ConcurrentHashMap(JDK1.8)put分析
一、ConcurrentHashMap整体结构
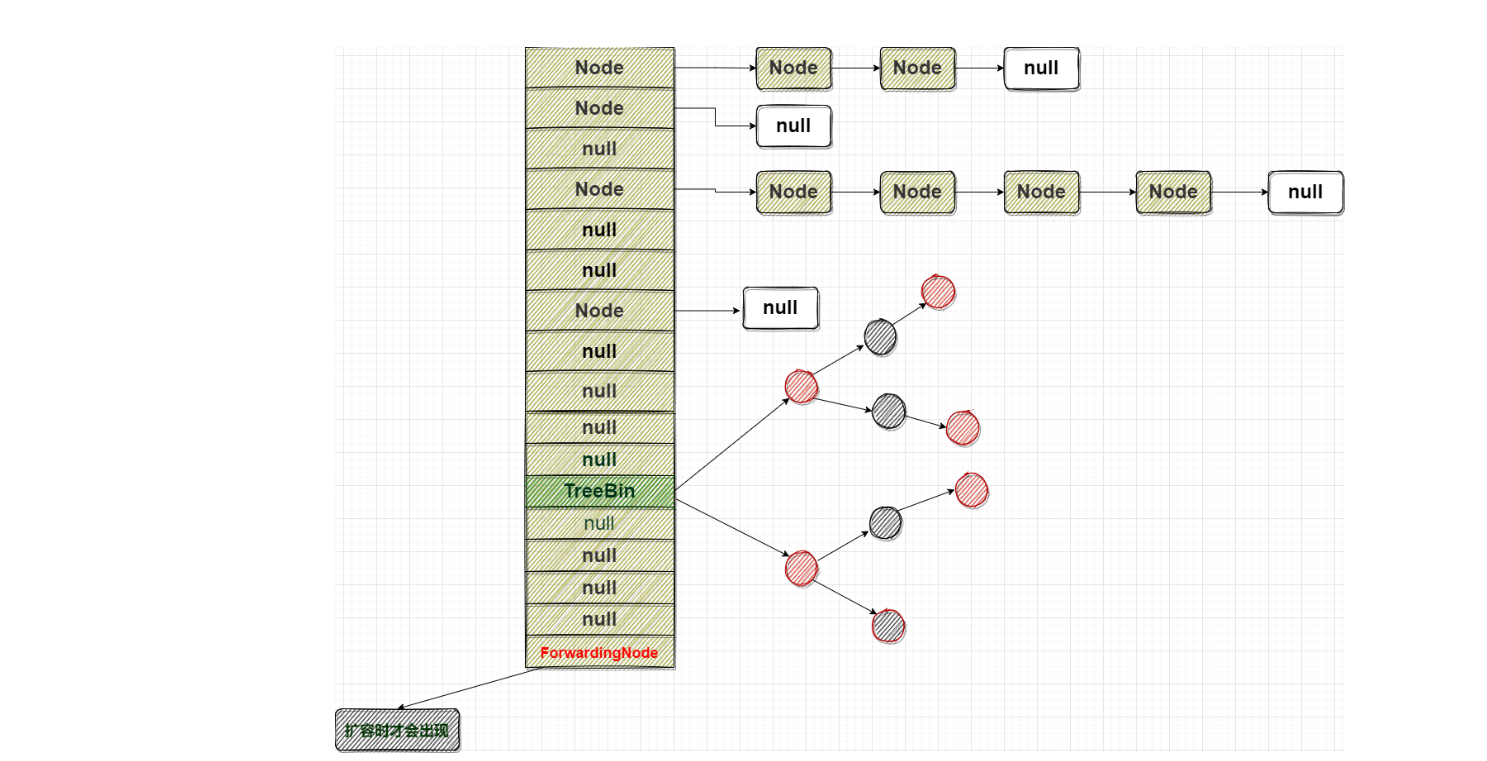
ConcurrentHashMap的数据结构与HashMap差不多,都是Node数组+红黑树+链表;ConcurrentHashMap中table的节点类型有 3 类:
Node节点,是链表类型的节点;这类节点hash 大于 0 ;
在扩容时ConcurrentHashMap会有一个特殊的标志对象:ForwardingNode;hash值: MOVE(-1)
在生成红黑树时,会生成一个TreeBin对象放在table中;hash值:TREEBIN(-2)
因此在put值时,会根据table中node的hash判断节点的类型;
hash>=0,Node是链表类型的节点;
hash=-2,是TreeBin,表示该table元素是红黑树的节点;
hash=-1,是ForwardingNode;容器正在扩容
hash = -3,是ReservationNode,在调用computeIfAbsent方法时可能会使用的占位对象(本文不讨论computeIfAbsent方法,因此只关注前三种对象)
