pandas实现hive的lag和lead函数 以及 first_value和last_value函数
lag和lead VS shift
该函数的格式如下:
- 第一个参数为列名,
- 第二个参数为往上第n行(可选,默认为1),
- 第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
lag
lag(字段名,N,默认值) over(partition by 分组字段 order by 排序字段 排序方式)
lead
lead(字段名,N,默认值) over(partition by 分组字段 order by 排序字段 排序方式)
案例:
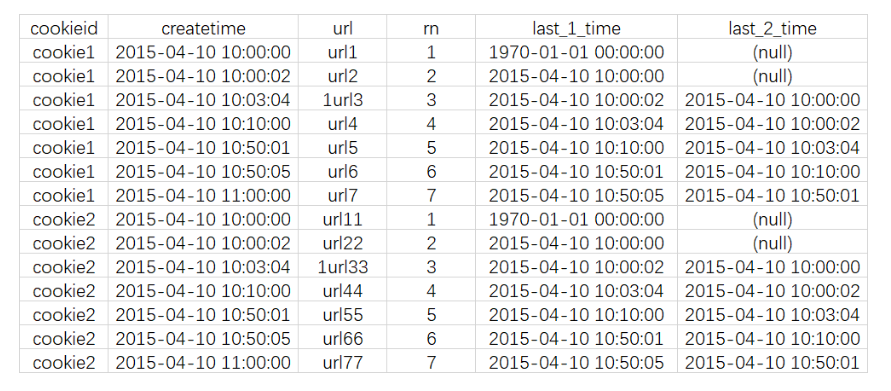
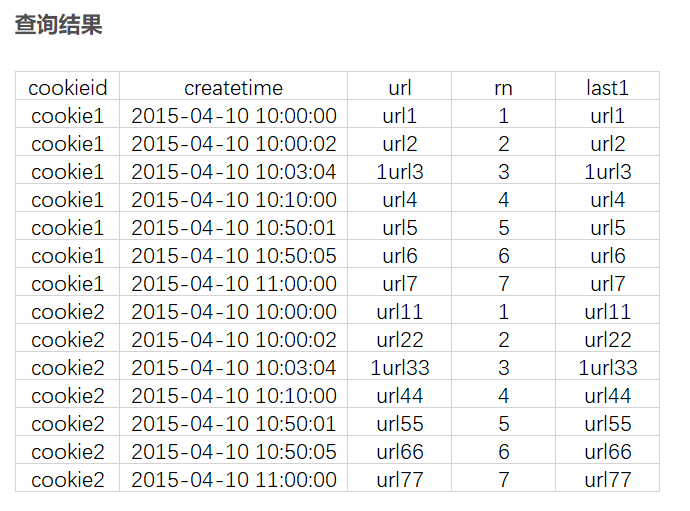
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LAG(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as last_1_time,
LAG(createtime,2) over (partition by cookieid order by createtime) as last_2_time
from cookie.cookie4
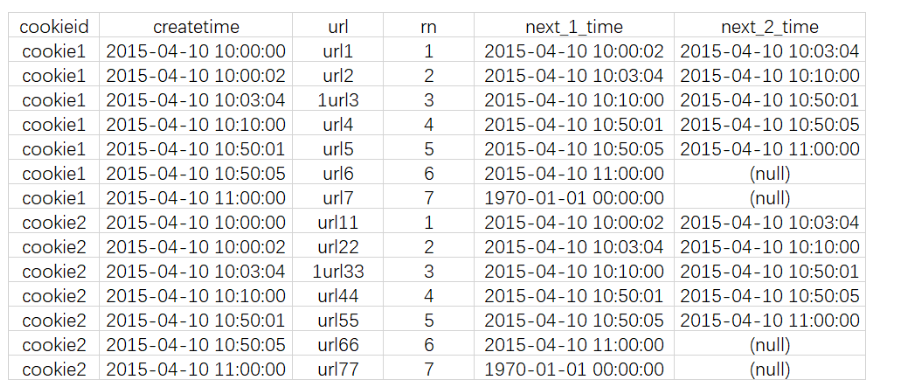
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
LEAD(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as next_1_time,
LEAD(createtime,2) over (partition by cookieid order by createtime) as next_2_time
from cookie.cookie4;
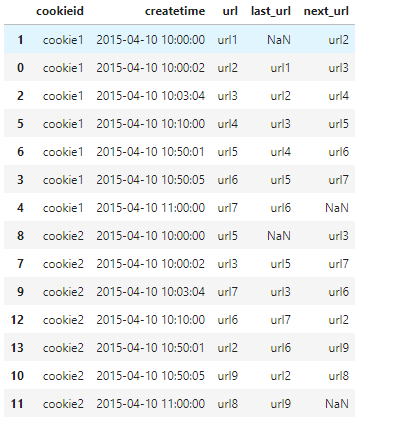
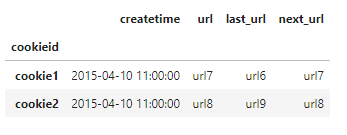
窗口函数的pandas实现
pandas中使用shift函数来实现lag/lead函数
import pandas as pd
df=pd.read_csv('c:/Users/WQBin/Desktop/data.csv',engine='python', names=['cookieid','createtime','url'])
df['last_url'] = df.sort_values('createtime').groupby('cookieid')['url'].shift(1)
