31. ClustrixDB 分布式架构/查询优化器
ClustrixDB查询优化器有何不同
ClustrixDB查询优化器的核心是能够执行一个具有最大并行性的查询和多个具有最大并发性的并发查询。这是通过分布式查询规划器和编译器以及分布式无共享执行引擎实现的。
什么是查询优化器?
SQL是一种声明性语言,即一种描述要计算什么但不描述如何计算的语言。查询优化器的工作是确定如何进行此计算,这对整个系统的性能至关重要。例如,您可能会在SQL中说希望联接3个表并计算一个聚合操作。这给查询优化器留下了以下问题:
- 以什么顺序表应该加入吗?这可以查询执行的区别在1 ms或10分钟。想象一下如果一个谓词的表原因它不返回行——开始读取表可能最佳的和快速的。
- 应该使用哪个指标?不使用一个适当的索引连接约束将是灾难性的,导致广播消息和完整的读取的第二个表的每一行。
- 我们应该提供一种非阻塞/总吗?我们应该做那种/聚合阶段,即首先在单独的节点,然后re-aggregate /排序后?、
这些排列所创建的查询计划集称为搜索空间。查询优化器的工作是探索搜索空间并确定哪个计划使用的数据库资源最少。通常,这是通过为每个计划分配成本,然后选择最便宜的一个来实现的。
ClustrixDB查询优化器也称为Sierra。
例子:
sql> -- Query
sql> SELECT Bar.a,
Sum(Bar.b)
FROM Foo, Bar
WHERE Foo.pk = Bar.pk
GROUP BY Bar.a; sql> -- Foo schema
sql> CREATE TABLE `Foo`
( `pk` INT() NOT NULL auto_increment,
`a` INT(),
`b` INT(),
`c` INT(),
PRIMARY KEY (`pk`) /*$ DISTRIBUTE=1 */,
KEY `idx_ab` (`a`, `b`) /*$ DISTRIBUTE=2 */
) auto_increment=; sql> -- Bar schema
sql> CREATE TABLE `Bar`
( `pk` INT() NOT NULL auto_increment,
`a` INT(),
`b` INT(),
`c` INT(),
PRIMARY KEY (`pk`) /*$ DISTRIBUTE=1 */,
KEY `idx_ab` (`a`, `b`) /*$ DISTRIBUTE=2 */
) auto_increment=;
|
SQL Representation – What
|
Sierra Output – How
|
|---|---|
(display ((2 . "a") (0 . "expr0")) |
(display ((2 . "a") (0 . "expr0")) |
| Diagram 1 |
首先,对这些计划做一些解释。我们会从最缩进到最不缩进。对于同样缩进的语句,应该从头到尾阅读这些描述。
这个SQL语句执行以下操作:
- 读取表Foo并连接到Bar。
- 计算连接约束。
- 计算聚合。
- 向用户显示输出。
查询优化是做以下:
- 读取表栏,通过stream_merge保持排序顺序。
- 在读取Foo时计算连接约束,并且这次仍然通过msjoin保持排序顺序。
- 使用stream_aggregate以非阻塞方式计算聚合。这是可以做到的,因为我们保持了秩序。
查询优化器如何找到这个计划?它是如何确保工作的呢?可以发现:
ClustrixDB查询优化器
Sierra是模仿Cascades查询优化框架,之所以选择它,主要是因为它提供了以下功能:
- 成本驱动
- 可通过基于规则的机制进行扩展
- 自顶向下方法
- 逻辑操作符与物理操作符和属性的一般分离
- 修剪
现代的查询优化器通常分为两部分:模型和搜索引擎。
该模型列出了等价转换(规则),搜索引擎使用它们来扩展搜索空间。
搜索引擎定义搜索引擎和模型之间的接口,并提供扩展搜索空间和搜索最优计划的代码。这是通过等待计算的任务堆栈实现的。下面将对此进行详细介绍。
术语
逻辑模型与物理模型
在查询优化器中,逻辑模型描述要计算的内容,而物理模型描述如何计算。在上面的图1中,SQL表示在逻辑上显示要做什么,Sierra输出在物理上显示如何做。
操作符和表达式
表达式包括:操作符(required)、参数(可能没有)和输入(可能没有)。参数描述了操作符的特殊特征。有逻辑操作符和物理操作符,每个逻辑操作符都映射到一个或多个物理操作符。在这个例子中,逻辑运算符:
(table_scan ( : Foo ("pk" "a" "b" "c")))
映射到物理表达式:
(index_scan ( : Foo ("pk") (range equal (ref ( . "pk")))
这些操作符的参数描述了它们的名称空间、对象Id和列。这里,table_scan没有输入,index_scan有一个表示连接约束的输入。(详见计划员操作人员列表)
物理性质
物理性能与中间结果或子计划相关。它们描述诸如数据如何排序和数据如何分区之类的内容。需要注意的是表达式(逻辑的或物理的)和组(见下面)没有物理属性。然而,每个物理表达式都有两个与物理属性相关的描述:
哪些物理特性我可以提供,哪些不能提供给我的上级?