ConcurrentHashMap和HashMap的put值过程有些类似,ConcurrentHashMap的结构也是table + 链表+ 红黑树;在put值时,锁粒度是table的元素;也就是说,当put值时定位到table的第 i 个元素,那么就会给table[i]上锁;
其他线程在put值时也定位到 i 时就需要等待获取锁;如果是其他位置则不需要等待锁,可以进行put操作。
二、计算hash值
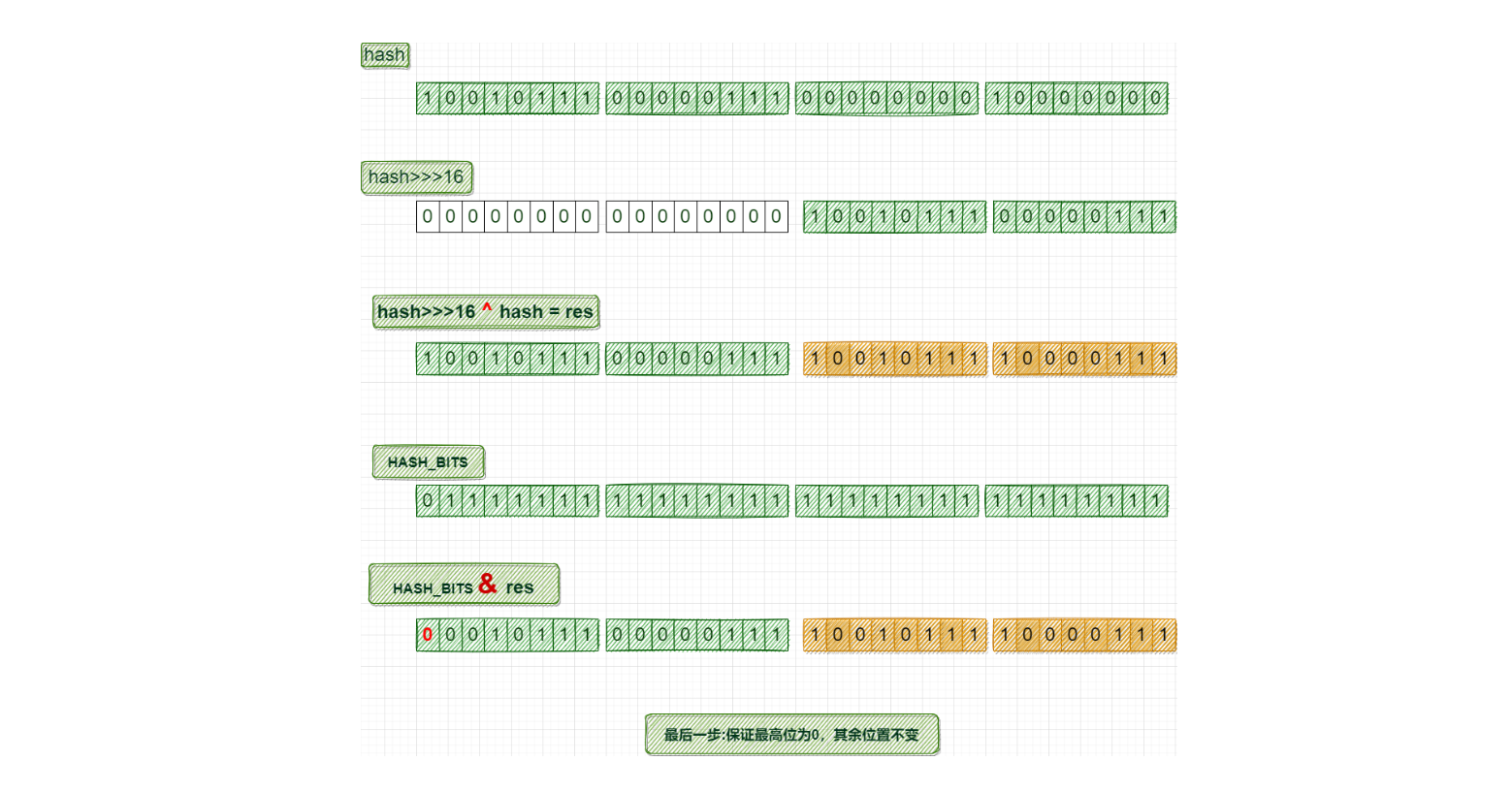
ConcurrentHashMap在put值的时候会计算key的hash值,和HashMap类似;在ConcurrentHashMap计算hash值的是spread方法

获取key的hashcode
利用hashcode的高16位与低16位做" ^ "位运算,让高位也参与位运算,增加离散型
再与HASH_BITS位运算,这是int最大正整数:最高位为0,其余位置为1,用来与hash值做 " & "运算;得到的结果保证最高位为0,其余位置不变;这样就保证得到的hash值是一个非负数;
举个例子:
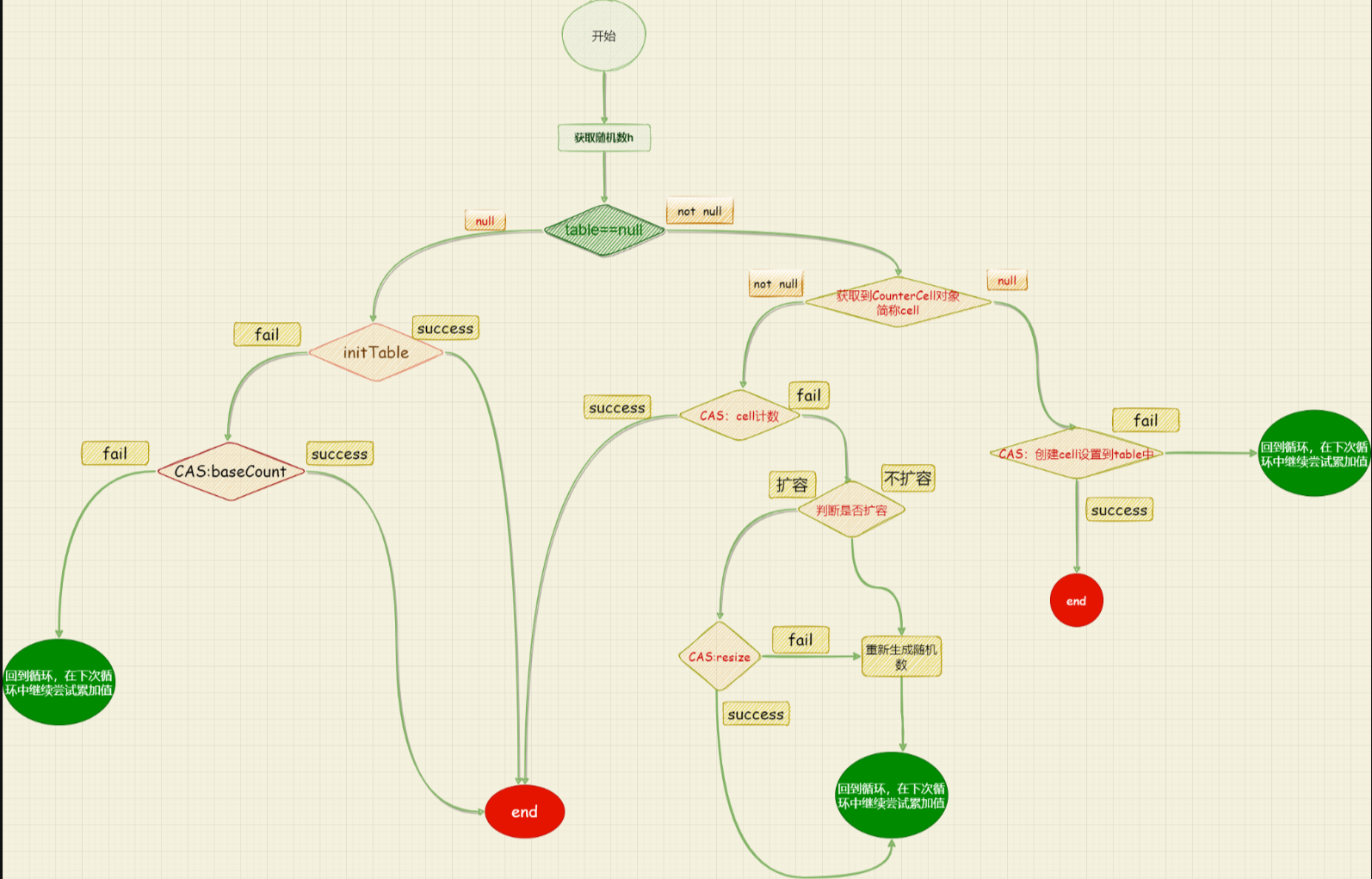
三、initTable
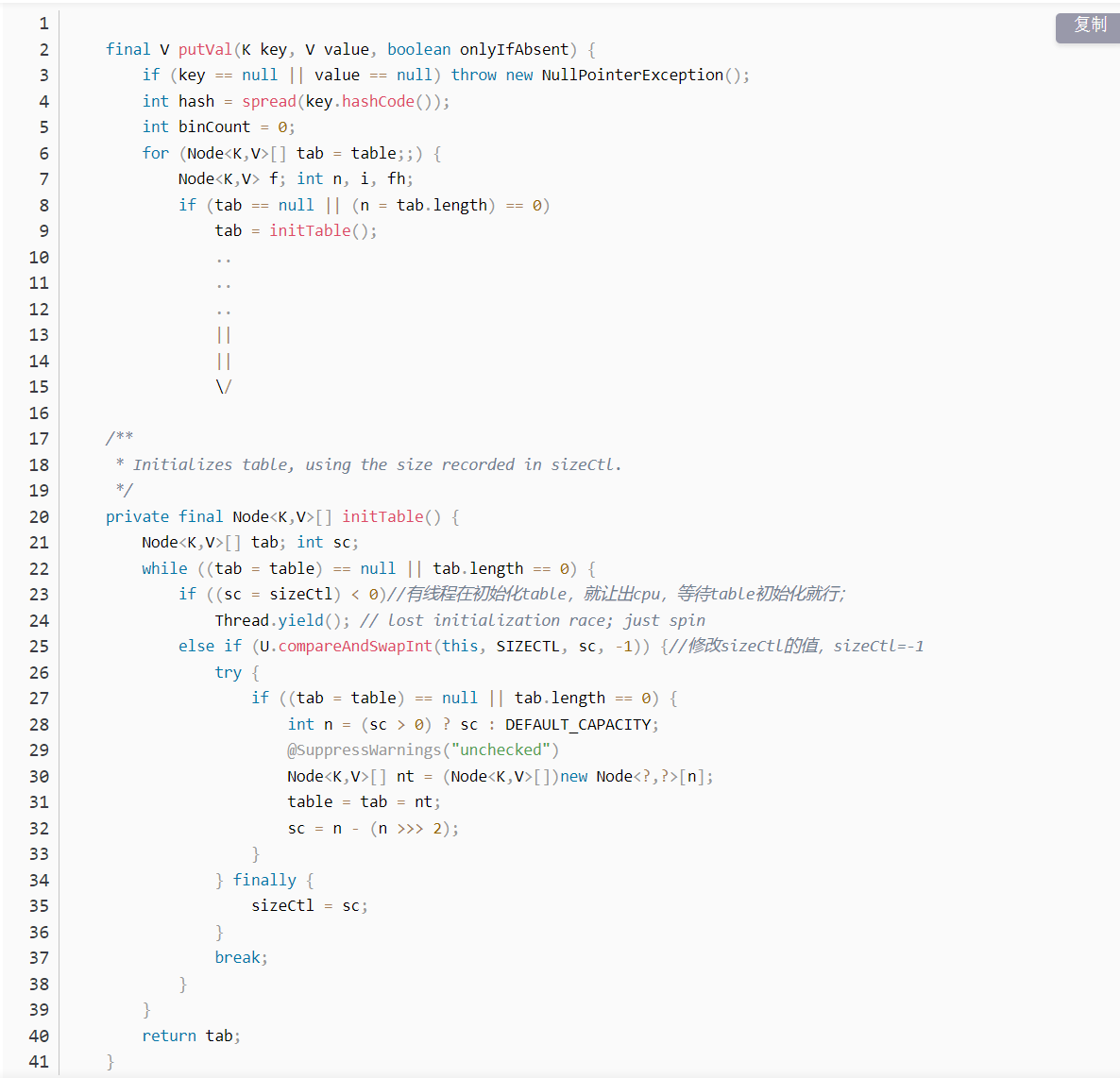
在put值时有几个判断,与HashMap类似
判断table是否已经初始化了;如果是没有初始化,就会先初始化table,再往table中添加值;
