『Scrapy』全流程爬虫demo
建立好的爬虫工程如下:
item.py
它用来存储解析后的响应文件:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
这是一个类似字典的数据结构,通过dict(items)可以直接转换为字典,以上面为例,其实例具有'name','title','info'三个key值。
spider爬虫
sipder需要调用item字典用于临时存储解析出来的数据,注意使用yield来动态化整个过程
这里面没有着重介绍解析过程,原因是我现在也不太懂
import scrapy
from Scrapy.items import ScrapyItem class ITcastSpider(scrapy.Spider):
# 名称
name = 'itcast'
# 限制域
allowed_domains = 'itcast.cn'
# 起始域
start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
item = ScrapyItem()
#
name = node.xpath('./h3/text()').extract()
title = node.xpath('./h4/text()').extract()
info = node.xpath('./p/text()').extract() item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0] yield item
由于我本身对html并不熟悉,为了理解一下我去原网页查看了一下源码,对应部分的结构如下:

spider的补充说明
一,视频spider中的return是返回给引擎,引擎会根据返回值的内容的做出不同处理,
- 如果是上面的item实例,则会交给管线程序处理,
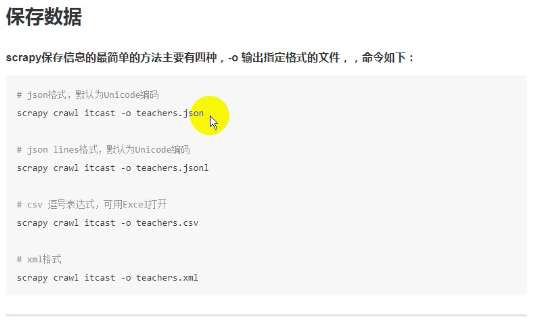
- 如果是list或者其他普通数据结构的话可以在crawl命令位置添加-o输出到文件,有一下四种输出,但是这种方法无法修改编码方式,
- return的是请求的话会进入新一轮的爬取,
二,有关response,这是一个响应对象,response.xpath()后是一个xpath对象,
print(node.xpath('./h3/text()'))
print(name)
print(name[0])看看输出,
[<Selector xpath='./h3/text()' data='杨老师'>]
['杨老师']
杨老师
也就是说.extract()方法可以把xpath对象的data部分提取出来作为一个字符串列表。
另一处就是xpath对象的提取规则了,//表示全匹配(任意匹配)而./表示当前匹配xpath对象下的级,text()就是文本对象了,不单单是xpath,response的解析方式还有其他的,css也是可以的,本节不过多讨论。
settings.py
指定管道文件,下面的语句原本是注释掉的,我们需要取消注释并可以做出修改,字典中的数字表示优先级,0~1000,越小优先度越高,spider解析出来的item数据会按照优先级依次流入各个管道做后续处理(存储之类的),由于是依次,所以管道处理数据后返回值必须是原始数据,这在后面会看到
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Scrapy.pipelines.ScrapyPipeline': 300,
}
pipelines.py

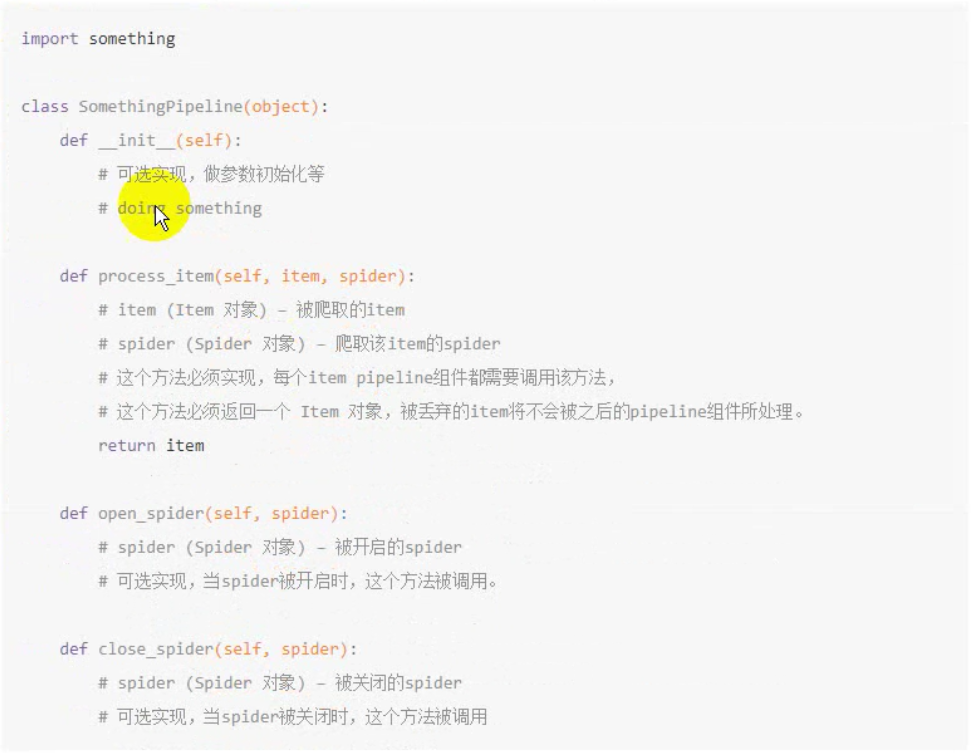
__init__()和close_spider()会被自动调用与爬虫起始与结束,process_item()会在每次出现返回值都被调用,并将自己的返回值交给下一优先级的管线
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class ScrapyPipeline():
def __init__(self):
self.f = open('itcast_pipeline.json', 'w') def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.f.write(content)
# 必须return这个,可以传给下一管道
return item def close_spider(self,spider):
self.f.close()
如果在这里面添加print(item),会看到输出如下,每次一行:
{'info': '五年以上教学经验及多年开发经验,精通C/S架构、B/S架构,涉足.NET、IOS等技术平台及各种数据库系统。精通多种主流编程语言。课上行云流水,通俗易懂,由浅入深,诙谐幽默。待学员如初恋,一个肯为学员玩命教学的男人! ', 'title': '高
级讲师', 'name': '杨老师'}
json.dumps()操作将字典转化为str,而json.loads()做反向变换,它们和保存文件的尾缀没有关系,由于默认是ascii格式保存一般中文会加上ensure_ascii=False:
In [1]: import json
In [2]: a = {'name': 'wang', 'age': 29}
