eclipse开发scrapy爬虫工程,附爬虫临门级教程
写在前面
自学爬虫入门之后感觉应该将自己的学习过程整理一下,也为了留个纪念吧。
scrapy环境的配置还请自行百度,其实也不难(仅针对windows系统,centos配置了两天,直到现在都没整明白)
就是安装python之后下载pip,setup pip,然后用pip install下载就行了(pyspider也是这样配置的)。
附主要资料参考地址
scrapy教程地址 https://www.bilibili.com/video/av13663892?t=129&p=2
eclipse开发scrapy https://blog.csdn.net/ioiol/article/details/46745993
首先要确保主机配置了eclipse、python还有pip的环境
安装scrapy框架的方法
进入cmd界面
::pip更新命令
pip install --upgrade pip
::pip安装scrapy
pip intall scrapy
安装完成之后就可以使用了
cmd环境创建scrapy的demo程序
首先创建一个目录,位置随意,随后进入目录,输入scrapy查看命令使用方式

startproject创建工程命令。格式scrapy startproject 工程名称

genspider创建爬虫命令,一个工程可以有多个爬虫。格式 scrapy genspider 爬虫名(不能和工程重名)爬虫初始ip地址值
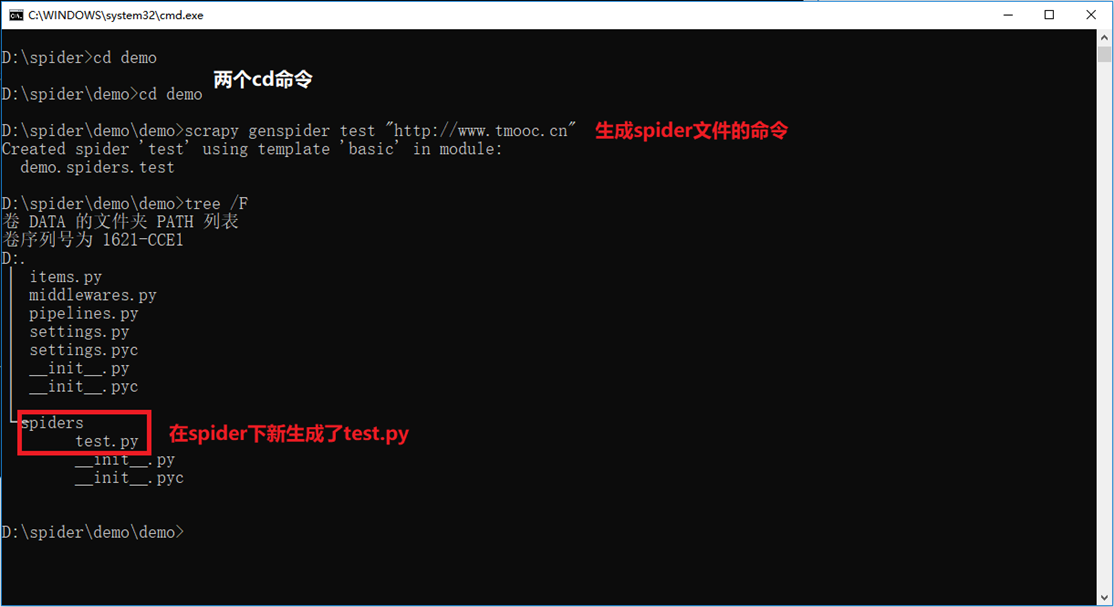
目标是获取tmooc首页的侧边栏的内容(sub的子元素a的子元素span的文本内容)
tmooc首页
侧边栏内容

