大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一、HDFS概述
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
容错。即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。
分布式文件管理系统很多,hdfs只是其中一种,不合适小文件。
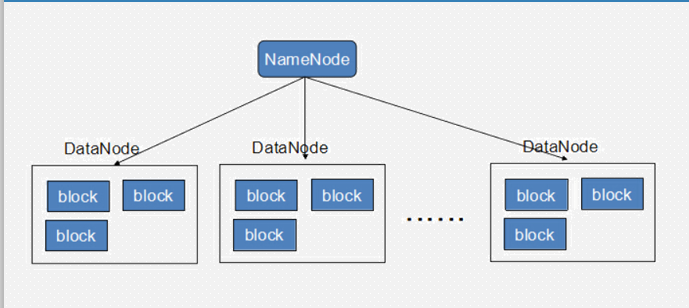
HDFS结构
二、NameNode
NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件,namenode启动后一些新增元信息日志。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
hdfs-site.xml的dfs.namenode.name.dir属性

三、DataNode
提供真实文件数据的存储服务。
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。2.0以后HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.(注意,这里不是说,重要大于128M就会产生一个block块,默认是128M,用户可以自己更改的,但是我们一般不去更改)
hdfs-site.xml中dfs.blocksize属性
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间 Replication。多复本。默认是三个。
hdfs-site.xml的dfs.replication属性
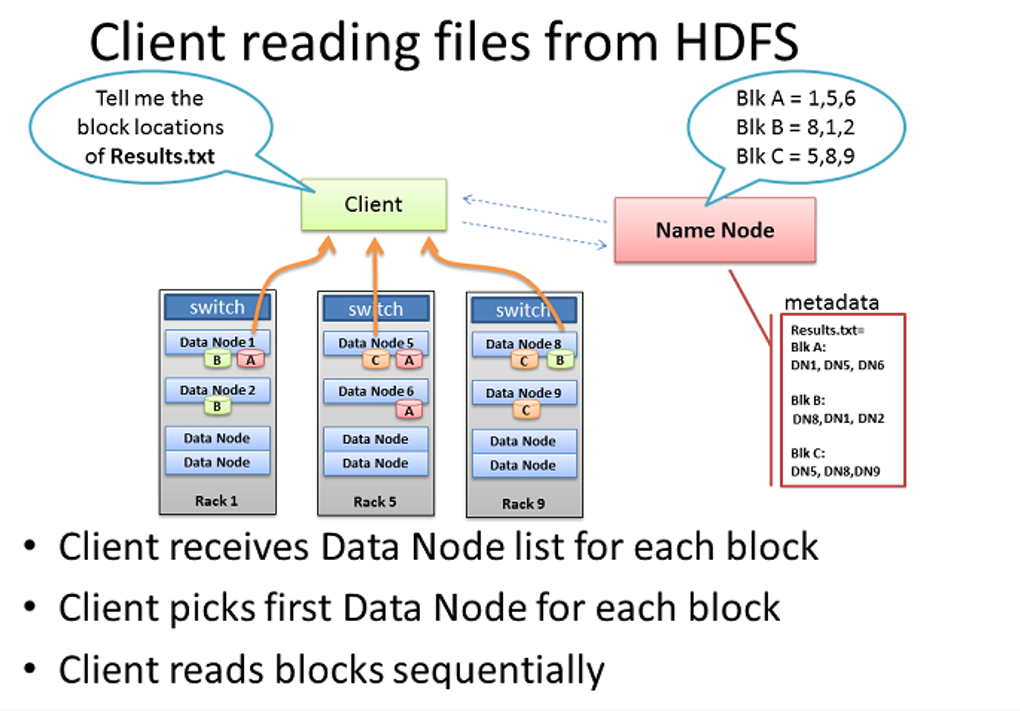
四、Client读取多副本文件过程
五、HDFS的Trash回收站
和Linux系统(桌面环境)的回收站设计一样,HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,fs.trash.interval是在指在这个回收周期之内,文件实际上是被移动到trash的这个目录下面,而不是马上把数据删除掉。等到回收周期真正到了以后,hdfs才会将数据真正删除。默认的单位是分钟,1440分钟=60*24,刚好是一天。 配置:在每个节点(不仅仅是主节点)上添加配置 core-site.xml,增加如下内容
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
注意:如果删除的文件过大,超过回收站大小的话会提示删除失败
需要指定参数 -skipTrash
六、通过Java代码去操作HDFS(这里使用Myeclipse 或者 IDEA 或者 eclipse都是可以的)
1、创建一个maven项目
2、修改pom.xml文件,将这几个有关依赖添加进去,保存。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.17</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
3、编写Java代码,连接到HDFS(我这里没有导包,注意不要导错包,Hadoop下的)
public class hdfsDemo2 {
public static void main(String[] args) throws Exception {
//
URI uri = new URI("hdfs://192.168.230.50:9000"); //输入你的namenode的节点信息
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(uri, conf);
// method2(fs);
method1(fs);
}
4、简单的操作,对HDFS创建文件夹以及删除文件夹
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.io.*;
import java.net.URI; public class hdfsDemo2 {
public static void main(String[] args) throws Exception {
//
URI uri = new URI("hdfs://192.168.230.50:9000");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(uri, conf);
// method2(fs); method1(fs);
} private static void method2(FileSystem fs) throws IOException {
boolean b1 = fs.mkdirs(new Path("/data/"));
System.out.println(b1); boolean b2 = fs.delete(new Path("/data/"),true);
System.out.println(b2);
} private static void method1(FileSystem fs) throws IOException, UnsupportedEncodingException, FileNotFoundException {
//从hdfs上读取数据
FSDataInputStream in = fs.open(new Path("/usr/test/empldata.csv"));
BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8"));
String line = null;
while((line=br.readLine())!=null){
System.out.println(line);
}
in.close(); //从本地上传到hdfs上面
/*FileInputStream fi = new FileInputStream("F:\\新桌面\\dianxin_data");
FSDataOutputStream fo = fs.create(new Path("/usr/test/hdfstest.txt"));
IOUtils.copyBytes(fi, fo, 1024, true);*/
}
}
七、将HDFS的文件读出到JVM,再存入到Mysql数据库中
1、先在数据库中建表并插入数据
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`EMPNO` int(4) NOT NULL,
`ENAME` varchar(10) DEFAULT NULL,