根据hash值,计算出key-value在table的位置i,判断table[i]是否已经插入了值;如果没有插入值,就将该key-value插入到table[i]中;
判断table[i]的hash值是否是MOVE,如果是MOVE表示正在扩容(ForwardingNode的hash值就是MOVE),需要该线程帮忙将旧容器的值移动到新容器中
将key-value插入到链表或者红黑树中
判断是否需要扩容
3.1、初始化table
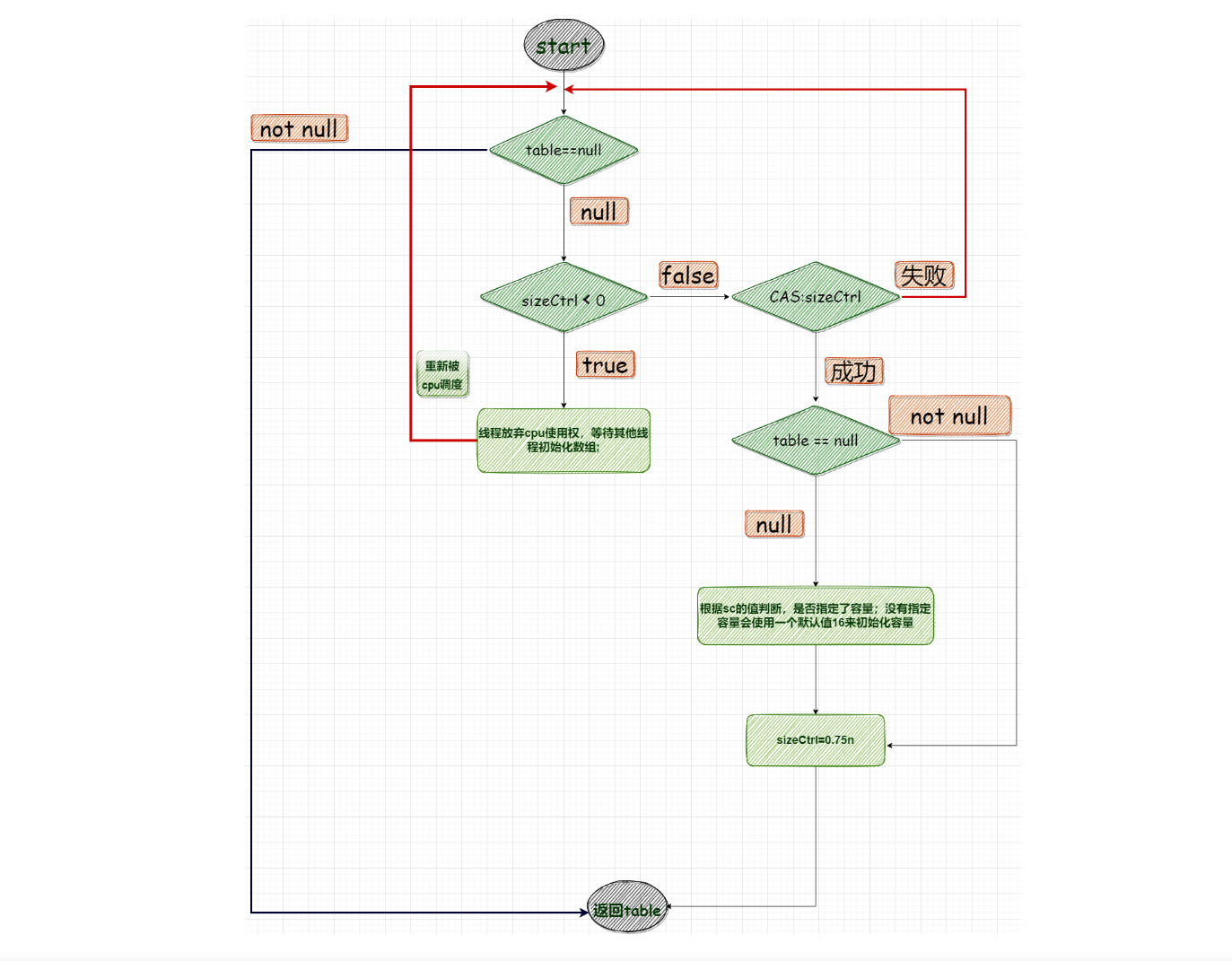
因为是多线程环境,就需要考虑到如果有多个线程同时初始化table的情况;假如现在有三个线程:A、B、C 同时判断到table == null。这个时候三个线程都会同时试图来初始化table,如果一个线程抢先修改了 sizeCtl,
他就可以初始化table,其余线程只需要等待初始化完成即可;
1、sizeCtl判断是否已经有线程初始化table,如果sizeCtl=-1,表示已经有线程对table初始化;这个时候会调用yield()让出cpu执行权
2、通过CAS修改sizeCtl=-1,初始化table
这段代码,有意思的是进入到初始化table的分支时 try{} finally{} 代码块还要判断 table==null,为什么呢 ?
