pve节点频繁宕机问题排查
1.时间:
我是大概20220521日上午11:03分收到这个事情开始跟进;
再这之前一直是其他同事在处理,由于最近比较忙,没有安排的事情基本也都没有深入跟进,只是知道个大概。
2.问题现象:
qa环境k8s集群内有两台虚拟机节点宕机,影响的业务面为qa环境k8s集群不可用。下层的物理机是自建pve。pve也连接失败(认为此节点宕机)。处理方式人为干预对pve硬重启后,再逐次启动上层虚拟机。但是只能临时解决。
3.问题的处理思路:
#信息收集:
#判断系统
# cat /etc/redhat-release #这个为centos或者redhat查看方法
cat: /etc/redhat-release: No such file or directory
# cat /etc/debian_version #这个为通用的debian系统查看方法
10.12
# uname -a
Linux pve65 5.4.73-1-pve #1 SMP PVE 5.4.73-1 (Mon, 16 Nov 2020 10:52:16 +0100) x86_64 GNU/Linux
可以看出我们使用的是开源的pve虚拟机。
查看当前版本信息
# pveversion -v
proxmox-ve: 6.3-1 (running kernel: 5.4.73-1-pve)
pve-manager: 6.3-2 (running version: 6.3-2/22f57405)
pve-kernel-5.4: 6.3-1
pve-kernel-helper: 6.3-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
获取最近的系统重启时间为 11:07分
重启后问题临时解决,那么就要分析11:07分以前的日志,在这个时间之前的日志都为有用的信息。
通过/var/log/messages日志发现11:07以前依然有系统日志输出。 这证明了系统一直在运行状态。
直到17号发现有一条cpu相关警告,但是这条线不太有价值,我追下去没有得到相关具体解决方案。
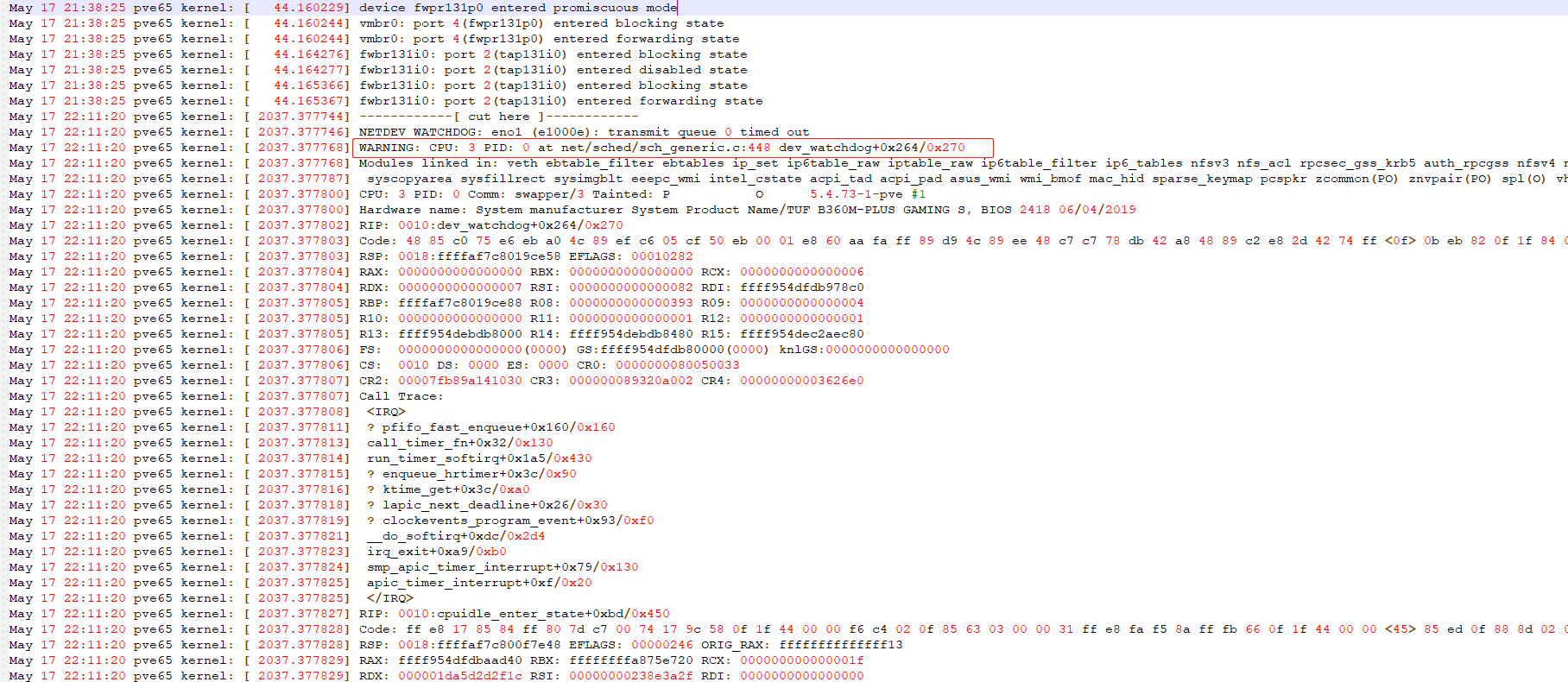
在/var/log/syslog 日志中有了新发现:
11:07:34秒前所有的日志都是报网卡挂起
e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang: (直接google就得到了答案)
官方可以看到很多人遇到了同样的问题,也都回复得到了解决。和我们目前的问题一致:
https://forum.proxmox.com/threads/e1000-driver-hang.58284/
4.下午3点53分处理结束
#如果没有ethtool工具可以执行如下命令安装:
apt install ethtool
#禁用 tcp 分段卸载和通用分段卸载
# ethtool -K eno1 tso off gso off
执行后到20220521日22:50分目前为止再没有报日志:
e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang:
pve节点频繁宕机问题排查的更多相关文章
- Kafka 0.8 宕机问题排查步骤
CPU 利用率高的排查方法 看看该机器的连接数是不是比其他机器多,监听的端口数:netstat -anlp | wc -l Kafka-0.8的停止和启动 启动: cd /usr/local/kafk ...
- java调用jni oci接口宕机原因排查
调用最简单的JNI没有出错,但是涉及到OCI时就会异常退出,分析后基本确定是OCI 11g中的signal所致,参考ora-24550 signo=6 signo=11解决. 但是这个相同的so库直接 ...
- mongodb副本集中其中一个节点宕机无法重启的问题
2-8日我还在家中的时候,被告知mongodb副本集中其中一个从节点因未知原因宕机,然后暂时负责代管的同事无论如何就是启动不起来. 当时mongodb的日志信息是这样的: 实际上这里这么长一串最重要的 ...
- Hadoop NameNode判断 DataNode 节点宕机的时间
.namenode 如何判断datanode节点是否宕机? 先决条件: datanode每隔一段时间像namenode汇报,汇报的信息有两点 ()自身datanode的状态信息: ()自身datano ...
- clickhouse高可用-节点宕机数据一致性方案-热扩容
1. 集群节点及服务分配 说明: 1.1. 在每个节点上启动两个clickhouse服务(后面会详细介绍如何操作这一步),一个数据分片,一个数据备份,为了确保宕机数据一致性,数据分片和数据备份不能同一 ...
- 【故障公告】Kubernetes 集群节点宕机造成博客站点故障
非常抱歉!今天 18:40-18:55 左右 Kubernetes 集群一台高配节点突然宕机,造成博客站点故障,访问时出现 502 Bad Gateway,由此给您带来麻烦麻烦,请您谅解. 发现故障并 ...