我要求输入的物理性质是什么?
以下是Sierra在优化我们的查询时的一些注意事项:
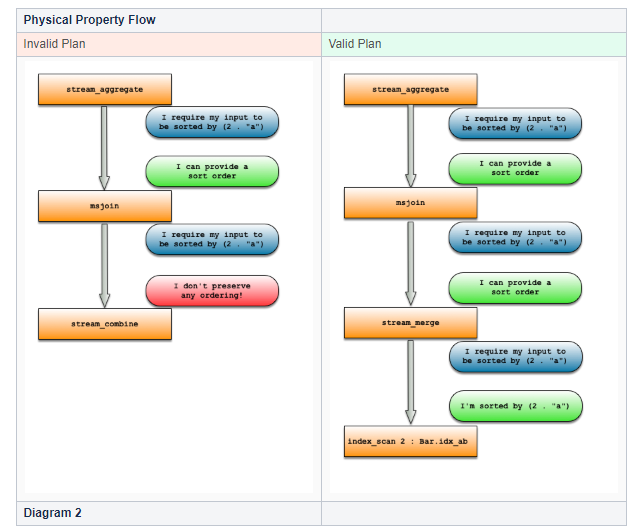
无效的计划失败是因为stream_combine操作符无法保持其输入提供的任何类型的顺序。但是,在有效的计划中使用了stream_merge,它可以保留其子计划的排序顺序,而index_scan本身确实有排序顺序。实际上,研究可能有效也可能无效的计划,并使用物理特性来验证它们是否可行。如果链中的任何操作符失败,则该计划无效。
组
组对应于中间表,或相当于查询的子计划。组是逻辑的,包含以下内容:
- 描述中间表的所有逻辑等价表达式。
- 这些逻辑表达式的所有物理实现。
- 赢家:在给定一组物理特性的情况下,成本最高的物理表达式。
- 逻辑属性:需要生成哪些列以及关于这些列的统计信息。
组是Sierra的基本数据结构。操作符的输入总是组(由组#的s表示),每个表达式都对应于某个组。
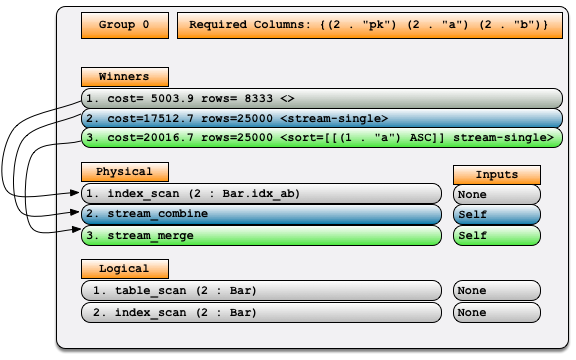
备忘录
在优化过程中,Sierra会跟踪计算最终结果表中可能用到的中间表。每一个都对应一个组,一个计划的所有组的集合定义了备忘录。在Sierra中,memo被设计为表示给定初始查询的搜索空间中的所有逻辑查询树和物理计划。备忘录是一组组,其中一个组指定为最终组(或顶部组)。这是对应于初始查询求值结果表的组。Sierra没有明确表示所有可能的查询树,部分原因是查询树太多了。相反,这个备忘表示所有可能的查询树的精简版本。
规则(模型)
可以将模型的规则集视为定义优化器的逻辑和物理搜索空间。备忘录通过规则的应用扩展了整个逻辑和物理搜索空间。规则的应用是一个多步骤的过程,包括在memo中查找绑定、评估规则条件(如果规则有)和触发规则(如果满足条件),这将在memo中添加新的表达式。当优化器完成应用规则时,memo结构将被扩展到概念上表示整个搜索空间的地方。下面是swap_rule触发的一个示例。它负责研究在示例的最终计划中选择的连接顺序。
|
Swap Join Order Rule
|
|
|---|---|
(display ((1 . "pk") (2 . "pk") (inner_join (index_scan (1:Foo ("pk")))
(index_scan (2:Bar ("pk"))
(range_equal ref (1 . "pk")))) |
(display ((1 . "pk") (2 . "pk") (inner_join (index_scan (2:Bar ("pk"))
(index_scan (1:Foo ("pk")))
(range_equal ref (2 . "pk")))) |
| Diagram 4 |
任务(搜索引擎)
