SciTech-BigDataAIML-Algorithm-Heuristic启发式- 带weight(权重)的Graph(无向图)最优路线规划 : Dijkstra Algorithm(迪杰斯特拉算法)"由"边线加权"的Graph"得出"Routing Table(最优路由表)"
Dijkstra迪杰斯特拉算法
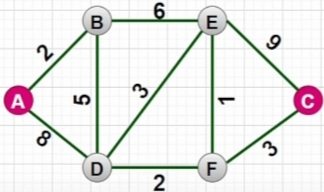
用“Graph”作出简图:
图例:
"选定起点"的Routing Table(路由表)
| 行号 | 节点 | 最短距离 | 前一节点 | 已访问完全 |
|---|---|---|---|---|
| 1 | A | 0 | A | T |
| 2 | B | 2 | A | T |
| 3 | C | 12 | F | T |
| 4 | D | 7 | B | T |
| 5 | E | 8 | B | T |
| 6 | F | 9 | D,E | T |
上表的用法:
- 表格的"第1行"是"起点"; 图例:上表是图上的节点"A"作为起点;
- 由"终点"起始,用"每一节点"查表得到的"前一节点";
一步步倒推,可得出 "起点" 到 "终点" 的 "最短完整路线".
例如:要求解“A点出发,到C点的最短路线”,
根据上表,可查表得出:- 终点"C"节点的数据记录行的"行号"是 "3"(第3行),
- "最短路线" 为12(由"起点A"到"终点C"),
- "最短完整路线"("起点A"到"终点C"):
由终点C起始, 递推的用"每一节点"查表得到的"前一节点", 一步步倒推, 可得出:
$ C \overset{3}{\leftarrow} F \overset{2}{\leftarrow} D \overset{5}{\leftarrow} B \overset{2}{\leftarrow} A $ - 注意:"最短路径"可能有不只一条;
例如: "起点A"到"终点F"的"最短路线"(最短距离都为9)- $ F \overset{2}{\leftarrow} D \overset{5}{\leftarrow} B \overset{2}{\leftarrow} A $
- $ F \overset{1}{\leftarrow} E \overset{6}{\leftarrow} B \overset{2}{\leftarrow} A $
由"节点路线Graph"推导出"Routing Table(路由表)"
将 Graph 转化为 Dictionary 数据结构:
例如图示的 Graph 可转化为:
MAX_DIST = 99999999
DIST_INDEX = 0
PREV_INDEX = 1
SOURCE = "A"
graph_dict = { # Graph 转化为 Dictionary 数据结构
"A": [0, ["A"], ("B", 2), ("D", 8)],
"B": [MAX_DIST, [], ("A", 2), ("D", 5), ("E", 6)],
"C": [MAX_DIST, [], ("E", 9), ("F", 3)],
"D": [MAX_DIST, [], ("A", 8), ("B", 5), ("E", 3), ("F", 2)],
"E": [MAX_DIST, [], ("B", 6), ("D", 3), ("F", 1), ("C", 9)],
"F": [MAX_DIST, [], ("D", 2), ("E", 1), ("C", 3)],
}
queue_dict = {}
queue_dict[SOURCE] = graph_dict[SOURCE] # 开始只需要将初始"起点A"加入"任务队列"
while len(queue_dict) > 0: # 需要更新计算“后继”节点的"任务队列"
(node, val) = result_dict.popitem() # 取出一个任务"节点"
(min_dist, prev, *edges) = val # 得到其"当前累加权重","前一个节点" 和 "其edges"
print("\n Processing : %r: min_dist:%d, prev:%r" % (node, min_dist, prev))
for next, weight in edges: # 迭代每一条 edge
next_val = graph_dict[next]
accu_dist = min_dist + weight # 由"当前节点" 计算 "下一节点" 的"累加权重"
if accu_dist < next_val[DIST_INDEX]: # 计算得出"更优"的"累加权重":
next_val[DIST_INDEX] = accu_dist # 将"更优"的"累加权重"更新到"下一节点"
next_val[PREV_INDEX] = [node] # "更优"选择的"前一节点", 更新到"下一节点"
queue_dict[next] = next_val # 有更新的"下一节点"要加入"任务队列"
print(
" Edge from:%r, to:%r, accu_dist:%d, prev:%r"
% (node, next, accu_dist, next_val[PREV_INDEX])
)
elif accu_dist == next_val[DIST_INDEX]: # 多个"前节点"有"同优"的"累加权重"
if node not in next_val[PREV_INDEX]:
next_val[PREV_INDEX].append(node) # 追加到"前节点"列表
print(
" Edge from:%r, to:%r, accu_dist:%d, prev:%r"
% (node, next, accu_dist, next_val[PREV_INDEX])
)
else:
print(" Edge from:%r, to:%r, accu_dist:%d, " % (node, next, accu_dist))
print("\n" + "#" * 10 + "\nRouting Table:\n") # 打印路由表
items = list(graph_dict.items())
for n, val in sorted(items, key=lambda x: x[0]):
print(