可能是对应这样一个场景:现在有 A ,B,C三个线程都判断table=null进入到initTable,A,B线程先获取到sizeCtl =0,此时A抢先修改到sizeCtl =-1开始初始化,而B线程修改失败,再次通过循环获取sizeCtl =-1,
调用yield()放弃cpu执行权,等待A线程初始化table;A线程初始化完成之后修改sizeCtl 的值,修改后的sizeCtl >0;
而C线程比A,B线程慢一点,当C线程获取到sizeCtl的值时,A线程已经完成了table的初始化sizeCtl >0,C线程获取到的sc=sizeCtl >0,因此不会进入到休眠状态,会尝试修改sizeCtl 的值,这个时候没有其他线程竞争修改值,
因此会修改成功;又会将sizeCtl 的值修改为 -1 ,【此时:sc=A线程初始化之后sizeCtl 的值;sizeCtl =-1】
进入到try代码块,判断table!=null,不会再重新初始化table,进入finally块,sizeCtl =sc;将sizeCtl 的值还原到A线程初始化时候的值;
添加的table=null的判断保证了只会有一个线程能初始化table;
流程:
3.2、思考
在try代码块中判断table是否已经初始化保证了只有一个线程能初始化table,这个 和 DCL(双重检测枷锁,差不多);这段代码能修改吗 ?

因为只要sizeCtl != 0,就说明已经有线程在初始化table,其余线程都可以等待带线程初始化完成,这样当线程获初始化table的时就不用再判断table是否为null了,因为只能有一个线程能进入这个分支,对table进行初始化;
这样看起来似乎没什么问题,但是忽略了一个问题,在ConcurrentHashMap的构造对象中有一个构造方法可以指定初始容量,而保存初始容量的变量就是sizeCtl ,也就是说如果指定了初始容量sizeCtl 值就 大于0;
而指定初始容量时并不会初始化一个数组;因此不能修改成:(sc = sizeCtl) != 0,如果修改成这样,那么在指定初始容量之后,所有线程都不能初始化table了;同时也可以看到在初始化时利用了sizeCtl的值:

四、通过hash值定位key-value位置

这个分支其实就是判断table[i] = null,就将key-value值包装程成Node对象,放到table[i]中即可;
i = (n - 1) & hash;与HashMap一样,定位存储下标,因为使用了 & 运算,因此要求table的容量n一定是2的幂次倍;
casTabAt()将hash-key-value包装成node添加到table中,添加成功:返回true,进入分支break,结束put操作;不成功:进入下一次循环,继续put操作直到成功为止;
五、判断ConcurrentHashMap是否正在扩容

在上一个分支,如果table[i] != null,就会在接下来的分支中,首先通过node节点的hash值判断,table是否处于扩容状态,如果是扩容状态: hash == MOVE;
当判定在扩容时,会要求这个线程帮忙完成扩容:

扩容暂时在这里不分析,在后面会讲到;因为扩容是添加node导致,在添加元素之后会判断是否需要扩容;在前面提到过,在扩容时会产生:ForwardingNode;它的hash值就是MOVE(-1);由于扩容实在太复杂,
并且扩容的原因并不在这里;扩容触发条件是添加node之后size到达扩容阈值触发扩容;因此把扩容的部分放在最后;
六、判断节点的类型,并添加节点;
判断节点类型,并添加值:
如果是链表,就将值打包成Node,添加到链表中;
如果是红黑树,就将值打包成TreeNode添加到红黑树中
这个过程和 HashMap一样;唯一的区别是,在多线程环境下,在确定table的下标之后,会获取table[i]对象的锁,只能有一个线程在table[i]所在的链表或者红黑树put值;其他线程要在table[i]中put值需要等待获取锁;
// f = tabAt(tab, i = (n - 1) & hash)
else {
V oldVal = null;
synchronized (f) {//获取table[i]的对象锁
if (tabAt(tab, i) == f) {//判断是否被修改
if (fh >= 0) {//根据node的hash值判断是链表还是红黑树
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 已经存在key,更新val,返回旧value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// key在链表中不存在,将key-value打包成Node插入到链表表尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;//p !=null ,说明在红黑树中已经存在key,只是更新了value;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
为了更好的看清上面代码的整体逻辑,去掉部分代码,留下一个大的框架:
//当有一个线程 : A ,锁定table[i]时,其余线程如果也是锁定这个位置,就必须等A线程,put完成之后;
//获取到table[i]的锁,才能在这个位置put值;
synchronized (f) {
//判断节点没有变动;如果变动了,就计入下一次循环;
//f发生改变的几种情况:
//1:有可能链表变成红黑树,
//2:可能容器在扩容;
//3:如果其他线程在之前进行了remove操作,导致f被删除,这种情况也不能直接put;
//还有一种情况:就是key-value的值被修改,这种情况对下一个线程put值没有影响;
//因此可以看到在很多地方,对节点进行操作前,都会先判断节点有没有改变;
if (tabAt(tab, i) == f) {
if(fh>=0){
binCount=1;
链表,会将新node添加到链表末尾,在这个过程中binCount会记录链表的长度,用来判断是否需要将链表修改为红黑树;
还有一种情况是这个key已经存在,就直接更新value;
}else if(f instanceof TreeBin){
binCount=2;
红黑树,这里的binCount就是只用来表示该线程抢到锁,已经put值了;
}
}
}
//说明已经添加了node;binCount=0是因为线程没有put值,
//f已经被其他线程删除,或者是正在扩容,或者是由链表改成了红黑树。。
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)//这里是用来判断链表需不需要改成红黑树;
treeifyBin(tab, i);
if (oldVal != null)//key已经存在了,会将value更新;并返回旧值oldValue
return oldVal;
break;
}
流程图
https://www.processon.com/diagraming/67b0c2e0d2d43e3414024c7c
6.1、表转换成红黑树
上面流程图中判断:f是TreeBin对象时表示红黑树节点;但红黑树的节点是由TreeNode保存;那么在链表转换成红黑树的转换过程是什么 ?
