scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集
数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载
转成csv载入数据
import matplotlib
matplotlib.rcParams['font.sans-serif']=[u'simHei']
matplotlib.rcParams['axes.unicode_minus']=False
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.model_selection import train_test_split,cross_val_score df = pd.read_csv('data/SMSSpamCollection.csv',header=None)
print(df.head) print("垃圾邮件个数:%s" % df[df[0]=='spam'][0].count())
print("正常邮件个数:%s" % df[df[0]=='ham'][0].count())
垃圾邮件个数:747
正常邮件个数:4825
创建TfidfVectorizer实例,将训练文本和测试文本都进行转换
X = df[1].values
y = df[0].values
X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
建立逻辑回归模型训练和预测
LR = LogisticRegression()
LR.fit(X_train,y_train)
predictions = LR.predict(X_test)
for i,prediction in enumerate(predictions[:5]):
print("预测为 %s ,信件为 %s" % (prediction,X_test_raw[i]))
预测为 ham ,信件为 Send to someone else :-)
预测为 ham ,信件为 Easy ah?sen got selected means its good..
预测为 ham ,信件为 Sorry da. I gone mad so many pending works what to do.
预测为 ham ,信件为 What not under standing.
预测为 spam ,信件为 SIX chances to win CASH! From 100 to 20,000 pounds txt> CSH11 and send to 87575. Cost 150p/day, 6days, 16+ TsandCs apply Reply HL 4 info
二元分类性能指标:混淆矩阵
# In[2]二元分类分类指标
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# predictions 与 y_test
confusion_matrix = confusion_matrix(y_test,predictions)
print(confusion_matrix)
plt.matshow(confusion_matrix)
plt.title("混淆矩阵")
plt.colorbar()
plt.ylabel("真实值")
plt.xlabel("预测值")
plt.show()
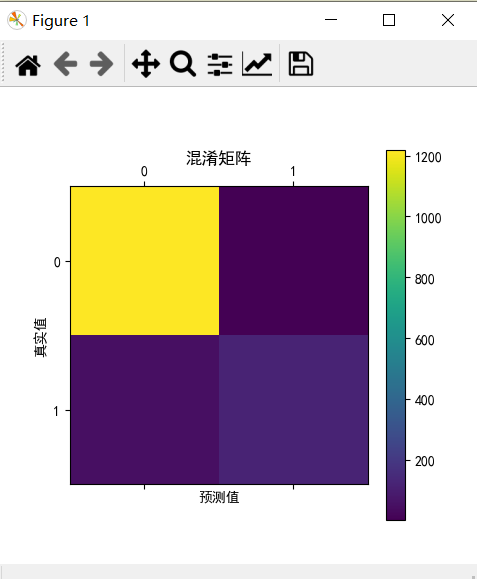
[[1217 1]
[ 52 123]]
准确率,召回率,精准率,F1值
# In[3] 给出 precision recall f1-score support
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions)) from sklearn.metrics import roc_curve,auc
# 准确率
scores = cross_val_score(LR,X_train,y_train,cv=5)
print("准确率为: ",scores)
print("平均准确率为: ",np.mean(scores)) # 有时必须要将标签转为数值
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y_train_n = class_le.fit_transform(y_train)
y_test_n = class_le.fit_transform(y_test) # 精准率
precision = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='precision')
print("平均精准率为: ",np.mean(precision))
# 召回率
recall = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='recall')
print("平均召回率为: ",np.mean(recall))
# F1值
f1 = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='f1')
print("平均F1值为: ",np.mean(f1))
准确率为: [0.96654719 0.95459976 0.95449102 0.9508982 0.96047904]
平均准确率为: 0.9574030433756144
平均精准率为: 0.9906631114805584
平均召回率为: 0.6956979405034325
平均F1值为: 0.8162874707978786
画出ROC曲线,AUC为ROC曲线以下部分的面积
# In[4] ROC曲线 y_test_n为数值
predictions_pro = LR.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test_n,predictions_pro[:,1])
roc_auc = auc(false_positive_rate, recall)
plt.title("受试者操作特征曲线(ROC)")
plt.plot(false_positive_rate, recall, 'b', label='AUC = % 0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('假阳性率')
plt.ylabel('召回率')
plt.show()

所有代码:
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.rcParams['font.sans-serif']=[u'simHei']
matplotlib.rcParams['axes.unicode_minus']=False
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.model_selection import train_test_split,cross_val_score df = pd.read_csv('data/SMSSpamCollection.csv',header=None)
print(df.head) print("垃圾邮件个数:%s" % df[df[0]=='spam'][0].count())
print("正常邮件个数:%s" % df[df[0]=='ham'][0].count()) # In[1]
X = df[1].values
y = df[0].values
X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw) LR = LogisticRegression()
LR.fit(X_train,y_train)
predictions = LR.predict(X_test)
for i,prediction in enumerate(predictions[:5]):
print("预测为 %s ,信件为 %s" % (prediction,X_test_raw[i])) # In[2]二元分类分类指标
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# predictions 与 y_test
confusion_matrix = confusion_matrix(y_test,predictions)
print(confusion_matrix)
plt.matshow(confusion_matrix)
plt.title("混淆矩阵")
plt.colorbar()
plt.ylabel("真实值")
plt.xlabel("预测值")
plt.show() # In[3] 给出 precision recall f1-score support
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions)) from sklearn.metrics import roc_curve,auc
# 准确率
scores = cross_val_score(LR,X_train,y_train,cv=5)
print("准确率为: ",scores)
print("平均准确率为: ",np.mean(scores)) # 必须要将标签转为数值
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y_train_n = class_le.fit_transform(y_train)
y_test_n = class_le.fit_transform(y_test) # 精准率
precision = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='precision')
print("平均精准率为: ",np.mean(precision))
# 召回率
recall = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='recall')
print("平均召回率为: ",np.mean(recall))
# F1值
f1 = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='f1')
print("平均F1值为: ",np.mean(f1)) # In[4] ROC曲线 y_test_n为数值
predictions_pro = LR.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test_n,predictions_pro[:,1])
roc_auc = auc(false_positive_rate, recall)
plt.title("受试者操作特征曲线(ROC)")
plt.plot(false_positive_rate, recall, 'b', label='AUC = % 0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('假阳性率')
plt.ylabel('召回率')
plt.show()
scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1的更多相关文章
- 机器学习二 逻辑回归作业、逻辑回归(Logistic Regression)
机器学习二 逻辑回归作业 作业在这,http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/hw2.pdf 是区分spam的. 57 ...