"Node:%r, accu_dist:% 2d, prev:%r" % (n, val[DIST_INDEX], val[PREV_INDEX])
)
运行结果:
root@localhost:~/storage/shared/AAAAA# python dijkstra.py
Processing : 'A': min_dist:0, prev:['A']
Edge from:'A', to:'B', accu_dist:2, prev:['A']
Edge from:'A', to:'D', accu_dist:8, prev:['A']
Processing : 'D': min_dist:8, prev:['A']
Edge from:'D', to:'A', accu_dist:16,
Edge from:'D', to:'B', accu_dist:13,
Edge from:'D', to:'E', accu_dist:11, prev:['D']
Edge from:'D', to:'F', accu_dist:10, prev:['D']
Processing : 'F': min_dist:10, prev:['D']
Edge from:'F', to:'D', accu_dist:12,
Edge from:'F', to:'E', accu_dist:11, prev:['D', 'F']
Edge from:'F', to:'C', accu_dist:13, prev:['F']
Processing : 'C': min_dist:13, prev:['F']
Edge from:'C', to:'E', accu_dist:22,
Edge from:'C', to:'F', accu_dist:16,
Processing : 'E': min_dist:11, prev:['D', 'F']
Edge from:'E', to:'B', accu_dist:17,
Edge from:'E', to:'D', accu_dist:14,
Edge from:'E', to:'F', accu_dist:12,
Edge from:'E', to:'C', accu_dist:20,
Processing : 'B': min_dist:2, prev:['A']
Edge from:'B', to:'A', accu_dist:4,
Edge from:'B', to:'D', accu_dist:7, prev:['B']
Edge from:'B', to:'E', accu_dist:8, prev:['B']
Processing : 'E': min_dist:8, prev:['B']
Edge from:'E', to:'B', accu_dist:14,
Edge from:'E', to:'D', accu_dist:11,
Edge from:'E', to:'F', accu_dist:9, prev:['E']
Edge from:'E', to:'C', accu_dist:17,
Processing : 'F': min_dist:9, prev:['E']
Edge from:'F', to:'D', accu_dist:11,
Edge from:'F', to:'E', accu_dist:10,
Edge from:'F', to:'C', accu_dist:12, prev:['F']
Processing : 'C': min_dist:12, prev:['F']
Edge from:'C', to:'E', accu_dist:21,
Edge from:'C', to:'F', accu_dist:15,
Processing : 'D': min_dist:7, prev:['B']
Edge from:'D', to:'A', accu_dist:15,
Edge from:'D', to:'B', accu_dist:12,
Edge from:'D', to:'E', accu_dist:10,
Edge from:'D', to:'F', accu_dist:9, prev:['E', 'D']
##########
Routing Table:
Node:'A', accu_dist: 0, prev:['A']
Node:'B', accu_dist: 2, prev:['A']
Node:'C', accu_dist: 12, prev:['F']
Node:'D', accu_dist: 7, prev:['B']
Node:'E', accu_dist: 8, prev:['B']
Node:'F', accu_dist: 9, prev:['E', 'D']
SciTech-BigDataAIML-Algorithm-Heuristic启发式- 带weight(权重)的Graph(无向图)最优路线规划 : Dijkstra Algorithm(迪杰斯特拉算法)"由"边线加权"的Graph"得出"Routing Table(最优路由表)"的更多相关文章
- 单源最短路径-迪杰斯特拉算法(Dijkstra's algorithm)
Dijkstra's algorithm 迪杰斯特拉算法是目前已知的解决单源最短路径问题的最快算法. 单源(single source)最短路径,就是从一个源点出发,考察它到任意顶点所经过的边的权重之 ...
- 带你找到五一最省的旅游路线【dijkstra算法推导详解】
前言 五一快到了,小张准备去旅游了! 查了查到各地的机票 因为今年被扣工资扣得很惨,小张手头不是很宽裕,必须精打细算.他想弄清去各个城市的最低开销. [嗯,不用考虑回来的开销.小张准备找警察叔叔说自己 ...
- 带你找到五一最省的旅游路线【dijkstra算法代码实现】
算法推导过程参见[dijkstra算法推导详解] 此文为[dijkstra算法代码实现] https://www.cnblogs.com/Halburt/p/10767389.html package ...
- Android 布局之LinearLayout 子控件weight权重的作用详析(转)
关于Android开发中的LinearLayout子控件权重android:layout_weigh参数的作用,网上关于其用法有两种截然相反说法: 说法一:值越大,重要性越高,所占用的空间越大: 说法 ...