在上述流程图中,可以看到链表转换成红黑树是由treeifyBin方法中进行的;treeifyBin的流程:
判断table长度;如果len < 64,就将容器扩大2倍;
len>=64;先将Node链表 -> TreeNode双向链表;再生成一个TreeBin对象放在table中;TreeBin的hash=-2;TreeBin的构造方法中将:链表 -> 红黑树;并且这个TreeBin对象包含链表转换前的头节点,以及转换后红黑树的根节点;
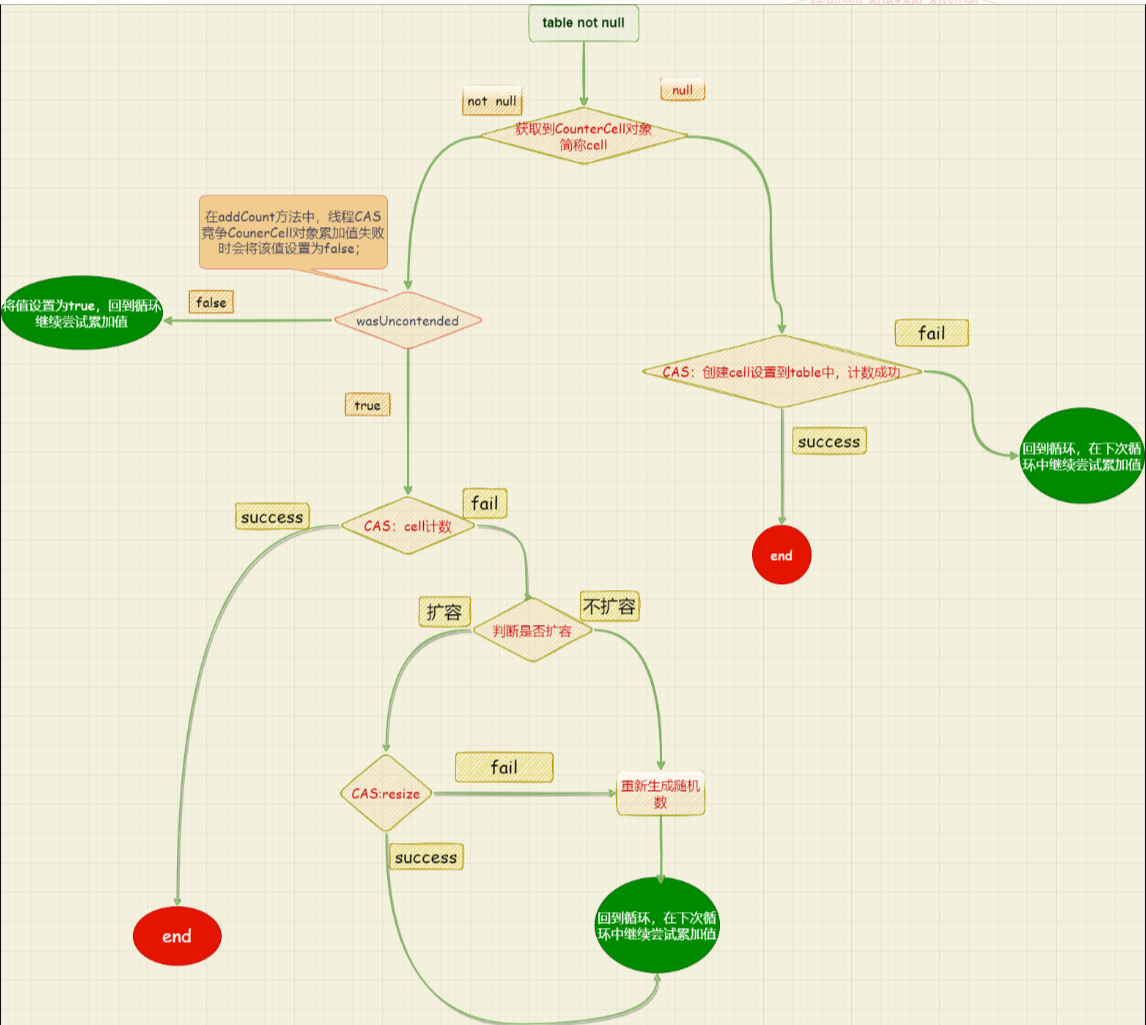
七、addCount()
首先是在多线程环境下如何计数?再一个就是多线程如何扩容?后续再分析吧。
6.1、ConcurrentHashMap多线程计数原理
先说下多线程计数的原理吧,这里没有直接使用CAS来更新size的值;是为什么呢 ?
先来看下使用直接使用CAS有什么利弊 ?
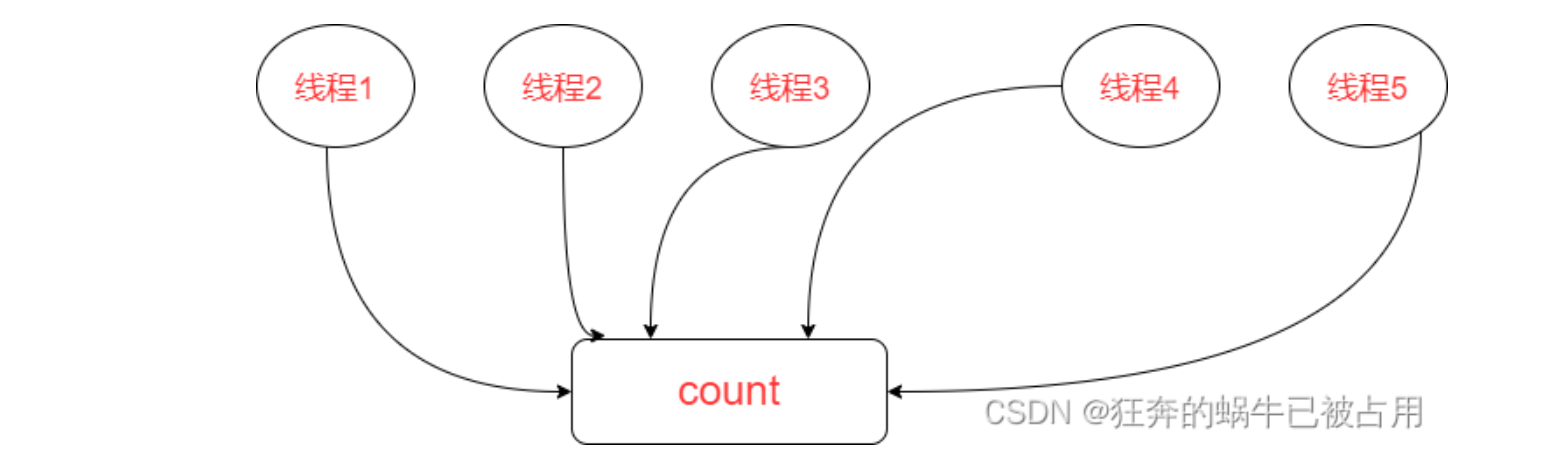
在多线程环境下,直接使用单一变量用CAS更新size虽然可以保证数据的正确性,但是效率不高;如果线程竞争比较激烈多个线程同时更改size,就需要多个线程排队更改值;可以看到并发特别高的话,这样的做法效率就不高了,
会让其他线程消耗cpu做空循环,占用了cpu又没做事;
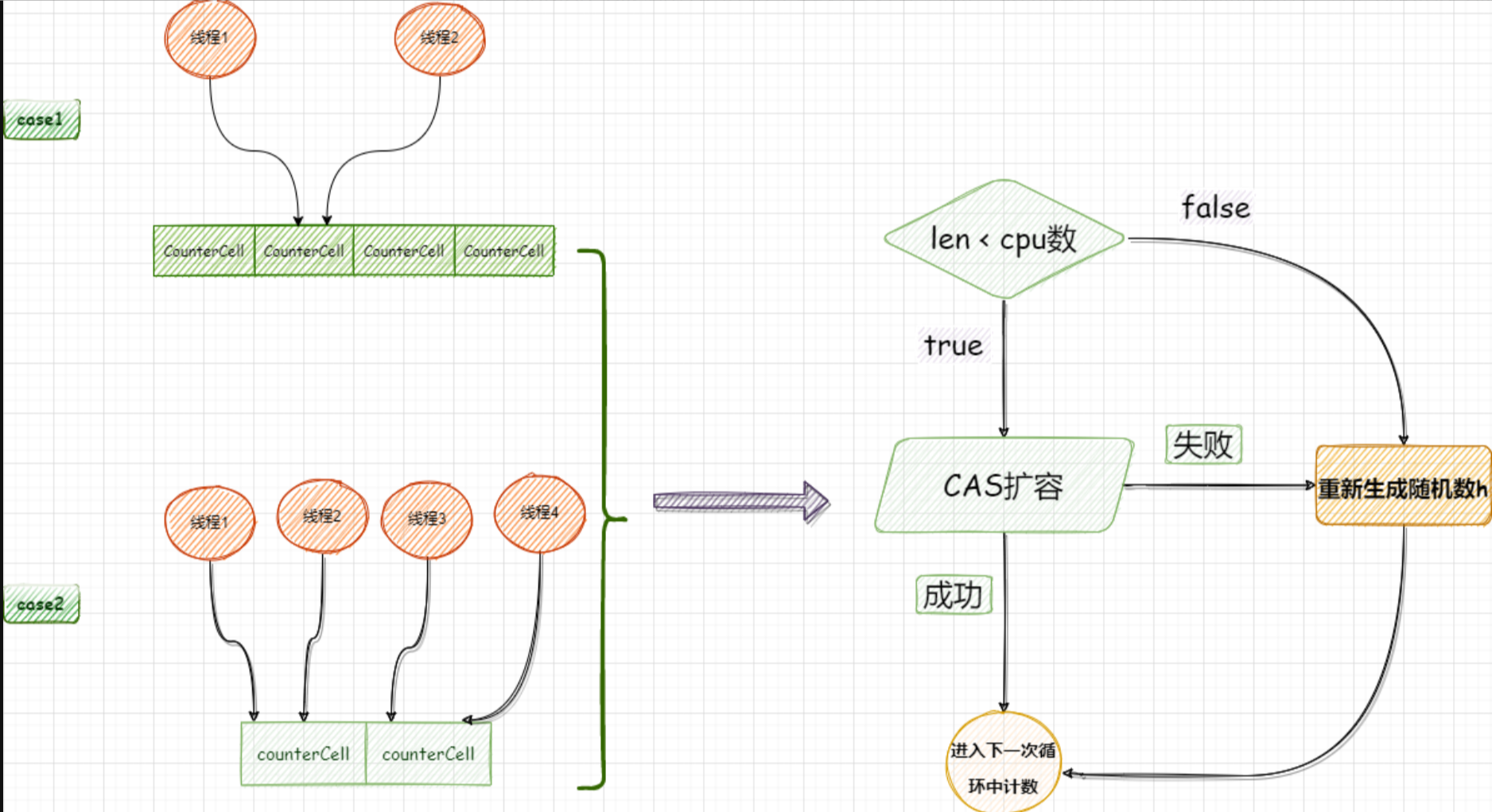
因此,ConcurrentHashMap采用了另一种高效的做法;设计了一种数据结构:基础值 + 数组;

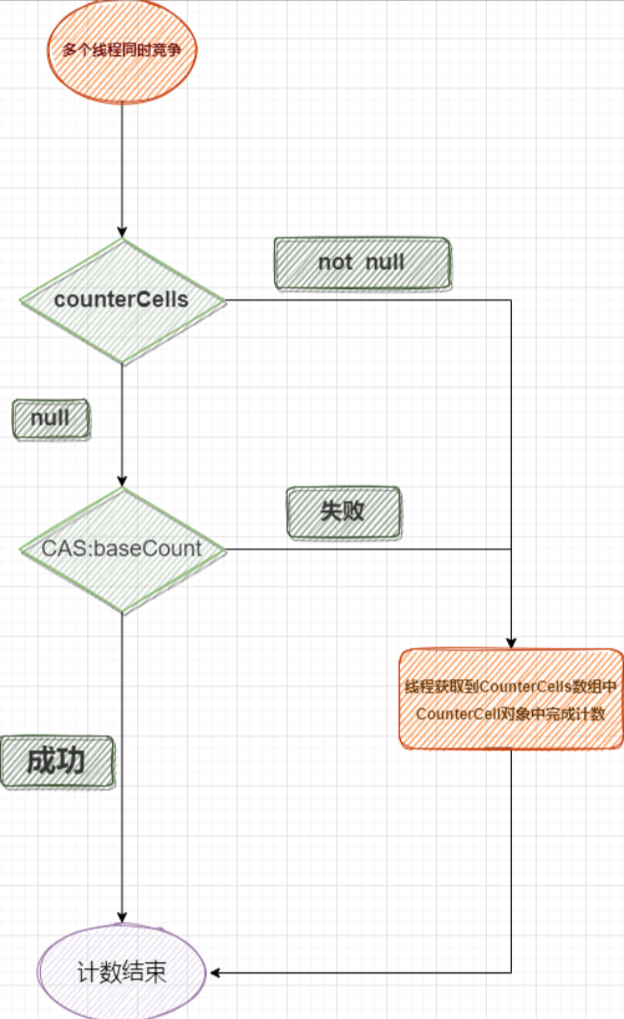
如果是多个线程同时put值需要更新size,进入到addCount中;这个时候仍然会先使用CAS更新baseCount,但是只有一个线程能更新成功;其余线程会分别将值更新到counterCells,如下图:

这就是ConcurrentHashMap在多线程环境下更新size的方法;相比直接使用CAS对一个变量更新,这种方法显然更高效;
6.3
ConcurrentHashMap的更新size的大体原理就是这样,但细节处有所不同;CounterCells数组是一个懒加载,也就是说,没有多个线程同时竞争修改baseCount时,不会生成CounterCells数组,
直接用CAS修改baseCount;当有多个线程竞争修改baseCount时才会生成CounterCells数组,每个线程在各自的CounterCell中计数互不干扰;
这里说明一下,即使生成了CounterCells数组,也不会立即将CounterCells数组中所有元素都初始化一个CounterCell对象;ConcurrentHashMap的设计突出一个懒加载,生成数组时的策略是这样,
生成在CounterCell对象时也是需要用到时才生成CounterCell对象用于处理线程的计数;
6.4、addCount的计数部分
addCount源码:
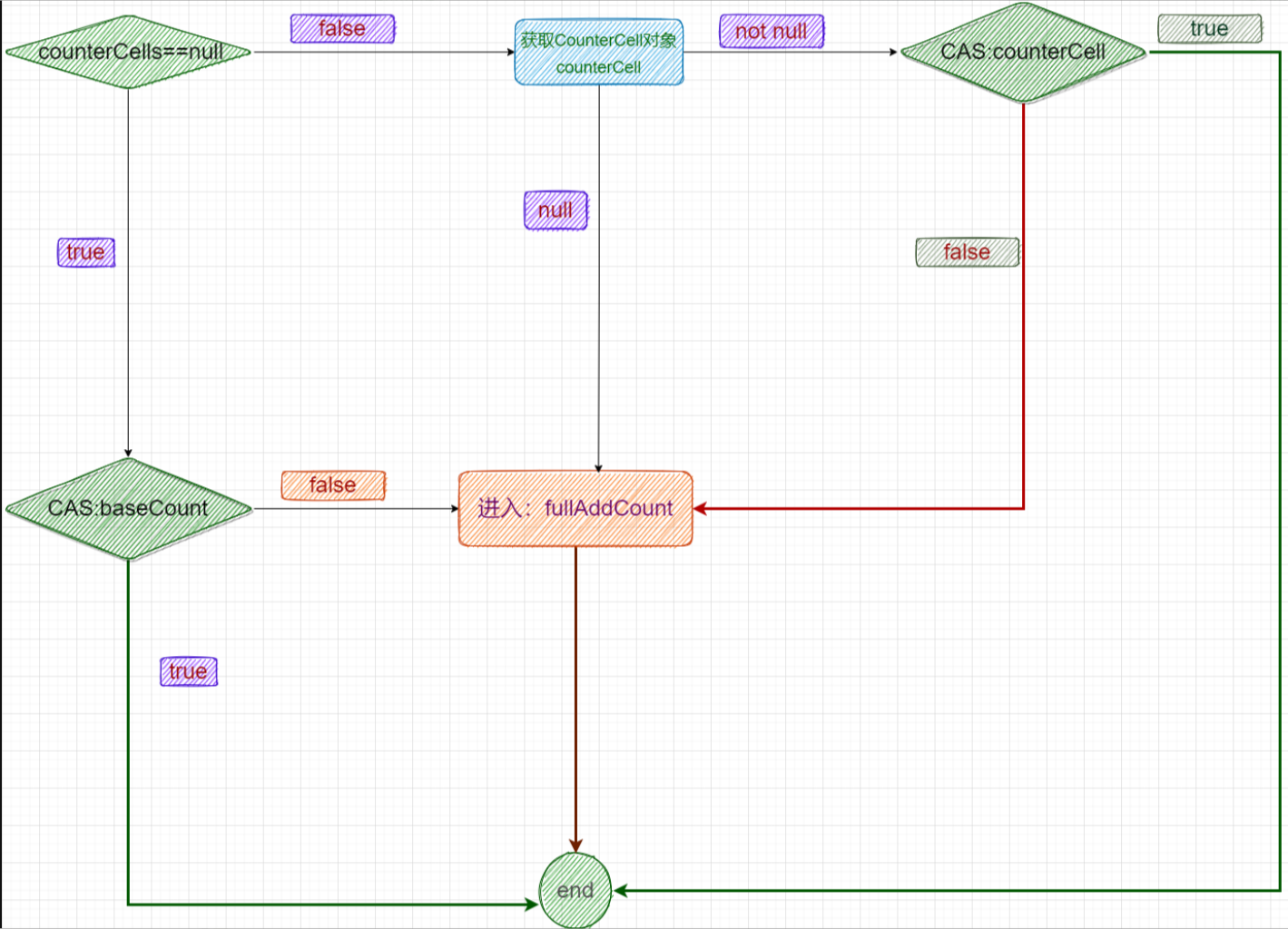
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;//b=baseCount,s = size;
/**
case 0:
如果生成了counterCells数组,就直接通过线程定位到cell,在其中累加值;
case 1:
如果counterCells没有初始化(没有生成counterCells数组)就通过CAS更新baseCount的值;