df['next_url'] = df.sort_values('createtime').groupby('cookieid')['url'].shift(-1)
df.sort_values(by=['cookieid','createtime'])
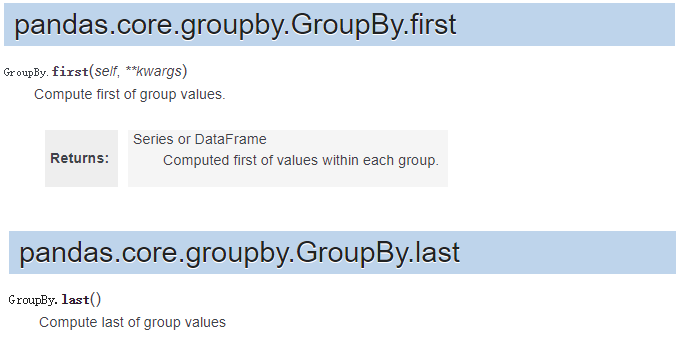
first_value和 last_value VS first()和last()
- FIRST_VALUE 返回组中数据窗口的第一个值
- FIRST_VALUE ( [scalar_expression )OVER ( [ partition_by_clause ] order_by_clause )
- LAST_VALUE 返回组中数据窗口的最后一个值
- LAST_VALUE ( [scalar_expression )OVER ( [ partition_by_clause order_by_clause )
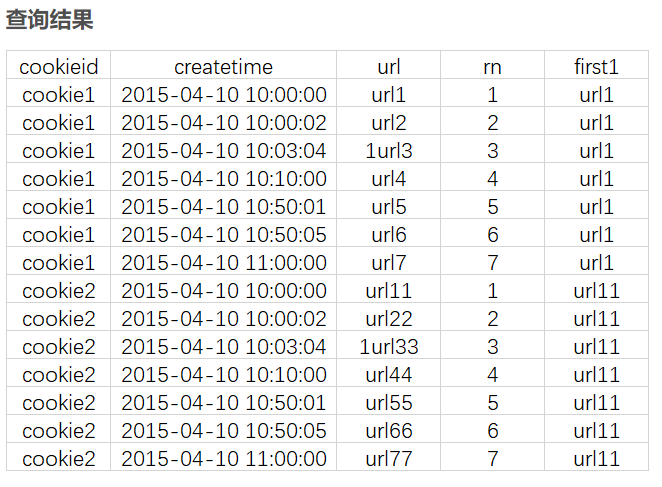
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
first_value(url) over (partition by cookieid order by createtime) as first1
from cookie.cookie4;
select
cookieid,
createtime,
url,
row_number() over (partition by cookieid order by createtime) as rn,
last_value(url) over (partition by cookieid order by createtime) as last1
from cookie.cookie4;
窗口函数的pandas实现
df.sort_values(['createtime'], ascending=[ 1]).groupby(['cookieid']).first()

df.sort_values(['createtime'], ascending=[ 1]).groupby(['cookieid']).last()
pandas实现hive的lag和lead函数 以及 first_value和last_value函数的更多相关文章
- SQL Server ->> FIRST_VALUE和LAST_VALUE函数
两个都是SQL SERVER 2012引入的函数.用于返回在以分组和排序后取得最后一行的某个字段的值.很简单两个函数.ORDER BY字句是必须的,PARITION BY则是可选. 似乎没什么好说的. ...