In [3]: b = json.dumps(a) In [4]: print b, type(b)
{"age": 29, "name": "wang"} <type 'str'> In [11]: json.loads(b)
Out[11]: {u'age': 29, u'name': u'wang'} In [12]: print type(json.loads(b))
<type 'dict'>
运行
scrapy check itcast # 检查逻辑是否有错误
scrapy crawl itcast # 运行爬虫,注意,指定的是爬虫类的名称属性
『Scrapy』全流程爬虫demo的更多相关文章
- 『Scrapy』爬取腾讯招聘网站
分析爬取对象 初始网址, http://hr.tencent.com/position.php?@start=0&start=0#a (可选)由于含有多页数据,我们可以查看一下这些网址有什么相 ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 『Scrapy』终端调用&选择器方法
Scrapy终端 示例,输入如下命令后shell会进入Python(或IPython)交互式界面: scrapy shell "http://www.itcast.cn/channel/te ...
- Python爬虫:scrapy 的运行流程和各模块的作用
scrapy的运行流程 爬虫 -> 起始URL封装Request -> 爬虫中间件 -> 引擎 -> 调度器(Scheduler): 缓存请求, 请求去重 调度器 -> ...
- 『Json』常用方法记录
json模块可以把字典结构改写为string然后保存,并可以反向读取字典 pickle模块则可以持久化任意数据结构 但是即使同样是字典数据结构,两个包也是有差别的, json字典value不支持其他对 ...
- 『Os』常用方法记录
os.rename(name_old, name_new) 『Scrapy』爬取斗鱼主播头像 重命名函数os.rename比win下的重命名强多了,它可以对路径重命名达到修改文件位置的功效. os.p ...
- 『TensorFlow』流程控制
『PyTorch』第六弹_最小二乘法对比PyTorch和TensorFlow TensorFlow 控制流程操作 TensorFlow 提供了几个操作和类,您可以使用它们来控制操作的执行并向图中添加条 ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
随机推荐
- 发布QT exe
https://blog.csdn.net/u014453443/article/details/85837138
- Python安装selenium,配置火狐浏览器环境
想用Python去编写自动化脚本进行网页访问时,遇到了一些问题, File "C:\Python34\lib\site-packages\selenium-3.0.0b2-py3.4.egg ...
- ACM题目————中位数
题目描述 长为L的升序序列S,S[L / 2]为其中位数. 给出两个等长升序序列S1和S2,求两序列合并并排序后的中位数. 输入 多组数据,每组第一行为n,表示两个等长升序序列的长度. 接下来n行为升 ...
- 如何使用Unity制作虚拟导览(一)
https://www.cnblogs.com/yangyisen/p/5108289.html Unity用来制作游戏已经是目前市场上的一个发展趋势,而且有越来越多的公司与开发者不断的加入,那么Un ...
- Redis 如何保持和MySQL数据一致【二】
需求起因 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节.所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库. 这个业务场景,主要 ...
- linux 添加 swap
1)在linux下,首先,查看内存和swap大小: [root@rhel6 usr]# free -m total used free sha ...
- vc++之stdafx.h
关于stdafx.h的解释,其实蛮多的,在vs中,既然创建c++工程的时候,默认会给生成main.cpp,并且自动包含了stdafx.h,而且stdafx.h不是c++标准的一部分,那么个人认为,理解 ...
- troubleshooting-执行导数shell脚本抛异常error=2, No such file or directory
Cannot run program "order_log.sh" (in directory "/data/yarn/nm/usercache/chenweidong/ ...
- 数据库 - SQLite3 中的数据类型
------------------------------ 安装 Sqlite3 和 数据库查看工具: sudo apt-get install sqlite3 sudo apt-get insta ...
- bzoj 1096 仓库建设 -斜率优化
L公司有N个工厂,由高到底分布在一座山上.如图所示,工厂1在山顶,工厂N在山脚.由于这座山处于高原内陆地区(干燥少雨),L公司一般把产品直接堆放在露天,以节省费用.突然有一天,L公司的总裁L先生接到气 ...