case 2:
counterCells==null && 更新baseCount的值失败; 一定有其他线程同时竞争更改baseCount的值,这个时候会生成
counterCells数组;让更新失败的线程,在counterCells数组中更新累加;
**/
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
/**
1.as == null || (m = as.length - 1) < 0 ===> counterCells还没有初始化,说明是通过CAS更改baseCount失败从而进入
到该分支,这个时候会进入到fullAddCount中具体操作;
2. (a = as[ThreadLocalRandom.getProbe() & m]) == null ;
说明已经初始化了counterCells;
【ThreadLocalRandom.getProbe() & m】通过线程私有的Random随机数生成器生成的随机数来确定处理线程的CounterCell;
最后得到的处理对象:a==null,说明counterCells[i]==null没有对象;进入fullAddCount中累加;
3. 如果a != null,则用CAS来修改CounterCell中value的值;如果CAS修改失败,进入fullAddCount中处理;
**/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
*******************************************************************************************
//扩容部分暂且省略。
}
流程图:
6.5、多线程计数的核心fullAddCount
上图中可以看到,fullAddCount是核心方法,很多分支都会经过这个方法;关于cunterCells数组的初始化,扩容,以及cunterCell计数都在这里面;
在看fullAddCount方法之前简单介绍fullAddCount处理的流程:
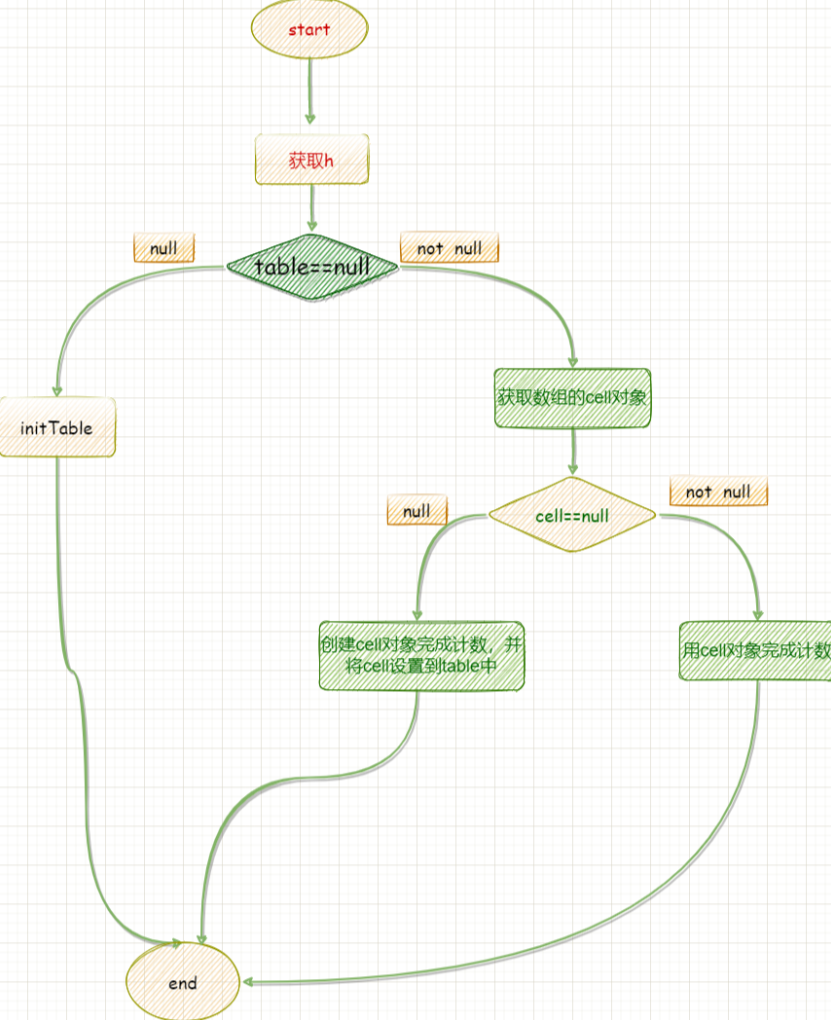
判断counterCells数组是否为空
counterCells为空,初始化counterCells数组;并生成CounterCell对象用于计数;
counterCells不为空,获取到CounterCell对象计数;如果对象为空,new一个对象来处理;如果计数失败,说明有多个线程在使用同一个CounterCell对象计数;这个时候将会扩容counterCells数组;(扩容长度最大到cpu的个数不再扩容)扩容之后再定位处理线程的计数;
下图是fullAddCount简易流程图:
保留代码整体框架,省略掉部分代码:
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
//每一个线程都可以通过ThreadLocalRandom,生成一个随机数,用来确定数组下标;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
if ((as = counterCells) != null && (n = as.length) > 0) {
数组非空的处理逻辑;
}
/**
*
*初始化counterCells数组
