L1与L2正则化
过拟合
机器学习中,如果参数过多、模型过于复杂,容易造成过拟合。
结构风险最小化原理
在经验风险最小化(训练误差最小化)的基础上,尽可能采用简单的模型,以提高模型泛化预测精度。
正则化
为了避免过拟合,最常用的一种方法是使用正则化,例如L1和L2正则化。
所谓的正则化,就是在原来损失函数的基础上,加了一些正则化项,或者叫做模型复杂度惩罚项。
L2正则化
L2正则化即:\(L=E_{in}+\lambda\sum_j\omega^2_j\),其中,\(E_{in}\)是原来的损失函数;\(\lambda\)是正则化参数,可调整;\(\omega_j\)是参数。
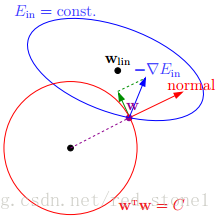
由上可知,正则化是为了限制参数过多,避免模型过于复杂。因此,我们可以令高阶部分的权重\(\omega\)为0,这样就相当于从高阶转换为低阶。然而,这是个NP难问题,将其适度简化为:\(\sum_j\omega_j^2≤C\),令\(\omega_j\)的平方和小于\(C\)。这时,我们的目标就转换为:令\(E_{in}\)最小,但是要遵循\(w\)平方和小于\(C\)的条件,如下图所示:
L1正则化
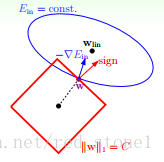
L1正则化和L2正则化相似:\(L=E_{in}+\lambda\sum_j|\omega_j|\),同样地,图形如下:
L1与L2正则化
满足正则化条件,实际上是求解上面图中红色形状与蓝色椭圆的交点,即同时满足限定条件和\(E_{in}\)最小化。
对于L2来说,限定区域是圆,这样得到的解\(\omega_1\)或\(\omega_2\)(以二元为例)为0的概率很小,且很大概率是非零的。
对于L1来说,限定区域是正方形,方形与蓝色区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,正方形的凸点会更接近 \(E_{in}\)最优解对应的\(\omega\)位置,而凸点处必有\(\omega_1\)或\(\omega_2\)为0。这样,得到的解\(\omega_1\)或\(\omega_2\)为零的概率就很大了。所以,L1正则化的解具有稀疏性。
扩展到高维,同样的道理,L2的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近\(E_{in}\)的最优解位置,而在这些凸点上,很多\(\omega_j\)为0。
参考链接
https://www.jianshu.com/p/76368eba9c90
https://segmentfault.com/a/1190000014680167?utm_source=tag-newest
https://blog.csdn.net/red_stone1/article/details/80755144
作者:@臭咸鱼
转载请注明出处:https://www.cnblogs.com/chouxianyu/
欢迎讨论和交流!
L1与L2正则化的更多相关文章
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- L1 与 L2 正则化
参考这篇文章: https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc https://blog. ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- day-17 L1和L2正则化的tensorflow示例
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数.L2范数也被称为权重衰 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- L1、L2正则化详解
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- tensorflow 中的L1和L2正则化
import tensorflow as tf weights = tf.constant([[1.0, -2.0],[-3.0 , 4.0]]) >>> sess.run(tf.c ...
随机推荐
- 《C语言程序设计》学习笔记(二)
第八章 函数 函数的基本概念 定义:函数由函数名.参数和函数体组成. 函数定义的一般形式: 类型说明符 函数名(形式参数声明) { [说明与定义部分] 语句: } 说明: 1.类型说明符用来说明函数的 ...
- Scapy 从入门到放弃
0x00 前言 最近闲的没事,抽空了解下地表最强的嗅探和收发包的工具:scapy.scapy是一个python模块,使用简单,并且能灵活地构造各种数据包,是进行网络安全审计的好帮手. 0x01 安装 ...
- 冲刺Noip2017模拟赛8 解题报告——五十岚芒果酱
1.鼎纹 [问题描述] 据说鼎纹的 种制造 式是 铜模印出来的,这是我国古代劳动 智慧 的结晶.铜模印过的地 ,会留下深深的印记,经过时间的炼化,洗 练成历史的遗存. 聪明的古代劳动人民拥有一个 a ...
- 乐字节Java学习01-Java语言概述,Java发展前景,Java的特点
从这篇文章开始,小乐准备写一整系列的Java学习文章,一步一步带您进入Java的神奇世界! 这是第一篇:Java语言概述以及Java的发展前景 1.SUN公司介绍 SUN公司全称是Stanford U ...
- 【牛客网】Longest Common Subsequence
[牛客网]Longest Common Subsequence 发现只有d数组最格路 于是我们把前三个数组中相同的数记成一个三维坐标,同一个数坐标不会超过8个 从前往后枚举d,每次最多只会更新不超过8 ...
- python Django基础操作
Django常用命令 创建Django项目 Django-admin startprotect mysite 创建项目以后,以下生成的文件 最外层的file:mysite/ 根目录只是你的项目的容器 ...
- 03 HttpServletRequest_HttpServletResponse
HttpServletRequest:一次来自客户端的请求的相关信息 请求行 request.getMethod() 获取http请求方式 request.getRequestURI() 获取统一资源 ...
- MySQL 触发器的使用
MySQL 基础篇 三范式 MySQL 军规 MySQL 配置 MySQL 用户管理和权限设置 MySQL 常用函数介绍 MySQL 字段类型介绍 MySQL 多列排序 MySQL 行转列 列转行 M ...
- [Vue]Vue keep-alive
keep-alive 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们.和 <transition> 相似,<keep-alive> 是一个抽象组件:它自身不会渲染一个 ...
- Thymeleaf 模板使用 Error resolving template "/home", template might not exist or might not be accessible by any of the
和属性文件中thymeleaf模板的配置相关 1.配置信息 spring.thymeleaf.prefix=classpath:/templates/ spring.thymeleaf.suffix= ...