Sierra的搜索引擎是一系列等待计算的任务。在优化期间的任何时刻,都有任务等待堆栈执行。每个任务可能会将更多的任务推入堆栈,以便能够实现其目标。一旦堆栈为空,Sierra就完成了计算。Sierra首先获取一个输入树并构造相应的初始组和表达式。然后,它通过推送任务Optimize_group (top group)启动搜索引擎。这从探索整个搜索空间的事件链开始,为每个组找到最便宜的获胜者,并最终选择最便宜的获胜者作为其输出计划。
|
The Search Engine
|
|---|
 |
| Diagram 5 |
成本模型
Sierra使用I/O、CPU使用和延迟的组合来消耗计划。请记住,ClustrixDB是分布式的,所以总的CPU使用量和延迟不是成比例的。每个运算符描述一个函数,以便根据输入计算它的代价。例如,index_scan使用行估计框架来计算它期望从btree中读取多少行,然后计算其成本如下:
index_scan.rows = row_est()
index_scan.cost = cost_open + row_est() * cost_read_row
然后,index_scan上面的操作符将使用这个成本和行估计来估计它自己的成本。
行估计
Sierra为查询选择最佳计划的方法是找到成本最低的计划。成本在很大程度上取决于优化器认为将流经系统的行数。行估计子系统的工作是从我们的概率分布中获取统计信息,并计算一个给定表达式的估计行数。
执行计划
对于上面的查询,我们可以通过在查询前面加上“explain”来获得计划、行估计和成本的简明描述。(有关更多信息,请参见理解ClustrixDB解释输出。)
sql> explain select bar.a, sum(bar.b) from bar,foo where foo.pk = bar.pk group by bar.a;
+-------------------------------------------------------------+-----------+-----------+
| Operation | Est. Cost | Est. Rows |
+-------------------------------------------------------------+-----------+-----------+
| stream_aggregate GROUPBY(( . "a")) expr0 := sum(( . "b")) | 142526.70 | 25000.00 |
| msjoin KEYS=[(( . "a")) GROUP] | 137521.70 | 25000.00 |
| stream_merge KEYS=[( . "a") ASC] | 20016.70 | 25000.00 |
| index_scan := bar.idx_ab | 5003.90 | 8333.33 |