- Android 布局之LinearLayout 子控件weight权重的作用详析
关于Android开发中的LinearLayout子控件权重android:layout_weigh参数的作用,网上关于其用法有两种截然相反说法: 说法一:值越大,重要性越高,所占用的空间越大: 说法 ...
- 【算法】狄克斯特拉算法(Dijkstra’s algorithm)
狄克斯特拉算法(Dijkstra’s algorithm) 找出最快的路径使用算法——狄克斯特拉算法(Dijkstra’s algorithm). 使用狄克斯特拉算法 步骤 (1) 找出最便宜的节点, ...
- 广度优先搜索(BreadthFirstSearch)& 迪克斯特拉算法 (Dijkstra's algorithm)
BFS可回答两类问题: 1.从节点A出发,有前往节点B的路径吗? 2.从节点A出发,前往节点B的哪条路径经过的节点最少? BFS中会用到"队列"的概念.队列是一种先进先出(FIFO ...
- 机器人路径规划其一 Dijkstra Algorithm【附动态图源码】
首先要说明的是,机器人路径规划与轨迹规划属于两个不同的概念,一般而言,轨迹规划针对的对象为机器人末端坐标系或者某个关节的位置速度加速度在时域的规划,常用的方法为多项式样条插值,梯形轨迹等等,而路径规划 ...
- Method for finding shortest path to destination in traffic network using Dijkstra algorithm or Floyd-warshall algorithm
A method is presented for finding a shortest path from a starting place to a destination place in a ...
- Dijkstra Algorithm 迪克特斯拉算法--Python
迪克斯拉特算法: 1.找出代价最小的节点,即可在最短时间内到达的节点: 2.更新节点的邻居的开销: 3.重复这个过程,直到图中的每个节点都这样做了: 4.计算最终路径. ''' 迪克斯特拉算法: 1. ...
随机推荐
- 搞定 XLSX 预览?别瞎找了,这几个库(尤其最后一个)真香!
- Hey, 我是 沉浸式趣谈 - 本文首发于[沉浸式趣谈],我的个人博客 **https://yaolifeng.com** 也同步更新. - 转载请在文章开头注明出处和版权信息. - ...
- 47.9K star!全平台开源笔记神器,隐私安全首选!
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 "Joplin 是一款开源的笔记记录和待办事项应用,支持端到端加密同步,完美替代商 ...
- 【安装】Ubuntu20.04下安装ROS的完整过程(内含已装好ROS的虚拟机、虚拟机创建过程、ROS安装过程及全过程录屏)
现成的虚拟机 为方便大家学习,如果安装ROS遇到的问题实在太多,也可以直接下载我提供给大家的.已经安装好ROS的Ubuntu虚拟机:下载链接, 提取码:1030. 虚拟机的使用说明也在这个文件夹下,虚 ...
- deepseek+coze实战:一键抓取百条抖音爆款视频,自动存入飞书表格
大家好,我是汤师爷~ 批量获取抖音视频文案这件事,一直有技术门槛. 很多朋友因为不懂技术,只能花钱买工具来完成这项任务. 今天我要分享一个Coze智能体的解决方案 只需输入关键词就能自动批量获取视频文 ...
- TVM VLOG打印
TVM 提供了详细日志记录功能,允许提交跟踪级别的调试消息,而不会影响生产中 TVM 的二进制大小或运行时.你可以在你的代码中使用 VLOG 如下: void Foo(const std::strin ...
- RPC实战与核心原理之健康检测
健康检测:这个节点都挂了,为啥还要疯狂发请求 回顾 超大规模集群"服务发现"的挑战,服务发现的作用就是实时感知集群 IP 的变化,实现接口跟服务集群节点 IP 的映射.在超大规模集 ...
- MySQL 把查询结果更新或者插入到新表
摘要:在MySQL数据库,把查询到的多条记录复制到另一张表中.复制通常包括两种场景,一种是使用update命令更新旧数据,另一种是使用insert命令插入新记录. 需求背景:在某些业务中,需要把查询到 ...
- wso2~部署~v4.2.0-alpha本地构建
让我先查看一下v4.2.0-alpha分支的构建相关信息: Search files... 让我继续查看构建说明文档: Search files... 让我查看一下项目根目录下的文件: Ran too ...
- Go中的数组和切片
本文参考: https://www.liwenzhou.com/posts/Go/05_array/ https://www.liwenzhou.com/posts/Go/06_slice/ Arra ...
- kubernetes之HPA详细介绍
一.HPA说明 HPA(Horizontal Pod Autoscaler)是kubernetes的一种资源对象,能够根据某些指标对在statefulset.replicacontroller.rep ...