- HBase–RegionServer宕机恢复原理
Region Server宕机总述 HBase一个很大的特色是扩展性极其友好,可以通过简单地加机器实现集群规模的线性扩展,而且机器的配置并不需要太好,通过大量廉价机器代替价格昂贵的高性能机器.但也正因 ...
- 性能测试——记XX银行电票系统上线后宕机问题诊断优化
四月份我们公司负责的电票系统上线了,这个系统上线比客户方其他系统上线还特殊,是二期改造项目,旧系统数据还要整合抽取到新系统中继续使用,而且该系统不是增量型方式开发上线的,而且全部开发完后全国上线的,这 ...
- drbd虚拟机宕机恢复方法
问题现象 云南计算节点YN-ec-compute-19因系统盘损坏宕机且操作系统无法恢复,其上本地虚拟机无法疏散且无法迁移 拟采用drbd备份的数据对compute19上的虚拟机进行恢复 恢复方法 1 ...
- 服务器宕机了,Kafka 消息会丢失吗?
大家好,我是树哥. 消息队列可谓是高并发下的必备中间件了,而 Kafka 作为其中的佼佼者,经常被我们使用到各种各样的场景下.随着 Kafka 而来得,还有三个问题:消息丢失.消息重复.消息顺序.今天 ...
随机推荐
- 命名空间“System.Web.UI.Design”中不存在类型或命名空间名称“ControlDesigner”
命名空间"System.Web.UI.Design"中不存在类型或命名空间名称"ControlDesigner" 命名空间"System.Web.UI ...
- JAVA Swing日期选择控件datepicker的使用
声明:本控件来自互联网,仅可应用于个人项目,不可商用,如您未遵守造成的任何问题请自行承担点击下载 datepicker.jar 使用方法1.导入 在eclipse中,单击你的项目名,右键–>Bu ...
- windows11使用pycharm连接wsl2开发基于poetry的python项目
windows11使用pycharm连接wsl2开发基于poetry的python项目 背景:公司开发的python项目用到了某个只提供了Linux版本的包,遂研究了一番如何在windows环境下进行 ...
- Python串口实现dk-51e1单相交直流标准源通信
Python实现dk-51e1单相交直流标准源RS232通信 使用RS232,信号源DK51e1的协议帧格式如下: 注意点 配置串口波特率为115200 Check异或和不需要加上第一个0x81的字段 ...
- w3cschool-Spring Cloud
https://www.w3cschool.cn/spring_cloud/spring_cloud-ryjs2ixg.html Spring Cloud(一)服务的注册与发现(Eureka) 202 ...
- weixueyuan-Nginx在Kubernetes10
https://www.weixueyuan.net/nginx/kubernetes/ Kubernetes(k8s)分布式容器管理系统简述 Kubernetes 是分布式容器管理系统,它提供了对容 ...
- MySQL---索引、Explain、优化、慢查询
索引 什么是索引? 索引是帮助Mysql提高获取数据的数据结构,换一句话讲就是"排好序的快速查找的数据结构". 一.索引的分类 MySQL主要的几种索引类型:1.普通索引.2.唯 ...
- Java Spring Cloud Nacos 配置修改不生效的解决方法
一.引言 在微服务架构中,配置管理是一个关键部分.Nacos作为一个动态服务发现.配置管理和服务管理平台,广泛应用于Java Spring Cloud项目中.然而,有时在修改Nacos配置后,这些更改 ...
- 天翼云CDN全站加速产品对websocket协议的支持
本文分享自天翼云开发者社区<天翼云CDN全站加速产品对websocket协议的支持>,作者:郭****迎 1.背景介绍 HTTP 协议有一个缺陷:通信只能由客户端发起.这种单向请求的特点, ...
- NSSM使用说明
1.说明 NSSM是一个服务封装程序,它可以将普通exe程序封装成服务,使之像windows服务一样运行.同类型的工具还有微软自己的srvany,不过nssm更加简单易用,并且功能强大.它的特点如下: ...