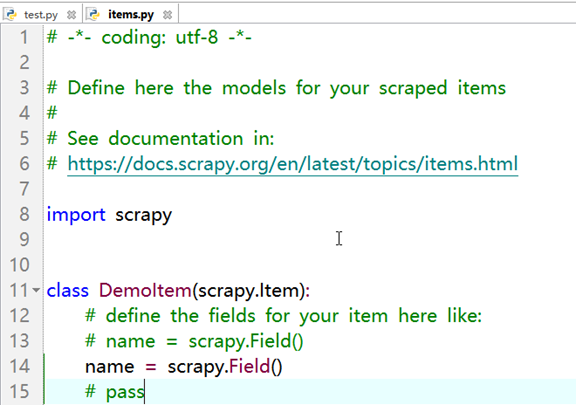
编辑item.py,位置在spider目录同级(代码简单,就不粘贴代码了)
编辑test.py
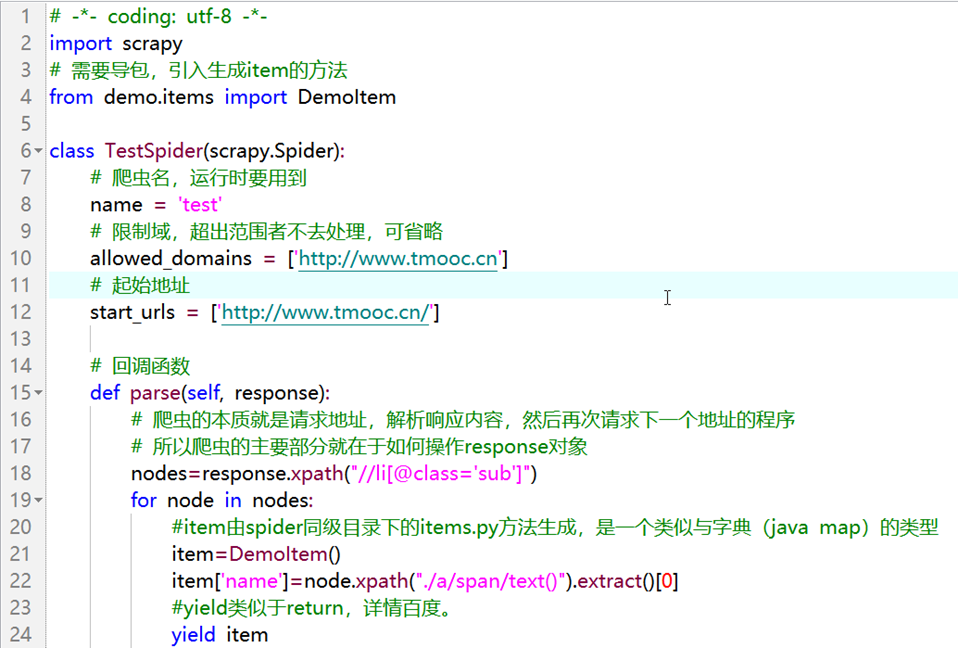
代码部分
# -*- coding: utf-8 -*-
import scrapy
# 需要导包,引入生成item的方法
from demo.items import DemoItem
class TestSpider(scrapy.Spider):
# 爬虫名,运行时要用到
name = 'test'
# 限制域,超出范围者不去处理,可省略
allowed_domains = ['http://www.tmooc.cn']
# 起始地址
start_urls = ['http://www.tmooc.cn/']
# 回调函数
def parse(self, response):
# 爬虫的本质就是请求地址,解析响应内容,然后再次请求下一个地址的程序
# 所以爬虫的主要部分就在于如何操作response对象
nodes=response.xpath("//li[@class='sub']")
for node in nodes:
#item由spider同级目录下的items.py方法生成,是一个类似与字典(java map)的类型
item=DemoItem()
item['name']=node.xpath("./a/span/text()").extract()[0]
#yield类似于return,详情百度。
yield item
编译test.py,运行spider程序

crawl是运行spider的命令。格式scrapy crawl 爬虫名 [-o 文件名]
-o参数可选,作用是将spider爬取的数据保存。保存在运行指令的目录下,可以保存成csv(excel表)json jsonl xml...等多种格式
结果展示

eclipse开发scrapyspider工程
首先要保证eclipse有python的开发环境
新建python工程,选项默认即可
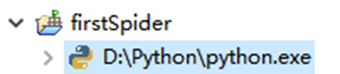
创建好的目录结构
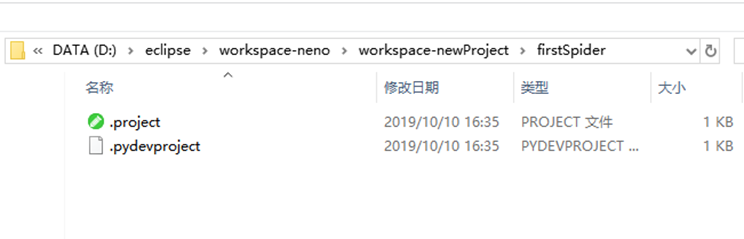
进入本地的workspace,找到该工程目录
将刚才创建的scrapy工程目录拷贝过来,不要一开始创建的那个文件夹
将demo目录