*和initTable差不多,通过一个标志cellsBusy 的状态 来确定,有没有 线程初始化counterCells 数组
*
**/
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {//判断是否已经初始化,因为cellsBusy 的状态会还原到0;
CounterCell[] rs = new CounterCell[2];//length = 2,从2开始。每次扩容都增加一倍;
rs[h & 1] = new CounterCell(x);// h & (n-1) = h & 1;定位下标;new对象累加值;
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;//状态还原
}
if (init)
break;
}
//当多个线程同时初始化counterCells 时,通过CAS竞争只有一个线程成功获取到初始化的权力,初始化数组;
//其余没有初始化数组的线程进入这个分支,尝试更新baseCount;没有成功进入下一次循环继续尝试累加。
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
counterCells 数组非空时的处理逻辑源码:
counterCells 数组非空时处理过程的简易流程图:
6.6、fullAddCount简略流程图:
6.7、为什么在线程在使用CounterCell对象计数时还是要使用CAS来更新值呢 ?
原因有以下2点:
在counterCells数组长度大于并发线程个数时:两个线程生成的随机数h不同,但是有可能定位到数组的同一个下标;这个时候如果两个线程同时进入到fullAddCount更新size就会产生冲突;这个情况下,要判断数组长度是否小于cpu个数;如果小于cpu个数首先尝试扩容;扩容失败时,线程会重新产生一个随机数,来获取一个新的下标解决冲突问题;
在counterCells数组长度小于并发线程个数时;必然造成多个线程同时使用一个CounterCell;会通过扩容来解决冲突;(这种情况,必定是数组长度小于cpu个数)
七、ConcurrentHashMap获取size
ConcurrentHashMap不是直接通过获取一个变量来获取size的;因为记录的方法:维护一个变量 baseCount + CounterCell数组;因此在获取size时,需要将counterCells数组中value的值累加,再加上 baseCount;
获取size的方法源码:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);//size超过int类型的范围,返回Integer.MAX_VALUE;没超过:long -> int;返回原值
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {//counterCells数组不为空,就累加counterCells数组的每一个CounterCell对象中value值;
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
八、ConcurrentHashMap获取size
在ConcurrentHashMap中,扩容是由多个线程同时参与的,这样会比较高效的完成数据的迁移。但这样就会有比较多的难点:
多线程下,在扩容时保证只能一个线程创建新容器;