`JOB` varchar(9) DEFAULT NULL,
`MGR` varchar(10) DEFAULT NULL,
`HIREDATE` date DEFAULT NULL,
`SAL` int(7) DEFAULT NULL,
`COMM` int(7) DEFAULT NULL,
`DEPTNO` int(2) DEFAULT NULL,
PRIMARY KEY (`EMPNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
字段中文名字依次是:工号,姓名,工作岗位,部门经理,受雇日期,薪金,奖金,部门编号
insert into `emp`(`EMPNO`,`ENAME`,`JOB`,`MGR`,`HIREDATE`,`SAL`,`COMM`,`DEPTNO`) values
('','SMITH','CLERK','','1980-12-17','',null,''),
('','ALLEN','SALESMAN','','1981-02-20','','',''),
('','WARD','SALESMAN','','1981-02-22','','',''),
('','JONES','MANAGER','','1981-04-02','',null,''),
('','MARTIN','SALESMAN','','1981-09-28','','',''),
('','BLAKE','MANAGER','','1981-05-01','',null,''),
('','CLARK','MANAGER','','1981-06-09','',null,''),
('','SCOTT','ANALYST','','1987-04-19','',null,''),
('','KING','PRESIDENT',null,'1981-11-17','',null,''),
('','TURNER','SALESMAN','','1981-09-08','','',''),
('','ADAMS','CLERK','','1987-05-23','',null,''),
('','JAMES','CLERK','','1981-12-03','',null,''),
('','FORD','ANALYST','','1981-12-03','',null,''),
('','MILLER','CLERK','','1982-01-23','',null,''); DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`DEPTNO` int(2) NOT NULL,
`DNAME` varchar(14) DEFAULT NULL,
`LOC` varchar(13) DEFAULT NULL,
PRIMARY KEY (`DEPTNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `dept`(`DEPTNO`,`DNAME`,`LOC`) values
('','ACCOUNTING','NEW YORK'),
('','RESEARCH','DALLAS'),
('','SALES','CHICAGO'),
('','OPERATIONS','BOSTON');
2、我将要插入的数据:
7369,SMITH,CLERK,7902,1980-12-17,800,null,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,null,20),
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10
7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-03,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
3、先将数据文件通过命令 hadoop fs -put 上传到HDFS中去。
4、编写Java代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement; public class hdfsDemo {
public static void main(String[] args) throws Exception{ //hdfs的配置
URI uri = new URI("hdfs://192.168.230.50:9000");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(uri,conf); //mysql的配置
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.230.50:3306/test", "root", "123456");
System.out.println(conn);
Statement st = conn.createStatement(); FSDataInputStream fdis = fs.open(new Path("/usr/test/empldata.csv"));
BufferedReader br = new BufferedReader(new InputStreamReader(fdis));
String line = null;
while((line = br.readLine())!=null){
String[] split = line.split(",");
String EMPNO = split[0];
String ENAME = split[1];
String JOB = split[2];
String MGR = split[3];
String HIREDATE = split[4];
String SAL = split[5];
String COMM = split[6];
String DEPTNO = split[7]; String sql = "insert into test.emp(EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values " +
"("+"'"+EMPNO+"'"+","+"'"+ENAME+"'"+","+"'"+JOB+"'"+","+"'"+MGR+"'"+","+"'"+HIREDATE+"'"+","+"'"+SAL+"'"+","+"'"+COMM+"'"+","+"'"+DEPTNO+"'"+")";
System.out.println(sql);
st.execute(sql);
} fdis.close();
conn.close(); }
}
八、数据存储->读文件(重要!!!)