| index_scan := foo.__idx_foo__PRIMARY, pk = .pk | 4.50 | 1.00 |
+-------------------------------------------------------------+-----------+-----------+
rows in set (0.01 sec)
总结
为了总结Sierra如何得到图1中的输出,我们执行了以下步骤:
- Sierra创建了许多与图1的SQL表示相对应的组和表达式。
- 以按需方式通过任务机制Sierra然后:
- 触发规则以扩展查询的逻辑和物理搜索空间,创建额外的组和表达式,其中一些可能与任何有效的计划不对应。
- 使用物理属性将搜索空间缩小到有效的计划。
- 使用成本模型,以确定最便宜的计划从一组给定的物理属性为每个组。
- 在处理完所有任务之后,Sierra提取了与top组获胜者对应的查询计划,这是图1的输出。
分布式的考虑
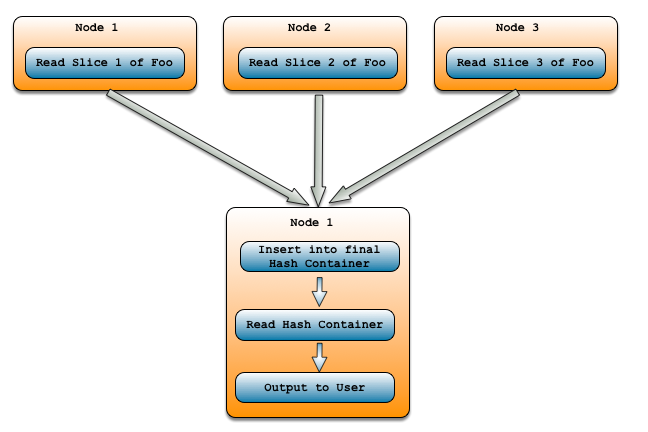
我们已经讨论了很多关于查询优化器如何找到最佳计划的内容,但是到目前为止,这些概念并不是ClustrixDB独有的。Sierra的一个特别之处在于它能够对分布式操作进行推理。例如,有两种计算聚合的方法。让我们先来了解一下非分布式方式:
- 读取Foo表,它可能有多个节点上的片。
- 将所有这些行转发到一个节点。
- 将所有这些行插入到散列容器中,必要时计算聚合操作。
- 读取容器并输出给用户。
它是这样的:
但实际上,我们可以把集合分配,然后这样做:
- 计算子计划(在聚合项下),它可能在多个节点上有结果行。
- 在本地将这些行插入到本地散列容器中,必要时计算聚合操作。
- 读取每个节点上的散列容器并转发到单个节点。
- 如果有必要:
- 将所有这些行插入到一个新的最终散列容器中,计算聚合操作。
- 读取那个散列容器。
- 向用户输出行。
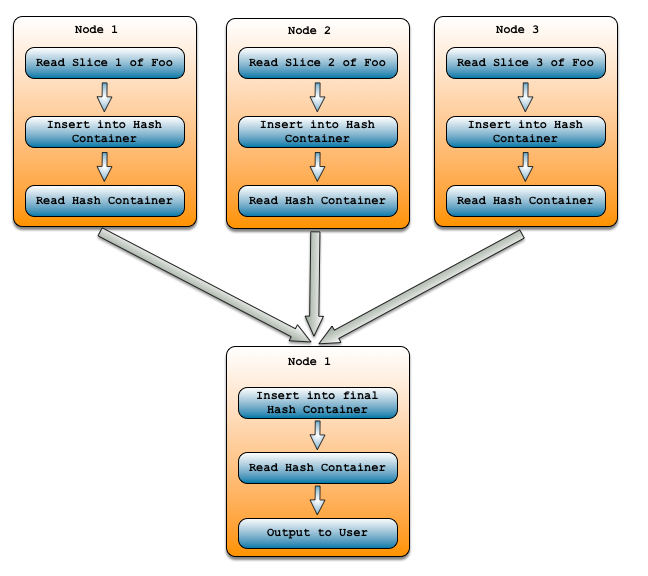
对Sierra来说,问题是哪个更好,什么时候更好?事实证明,分布聚合的收益实际上来自这样一个事实,即我们通过网络(节点之间)发送的数据可能要少得多,因此,当聚合操作的缩减因子较大时,额外插入和容器的开销就变得值得了。Sierra能够通过成本模型来推断出这一点,并为任何查询确定更好的方法。有关其他信息,请参见缩放聚合。
31. ClustrixDB 分布式架构/查询优化器的更多相关文章
- 29. ClustrixDB 分布式架构/并发控制
介绍 ClustrixDB使用多版本并发控制(MVCC)和2阶段锁(2PL)的组合来支持混合的读写工作负载.在我们的系统中,读取器享受无锁快照隔离,而写入器使用2PL来管理冲突.并发控制的组合意味着读 ...
