面提供了一套UI元素的类 Qtwidegts下还有以下常用对象,所以一般使用Qtwidegts时会使用面向对象式编程 QApplication: ap ...
- c# 静态方法和数据
c#所有方法都必须在类的内部声明,但如果把方法或者字段声明为static就可以使用,类名代用方法或者访问字段. 在方法中声明一个静态变量a 和一个静态的aFun方法.下面是在主函数中调用. 从上图可以 ...
- Python+OpenCV图像处理(九)—— 模板匹配
百度百科:模板匹配是一种最原始.最基本的模式识别方法,研究某一特定对象物的图案位于图像的什么地方,进而识别对象物,这就是一个匹配问题.它是图像处理中最基本.最常用的匹配方法.模板匹配具有自身的局限性, ...
- JS 和 Jquery 的一些常用效果
https://www.cnblogs.com/beiz/tag/%E7%BD%91%E9%A1%B5%E5%B8%B8%E8%A7%81%E6%95%88%E6%9E%9C/ 北执
- 报文、http、https的理解
一.何为报文? 报文是网络中交换与传输的数据单位,即站点一次性要发送的数据块.报文包含了将要发送的完整的数据信息,其长短不一致,长度不限且可变. 二.报文的作用 报文多是多个系统之间需 ...
- 柳暗花明又一村的———for循环
学习过了do while循环和while循环后,我们终于剩下了循环结构重的最后一个-------for循环 本人认为for循环相比于do while ,while而言.好学一点下面就是我对for循环的 ...
- MyEclipse配置默认自带的HTML/JSP代码格式化
MyEclipse自带默认的HTML/JSP代码格式化并不适合个人开发习惯,因此特意配置如下: 设置行宽为:720(直接加10倍) 使用tabs缩进,单位:1 缩进标签元素要求删除: a开头:a. b ...
- react复习总结(2)--react生命周期和组件通信
这是react项目复习总结第二讲, 第一讲:https://www.cnblogs.com/wuhairui/p/10367620.html 首先我们来学习下react的生命周期(钩子)函数. 什么是 ...