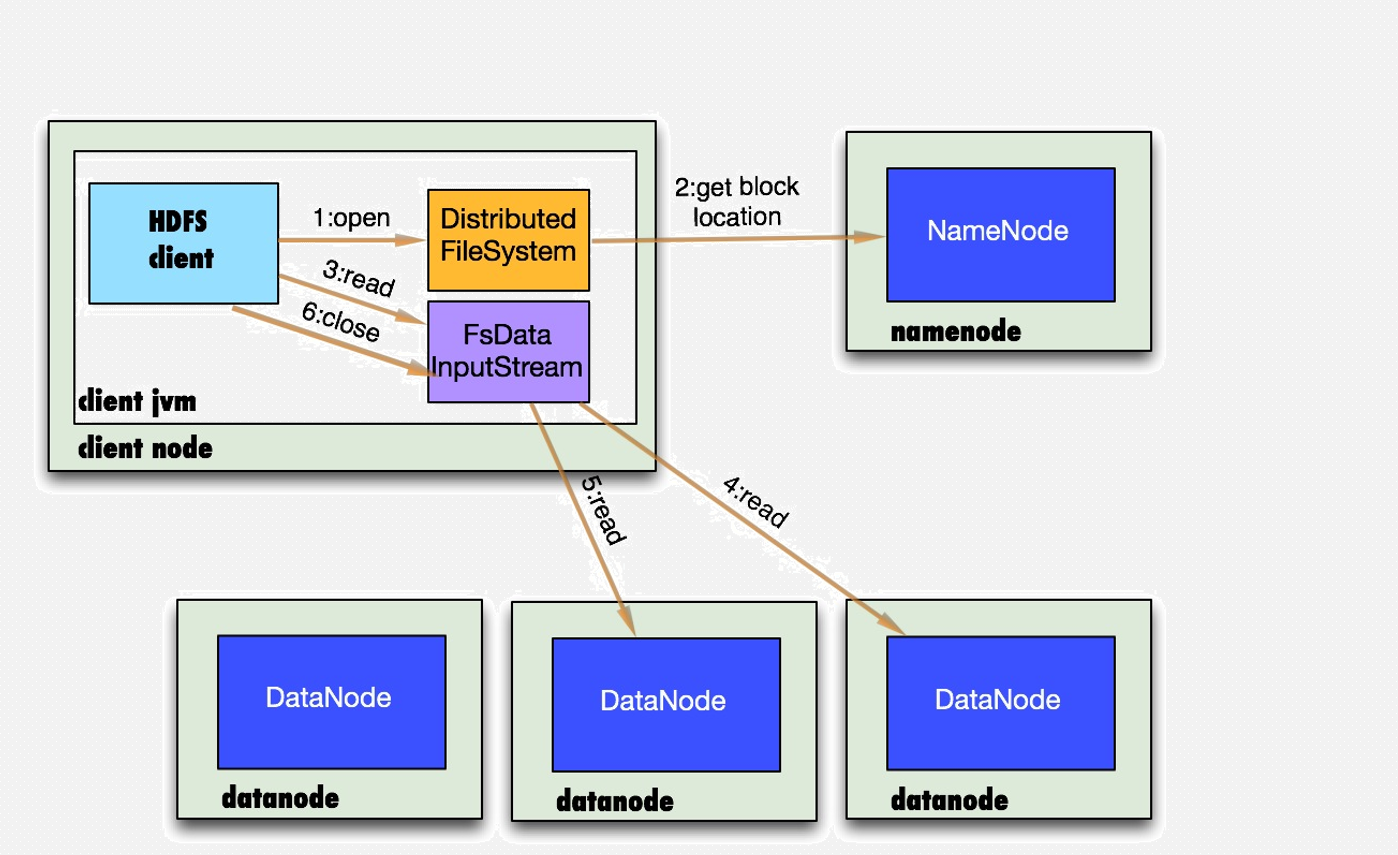
读文件流程分析:
1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
2.DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
4.数据从datanode源源不断的流向客户端。
5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像
该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
九、数据存储->写文件(重要!!!)