- 28. ClustrixDB 分布式架构/评估模型
本节描述如何在数据库中计算查询.在ClustrixDB中,我们跨节点切片数据,然后将查询发送到数据.这是数据库的基本原则之一,它允许随着添加更多节点而几乎线性地扩展. 有关如何分布数据的概念,请参阅数 ...
- 26. ClustrixDB 分布式架构/数据分片
数据分片 介绍 共享磁盘vs.无共享 分布式数据库系统可分为两大类数据存储架构:(1)共享磁盘和(2)无共享. Shared Disk Architecture Shared Nothing Arch ...
- 27. ClustrixDB 分布式架构/一致性、容错和可用性
一致性 许多分布式数据库都采用最终一致性而不是强一致性来实现可伸缩性.但是,最终的一致性会增加应用程序开发人员的复杂性,他们必须针对可能出现的数据不一致的异常进行开发. ClustrixDB提供了一个 ...
- 30. ClustrixDB 分布式架构/Rebalancer
Rebalancer是一个自动化系统,用于维护集群中数据的健康分布.通过修改数据的分布和位置来响应“不健康”集群是Rebalancer的工作.Rebalancer是一个在线进程,它影响对集群的更改,对 ...
- shiro权限控制(二):分布式架构中shiro的实现
前言:前段时间在搭建公司游戏框架安全验证的时候,就想到之前web最火的shiro框架,虽然后面实践发现在netty中不太适用,最后自己模仿shiro写了一个缩减版的,但是中间花费两天时间弄出来的shi ...
- 分布式架构中shiro
分布式架构中shiro 前言:前段时间在搭建公司游戏框架安全验证的时候,就想到之前web最火的shiro框架,虽然后面实践发现在netty中不太适用,最后自己模仿shiro写了一个缩减版的,但是中间花 ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- MemSQL分布式架构介绍(一)
最近在了解MemSQL架构,看了些官方文档,在这里做个记录,原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/ ...
随机推荐
- 数据排序 sort
排序命令: 常和管道进行协作的命令 -sort (默认使用字符的第一个字符进行排序) -n 按数字排序 -r 反序排序 -o 结果 输出到文件 -t 分隔符 (sort -n -t &qu ...
- Redis 是怎么实现 “附近的人” 的?
针对"附近的人"这一位置服务领域的应用场景,常见的可使用PG.MySQL和MongoDB等多种DB的空间索引进行实现. 而Redis另辟蹊径,结合其有序队列zset以及geohas ...
- Web前端开发JQuery框架
JQuery 是一个兼容多浏览器支持的JavaScript库,其核心理念是write less,do more(写得更少,做得更多),它是轻量级的js库,兼容CSS3还兼容各种浏览器,需要注意的是后续 ...
- webmagic学习之路-2:采集安居客经纪人列表
相比较 1 稍微成熟了一点,会用的东西多了. 正则用的不好,很多东西不会,大神轻喷! package com.action; import java.util.ArrayList; import ja ...
- linq to sql之Distinct
Distict用来排除相同序列中元素的,对于基础类型,可以直接使用Distinct,如:int[] a = {1, 2, 2, 3, 3, 3, 4};var reslut = a.Distinct( ...
- npm安装淘宝镜像cnpm
在cmd中执行 npm install -g cnpm --registry=https://registry.npm.taobao.org
- 这不是javascript:什么?
javascript协议.<a href=“javascript:void(0):”>xxx</a>基于事件的事件,例如:<input onblur=“check():” ...
- js跳转页面与打开新窗口的方法
1.超链接<a href="http://www.jb51.net" title="脚本之家">Welcome</a> 等效于js代码 ...
- python之文件 I/O
打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下: >>> prin ...
- 获得npm server 上 package 的版本信息
通过这个命令可以获取package 的历史版本信息 npm view packagename versions