- Hive分析窗体函数之LAG,LEAD,FIRST_VALUE和LAST_VALUE
环境信息:Hive版本号为apache-hive-0.14.0-binHadoop版本号为hadoop-2.6.0Tez版本号为tez-0.7.0 创建表: ),第三个參数为默认值(当往上第n行为NU ...
- ORACLE lag()与lead() 函数
一.简介 lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤.这种 ...
- Hive窗口函数之LAG、LEAD、FIRST_VALUE、LAST_VALUE的用法
一.创建表: create table windows_ss ( polno string, eff_date string, userno string ) ROW FORMAT DELIMITED ...
- KingbaseES lag 和 lead 函数
1.简介 lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤. 2 ...
- Hive学习之路 (十六)Hive分析窗口函数(四) LAG、LEAD、FIRST_VALUE和LAST_VALUE
数据准备 数据格式 cookie4.txt cookie1, ::,url2 cookie1, ::,url1 cookie1, ::,1url3 cookie1, ::,url6 cookie1, ...
- oracle中LAG()和LEAD()等分析统计函数的使用方法(统计月增长率)
LAG()和LEAD()统计函数能够在一次查询中取出同一字段的前N行的数据和后N行的值.这样的操作能够使用对同样表的表连接来实现,只是使用LAG和 LEAD有更高的效率.下面整理的LAG()和LEAD ...
- oracle lag与lead分析函数简介
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数我们可以取到当前行列的偏移N行列的值 lag可以看着是正的向上的偏移 lead可以认为负的向下的偏移 具体我们来看几个例子: 我们先看下 ...
- oracle中LAG()和LEAD()以及over (PARTITION BY)
LAG()和LEAD()统计函数可以在一次查询中取出同一字段的前N行的数据和后N行的值.这种操作可以使用对相同表的表连接来实现,不过使用LAG和 LEAD有更高的效率.以下整理的LAG()和LEAD( ...
随机推荐
- Linux安装 PostgreSQL
1.在线安装 yum install postgresql-server -y 2.初始化数据库 service postgresql initdb 3.设置自动启动 hkconfig postgre ...
- c++语法笔记(下)
多态性与虚函数 多态性(函数重载,运算符重载就是多态性现象)多态性 :向不同对象发送同一个消息,不同对象在接收时会产生不同的行为.(每个对象用自己的方式去响应共同的消息)多态性又可以分为静态多态性和动 ...
- 剑指offer36:两个链表的第一个公共结点
1 题目描述 输入两个链表,找出它们的第一个公共结点. 2 思路和方法 方法一: 用两个指针同时从两个链表的表头开始走,当走到自己的链表结尾的时候开始从另一个链表的表头开始向后走.终止条件就是两个指针 ...
- php 之分页
$a=$_FILES; // print_r($a);die; foreach ($a as $key => $value) { $k=$key; } // $_FILES['license'] ...
- Python turtle(介绍一)
关于绘制图形库turtle # 画布上,默认有一个坐标原点为画布中心的坐标轴(0,0),默认"standard"模式坐标原点上有一只面朝x轴正方向小乌龟 一:海龟箭头Turtle相 ...
- python中内存地址
遇到一个朋友,给我提了一个问题:python中的两个相同的值,内存地址是否一样? 当时印象里有这样一句话:Python采用基于值的内存管理模式,相同的值在内存中只有一份 于是张嘴就说是一样的 朋友说不 ...
- gmpy安装使用方法
gmpy是一种C编码的Python扩展模块,提供对GMP(或MPIR)多精度算术库的访问.gmpy 1.17是1.x系列的最终版本,没有进一步的更新计划.所有进一步的开发都在2.x系列(也称为gmpy ...
- 多节点bigchaindb集群部署
文章比较的长,安装下来大概4个小时左右,我个人使用的服务器,速度会快一点. 安装环境 ostname ip os node-admin 192.168.237.130 ubuntu 18.04.2 d ...
- cnn健康增胖和调理好身体
吃不胖,其实大部分情况是消化系统不好,大部分食物都没有被身体吸收就被排掉了. 1,改善肠胃消化功能: 每天早上一杯全脂鲜牛奶(或者羊奶), 每天晚上一杯酸奶 ps:白天和鲜牛奶可以激发肠胃的消化能力. ...
- Apache ---- Solrl漏洞复现
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过Http Get操 ...