拷贝到
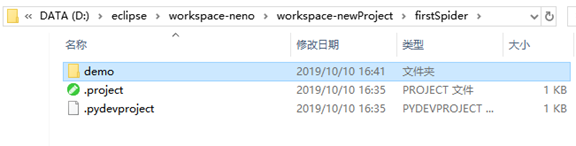
工程目录下。记得删除上次运行的结果文件

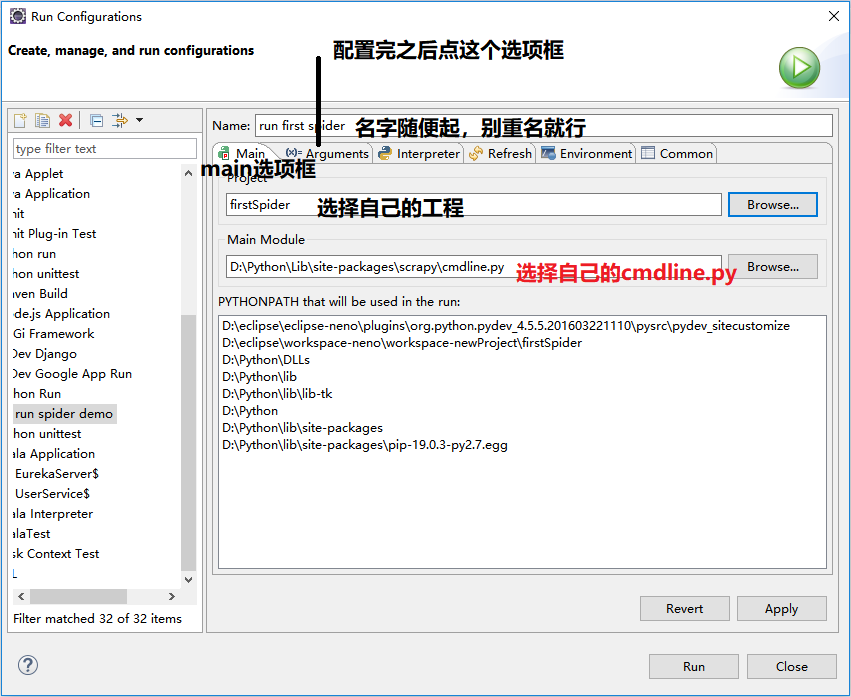
run -> run configuretion ->

运行结果

eclipse开发scrapy爬虫工程,附爬虫临门级教程的更多相关文章
- eclipse开发工具Import工程后,工程文件夹上出现黄色感叹号——解决方法
eclipse开发工具Import工程后,工程文件夹上出现黄色感叹号. 可能是Work目录无效,解决方法:删除Work目录即可,如下图所示: 删除后,如下图:
- 如何设置eclipse开发的web工程自动发布到tomcat的webapps下?
使用eclipse开发web工程,在配置好服务器(tomcat)之后运行该web工程,发现能正常运行.但是问题在于,当你打开tomcat路径\webapps时,会发现没有该web应用(你的web工程名 ...
- eclipse开发Java web工程时,jsp第一行报错,如何解决?
与myeclipse不同,eclipse开发java web项目时是要下载第三方软件(服务器)的,正是这个原因,很多初学者用eclipse学习java web的时候,总是会遇到一些小问题.其中常见的一 ...
- scrapy工具创建爬虫工程
1.scrapy创建爬虫工程:scrapy startproject scrape_project_name >scrapy startproject books_scrapeNew Scrap ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 『Scrapy』全流程爬虫demo
建立好的爬虫工程如下: item.py 它用来存储解析后的响应文件: # -*- coding: utf-8 -*- # Define here the models for your scraped ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- 基于Scrapy的B站爬虫
基于Scrapy的B站爬虫 最近又被叫去做爬虫了,不得不拾起两年前搞的东西. 说起来那时也是突发奇想,想到做一个B站的爬虫,然后用的都是最基本的Python的各种库. 不过确实,实现起来还是有点麻烦的 ...
随机推荐
- spark osx:WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform
spark-env.sh文件中增加,确保${HADOOP_HOME}/lib/native目录下有libhadoop.so文件 export JAVA_LIBRARY_PATH=${HADOOP_HO ...
- Intellij IDEA 2016.3.4 注册激活--转
对于Intellij IDEA 2016.3.4 可以填写注册server http://jetbrains.tech 来激活. 参考:https://www.haxotron.com/jetbra ...
- sonar:windows重启sonar
登录后操作
- Django:文章详情页面评论功能需要登录后才能使用,登录后自动返回到文章详情页
背景: 文章详情页正在查看文章,想评论一下写的不错,但是需要先登录才能.页面长这个样子: 方案: 1.点击登录链接时,将该页面的URL传递到登录视图中 request.path获取的是当前页面的相对路 ...
- OS选择题练习
一.死锁 1.设系统中有n个进程并发,共同竞争资源X,且每个进程都需要m个X资源,为使该系统不会发生死锁,资源X的数量至少为() A.n*m+1 B.n*m+n C.n*m+1-n D.无法预计 ...
- [转帖]CentOS 8 都发布了,你还不会用 nftables?
CentOS 8 都发布了,你还不会用 nftables? https://www.cnblogs.com/ryanyangcs/p/11611730.html 改天学习一下 原文链接:CentOS ...
- 封装ADO库之MFC应用
Microsoft Activex Data Objects(ADO)支持用于建立基于客户端/服务器和web的应用程序开发的主要功能.其主要优点是易于使用.高速度.低内存支出和占用磁盘空间较少. 本次 ...
- PHP和Memcached - Memcached的介绍及常用命令
1.什么是Memcached 自由开源的,高性能,分布式内存对象缓存系统,分布式是基于客户的缓存系统,服务器之间是不相互通讯的. 2.Memcached的使用场景 储存session. 缓存数据. 解 ...
- 记录学习Python的第一天
这是我的第一篇博客,也是我学Python的第一天. 写这篇博客主要目的是为了记下我学习Python的过程以及所学到的知识点.我所学的是Python3版本,我所学的内容有如下几点: 1.python3中 ...
- gmpy安装使用方法
gmpy是一种C编码的Python扩展模块,提供对GMP(或MPIR)多精度算术库的访问.gmpy 1.17是1.x系列的最终版本,没有进一步的更新计划.所有进一步的开发都在2.x系列(也称为gmpy ...