- 通俗地说逻辑回归【Logistic regression】算法(二)sklearn逻辑回归实战
前情提要: 通俗地说逻辑回归[Logistic regression]算法(一) 逻辑回归模型原理介绍 上一篇主要介绍了逻辑回归中,相对理论化的知识,这次主要是对上篇做一点点补充,以及介绍sklear ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day4-6 逻辑回归
逻辑回归avik-jain介绍的不是特别详细,下面再唠叨一遍这个算法. 1.模型 在分类问题中,比如判断邮件是否为垃圾邮件,判断肿瘤是否为阳性,目标变量是离散的,只有两种取值,通常会编码为0和1.假设 ...
- 机器学习之分类器性能指标之ROC曲线、AUC值
分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性 ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
- 【机器学习】逻辑回归(Logistic Regression)
注:最近开始学习<人工智能>选修课,老师提纲挈领的介绍了一番,听完课只了解了个大概,剩下的细节只能自己继续摸索. 从本质上讲:机器学习就是一个模型对外界的刺激(训练样本)做出反应,趋利避害 ...
- 机器学习 (三) 逻辑回归 Logistic Regression
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang 的个人 ...
- 机器学习:逻辑回归(OvR 与 OvO)
一.基础理解 问题:逻辑回归算法是用回归的方式解决分类的问题,而且只可以解决二分类问题: 方案:可以通过改造,使得逻辑回归算法可以解决多分类问题: 改造方法: OvR(One vs Rest),一对剩 ...
随机推荐
- inux中查看各文件夹大小命令:du -h --max-depth=1
du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>] [--max-de ...
- Service Broker 消息队列的方式实现数据同步
SQL Server 2008中SQL应用系列--目录索引 导读:本文主要涉及Service Broker的基本概念及建立一个Service Broker应用程序的基本步骤. 一.前言: Servic ...
- Spring MVC + freemarker实现半自动静态化
这里对freemarker的代码进行了修改,效果:1,请求.do的URL时直接生成对应的.htm文件,并将请求转发到该htm文件2,自由控制某个页面是否需要静态化原理:对org.springframe ...
- 第六章 Flask数据库(二)
Flask-SQLALchemy Flask-SQLALchemy 是一个给你的应用添加 SQLALchemy 支持的 Flask 扩展. 它需要 SQLAlchemy 0.6 或更高的版本.它致力于 ...
- Pollard-Rho 总结
将一个大数\(N\)分解质因子. 试除法,暴力枚举\(1-\sqrt{N}\)的数.时间复杂度:\(O(\sqrt{N})\). 通常,这个复杂度够了,但有时,\(N\leq10^{18}\). 这就 ...
- P4148 简单题 k-d tree
思路:\(k-d\ tree\) 提交:2次 错因:整棵树重构时的严重错误:没有维护父子关系(之前写的是假重构所以没有维护父子关系) 题解: 遇到一个新的点就插进去,如果之前出现过就把权值加上. 代码 ...
- java.io.ObjectInputStream类详解
1.public class ObjectInputStream extends InputStream implements ObjectInput, ObjectStreamConstants分析 ...
- CF1153E Serval and Snake【构造】
题目链接:洛谷 这道题是很久以前NTF跟我说的,现在想起来把它做了... 我们发现,如果蛇的两头都在矩形里或矩形外,则询问为偶数,否则为奇数. 所以我们询问每一行和每一列,就能知道蛇的两头的横纵坐标了 ...
- Luogu5339 [TJOI2019]唱、跳、rap和篮球 【生成函数,NTT】
当时看到这道题的时候我的脑子可能是这样的: My left brain has nothing right, and my right brain has nothing left. 总之,看到&qu ...
- 解决zabbix的cannot allocate shared memory of size错误
问题状态:zabbix_server 不能启动,系统CentOS 6.7 原因分析:这是因为内核对share memory的限制造成的. 用到如下命令ipcs [-m|l|a],sysctl [-a| ...