python网络爬虫(5)BeautifulSoup的使用示范
创建并显示原始内容
其中的lxml第三方解释器加快解析速度
import bs4
from bs4 import BeautifulSoup
html_str = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2"><!-- Lacie --></a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_str,'lxml')
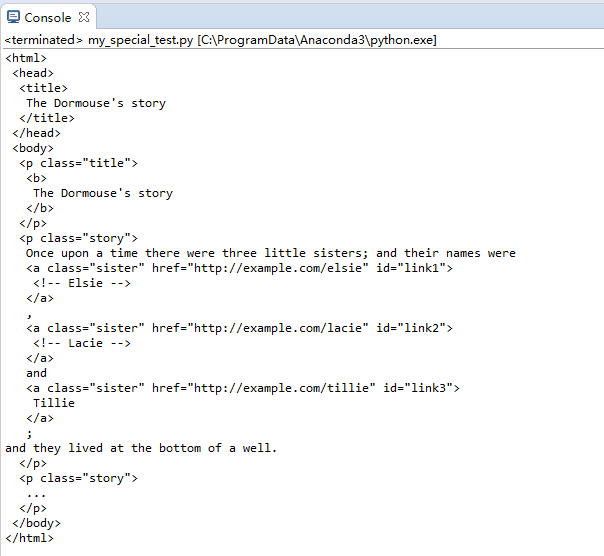
print(soup.prettify())
控制台显示出soup需要处理的内容:
提取对象内容和属性
搜索包括了所有的标签。默认提取第一个符合条件的标签。
提取Tag对象
其中,name用于显示标签名,去掉name则内容直接显示。
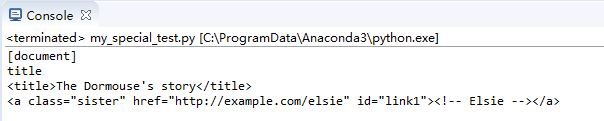
print(soup.name)
print(soup.title.name)
print(soup.title)
print(soup.a)
控制台输出效果如下:
显示属性
attrs用于显示属性。class用于显示选中的标签Tag中的类名。
print(soup.p['class'])
print(soup.p.attrs)
输出结果:

内容文字
显示标记中的文字,NavigableString类型
print(soup.p.string)
print(type(soup.p.string))
效果:

显示注释
显示注释内容,注意与普通string的区别在于最后的类,用于数据分类
print(soup.a.string)
print(type(soup.a.string))

文档相关结点
直接子节点数组
结点中的contents输出直接子节点数组,可以通过for逐个输出,通过string属性直接输出内容
print(soup.body.contents)
输出body标签下的直接子节点:

结点children输出直接子节点,和contents类似。不一样的是返回了生成器,一点参考:https://www.cnblogs.com/wj-1314/p/8490822.html
for i in soup.body.children:
print(i,end='')
添加了end=''用于去掉print的自动换行
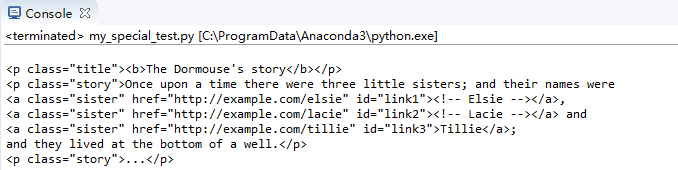
子、孙节点
结点descendants可以输出子节点和孙节点
for i in soup.body.descendants:
print(i)
效果:
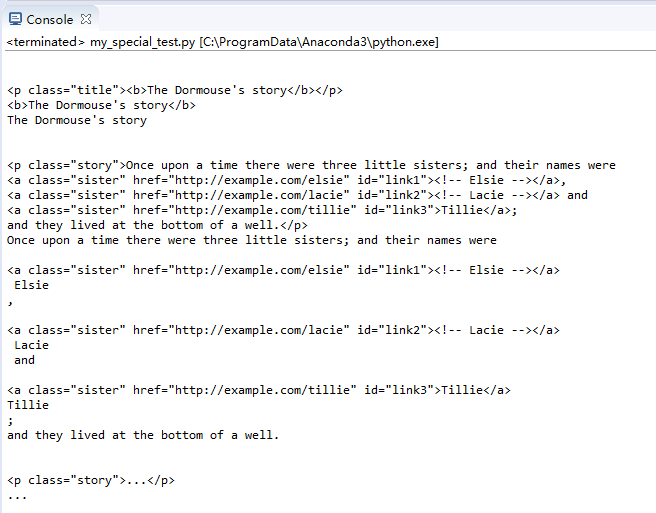
节点strings输出全部子节点内容值
print(soup.strings)
print('------------------------')
for text in soup.strings:
print(text,end='')
效果:
节点stripped_strings输出全部内容并去掉回车和空格
for text in soup.stripped_strings:
print(text)
print每次输出加上换行后,效果:
父节点相关
父节点parent
print(soup.title)
print(soup.title.parent)
效果:

父辈节点parents,这里只输出名字就好了,否则内容过多
for i in soup.a.parents:
print(i.name)
效果:
兄弟节点等
兄弟节点next_sibling,previous_sibling,另有 :next_siblings,previous_siblings
print(soup.p.next_sibling.next_sibling)
print(soup.p.previous_sibling)
效果:
前后节点:next_element,next_elements等......
BeautifulSoup的搜索方法
包括了find_all,find,find_parents等等,这里只举例find_all。
find_all中参数name查找名称标记
查找所有b标签
print(soup.find_all('b'))
输出:
查找所有b开头的标签
配合正则表达式使用
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
输出:
查找a开头和b开头的标签
print(soup.find_all(["a", "b"]))
输出:(一个数组,过长)
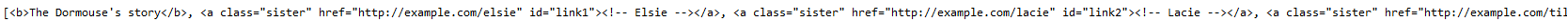
查找所有标签,True可以匹配任何值
for tag in soup.find_all(True):
print(tag.name)
输出:

自定义过滤
查找含有class和id属性的Tag标签
def hasClass_Id(tag):
return tag.has_attr('class') and tag.has_attr('id')
print(soup.find_all(hasClass_Id))
效果:
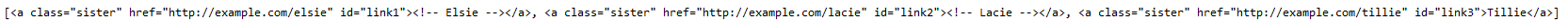
查找关键词参数kwargs并输出
查找id参数为link2的标签
print(soup.find_all(id='link2'))
输出:
查找链接中含有elsie的标签
配合正则表达式
print(soup.find_all(href=re.compile("elsie")))
输出:
查找所有有id属性的标签
print(soup.find_all(id=True))
输出:
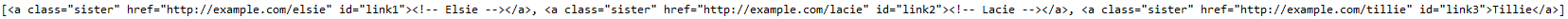
查找所有a标签且class内容为sister
print(soup.find_all("a", class_="sister"))
输出:
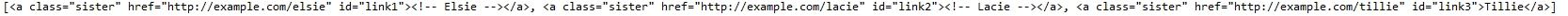
查找所有链接含有elsie的标签,id为link1
print(soup.find_all(href=re.compile("elsie"), id='link1'))
输出:
不能表达的属性的解决方案
在html5中有些属性不被支持,查找时,通过定义字典实现输出
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>','lxml')
print(data_soup.find_all(attrs={"data-foo": "value"}))
输出: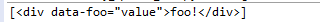
通过text参数查找文本内容并过滤
输入:
print(soup.find_all(text=["Tillie", "Elsie", "Lacie"]))
print(soup.find_all(text=re.compile("Dormouse")))
输出:
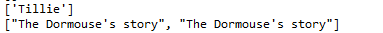
通过limit参数限制查找数量
输入:
print(soup.find_all("a", limit=2))
输出只有两个:

通过recursive参数只查找直接子节点
soup位于根处
print(soup.find_all("title"))
print(soup.find_all("title", recursive=False))
输出:

使用CSS选择器查找
#直接查找title标签
print soup.select("title")
#逐层查找title标签
print soup.select("html head title")
#查找直接子节点
#查找head下的title标签
print soup.select("head > title")
#查找p下的id="link1"的标签
print soup.select("p > #link1")
#查找兄弟节点
#查找id="link1"之后class=sisiter的所有兄弟标签
print soup.select("#link1 ~ .sister")
#查找紧跟着id="link1"之后class=sisiter的子标签
print soup.select("#link1 + .sister") print soup.select(".sister")
print soup.select("[class~=sister]") print soup.select("#link1")
print soup.select("a#link2") print soup.select('a[href]') print soup.select('a[href="http://example.com/elsie"]')
print soup.select('a[href^="http://example.com/"]')
print soup.select('a[href$="tillie"]')
print soup.select('a[href*=".com/el"]')
输出:

python网络爬虫(5)BeautifulSoup的使用示范的更多相关文章
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- 《实战Python网络爬虫》- 感想
端午节假期过了,之前一直在做出行准备,后面旅游完又休息了一下,最近才恢复状态. 端午假期最后一天收到一个快递,回去打开,发现是微信抽奖中的一本书,黄永祥的<实战Python网络爬虫>. 去 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
随机推荐
- Android学习_Selector
Selector 实现组件在不同状态下不同的文字颜色.背景颜色或图片的切换,使用十分方便. 1. 创建方法 第一种:在XML中直接创建selector的XML文件,容易掌握,简单但是不灵活,较为常用. ...
- 设置PyCharm中选择文本的背景颜色和代码中和选中单词相同单词的背景颜色
1 设置选中单词的背景颜色 首先进入File->Setting->Editor->Color Scheme后复制一个存在的颜色主题作为自定义的颜色主题(默认的颜色主题是无法修改的,也 ...
- Caused by: java.lang.IllegalStateException: Unable to complete the scan for annotations for web application [/Cppcc] due to a StackOverflowError. Possible root causes include a too low setting for -Xs
解决办法:(1)修改D:\Java\apache-tomcat-7.0.88\conf\catalina.properties (122line) (2)如org.apache.catalina.st ...
- Word文档怎么从第二页加页码
1.首先将光标放到首页的最后位置 2.“页面布局”—“分隔符”—“下一页” 3.“插入”—“页码”—选一种样式的页码 4.将光标定位到第二页的页脚处,“设计”—取消“链接到前一条页眉” 5.将第二页的 ...
- pycharm创建.py文件时,自动添加头文件注释
File->settings->Editor->Code Templates->Python Script 添加以下代码: #!/usr/bin/env python # -* ...
- pandas-赋值操作
1,pandas操作主要有对指定位置的赋值,如上一篇中的数据选择一样,根据loc,iloc,ix选择指定位置,直接赋值 2,插入,insert方法,插入行和列 3,添加 4,删除 drop方法 5,弹 ...
- jdk1.8-Vector
一:先看下类的继承关系 UML图如下: 继承关系: ))) ))) grow(minCapacity)) ? ) newCapacity = minCapacity) ) , elementData, ...
- ubuntu安装软件失败,出现404错误,更新软件源
更新源方法 备份原来的源 首先备份原来的源,用来出错后进行恢复 sudo cp /etc/apt/sources.list/etc/apt/sources.list_backup 1 如果更新源后出错 ...
- 安装 Git 并连接 Github
下载安装 Git, 下载地址:https://git-scm.com/download/win . 在命令行中输入 git 测试 Git 是否安装成功. 在桌面鼠标右击打开 Git Bash Here ...
- 【DSP开发】TI第二代KeyStone SoC诠释德仪的“云”态度
11月14日,期盼已久的德州仪器基于ARM Cortex-A15的产品终于新鲜出炉.伴随着TIKeyStone II多核 SoC系列产品的发布,结合了ARM Cortex-A15 处理器.C66x D ...