1.客户端通过调用DistributedFileSystem的create方法创建新文件
2.DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
3.前两步结束后会返回FSDataOutputStream的对象,象读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。 4.DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
5.DFSOutputStream还有一个对列叫ack queue,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。 如果在写的过程中某个datanode发生错误,会采取以下几步:1) pipeline被关闭掉;2)为了防止丢包ack queue里的packet会同步到data queue里;3)把产生错误的datanode上当前在写但未完成的block删掉;4)block剩下的部分被写到剩下的两个正常的datanode中;5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.客户端完成写数据后调用close方法关闭写入流
7.DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)的更多相关文章
- 大数据之路week01--自学之面向对象java(static,this指针(初稿))
函数的重载 返回值不一样会报错 java中,如果自己定义了构造函数的话,它就不会给你默认一个无参函数 如果一个属性,只进行定义,不初始化,自动补0,如果是一个布尔属性,默认是false但是如果一个局部 ...
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- 最近整理出了有关大数据,微服务,分布式,Java,Python,Web前端,产品运营,交互等1.7G的学习资料,有视频教程,源码,课件,工具,面试题等等。这里将珍藏多年的资源免费分享给各位小伙伴们
大数据,微服务,分布式,Java,Python,Web前端,产品运营,交互 领取方式在篇尾!!! 基础篇.互联网架构,高级程序员必备视频,Linux系统.JVM.大型分布式电商项目实战视频...... ...
- 一起来学大数据——走进Linux之门,学习大数据的重中之重
昨天我们看了有关大数据Hadoop的一些知识点,但是要在学习大数据之前,我们还是要为大数据的环境做一些的部署. 那么,今天我们就来讲讲开启我们大数据之路的Linux,跟上我们的脚步yo~ Linux介 ...
- Java开发想尝试大数据和数据挖掘,如何规划学习?
大数据火了几年了,但是今年好像进入了全民大数据时代,本着对科学的钻(zhun)研(bei)精(tiao)神(cao),我在17年年初开始自学大数据,后经过系统全面学习,于这个月跳槽到现任公司. 现在已 ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
- git database 数据库 平面文件 Git 同其他系统的重要区别 Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异 Git 的设计哲学
小结: 1.如果要浏览项目的历史更新摘要,Git 不用跑到外面的服务器上去取数据回来 2.注意 git clone 应指定版本,它复制的这个版本的全部历史信息: 各个分支 git init 数据库 ...
- HDFS Shell命令操作与java代码操作
(一)编程实现以下功能,并利用 Hadoop 提供的 Shell 命令完成相同任务: (1) 向 HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,则由用户来指定是追加到原 ...
随机推荐
- CMS之promotion failed&concurrent mode failure
原文链接:https://www.jianshu.com/p/ca1b0d4107c5 CMS并行GC收集器是大多数JAVA服务应用的最佳选择,然而, CMS并不是完美的,在使用CMS的过程中会产生2 ...
- [C语言]小知识点 持续更新
2019-11-24 1.如果输入: printf(,)); 会得到0: 这和我们的日常判断不相符! 然而,改成: printf(,)); 就可以成功输出“2”: 因此,注意pow函数返回的是浮点数, ...
- [转帖]crontab每小时运行一次
crontab每小时运行一次 先给出crontab的语法格式 对于网上很多给出的每小时定时任务写法,可以说绝大多数都是错误的!比如对于下面的这种写法: 00 * * * * #每隔一小时执行一 ...
- SQL 先固定特殊的几行数据之外再按照某一字段排序方法(CASE 字段排序(CASE WHEN THEN)
查询用户表的数据,管理员用户始终在最前面,然后再按照CreateTime排序: SELECT TOP * FROM [dbo].[User] WHERE ParentID = '**' ORDER B ...
- 机器学习之逻辑回归(Logistic)笔记
在说逻辑回归之前,可以先说一说逻辑回归与线性回归的区别: 逻辑回归与线性回归在学习规则形式上是完全一致的,它们的区别在于hθ(x(i))为什么样的函数 当hθ(x(i))=θTx(i)时,表示的是线性 ...
- pandas之时间重采样笔记
周期由高频率转向低频率称为降采样:例如5分钟股票交易数据转换为日交易数据 相反,周期也可以由低频转向高频称为升采样 其他重采样:例如每周三(W-WED)转换为每周五(W-FRI) import pan ...
- Linux查询命令帮助信息(知道)
方法一 command --help 方法二 man command 操作涉及到的按键: 空格键:显示手册的下一屏 Enter键:一次滚动手册的一行 b:回滚一屏 f:前滚一屏 q:退出 结果基本上全 ...
- hadoop 空间配置
hadoop-------------- 分布式计算框架. common // hdfs //存储 mapreduce //MR,编程模型. yarn //资源调度. 集群部署----------- ...
- 前端require代码抽离小技巧
DEMO 文件目录结构 plugin.js // /CommonJS规范 // var exports = module.exports; exports.test = function () { c ...
- Nginx 配置反向代理ip
参考文档: https://blog.csdn.net/stevenprime/article/details/7918094