多线程数据迁移时,如何协作多个线程同时迁移数据 ?
在addCount方法中,更新元素个数之后,得到元素个数size与扩容阈值sizeCtrl比较;size >= sizeCtrl && len < 最大容量值MAXIMUM_CAPACITY会扩容;源码
//s:元素个数,sc = sizeCtl,n = table.length
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// size >= sizeCtrl && len < 最大容量值MAXIMUM_CAPACITY 就会触发扩容;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {//当已经有线程扩容的时候,后进入的线程会看到sc(sizeCtrl ) < 0;
//这部分判断条件,直接看是看不懂的,必须对整个扩容操作过一遍才能搞懂这些变量是做什么的。
//这个分支,表示不用线程协助扩容;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//这个分支是表示需要线程协助扩容时,会进入的分支;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//这个分支是刚开始扩容时,新建数组时会进入这个分支;
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
sizeCtrl在ConcurrentHashMap中的多个地方出现,并且含义各不相同,做一个总结:
在创建ConcurrentHashMap对象时指定了容量大小,会将这个值存储在sizeCtrl中;(容量值会被tableSizeFor 修正为:2n,然后存入sizeCtrl)
在初始化数组时,会将sizeCtrl的值设为负数表示有线程在初始化数组;
在扩容时,将sizeCtrl的值设置为负数,表示有线程在创建扩容后的数组;
在初始化或扩容完成后,将szieCtrl的值设置为:0.75 * n;用做扩容阈值
ConcurrentHashMap(JDK1.8)put分析的更多相关文章
- ConcurrentHashMap(JDK1.8)为什么要放弃Segment
今天看到一篇博客:jdk1.8的HashMap和ConcurrentHashMap,我想起了前段时间面试的一个问题:ConcurrentHashMap(JDK1.8)为什么要使用synchronize ...
- ConcurrentHashMap源码及分析
ConcurrentHashMap是在jdk1.5版本开始,存在于java.util.concurrent包下.本文主要是针对jdk1.7版本. 由于HashMap是非线程安全的,HashTable虽 ...
- Java泛型底层源码解析--ConcurrentHashMap(JDK1.7)
1. Concurrent相关历史 JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全 ...
- Java并发(四):并发集合ConcurrentHashMap的源码分析
之前介绍了Java并发的基础知识和使用案例分析,接下来我们正式地进入Java并发的源码分析阶段,本文作为源码分析地开篇,源码参考JDK1.8 OverView: JDK1.8源码中的注释提到:Conc ...
- Java7/8 中 HashMap 和 ConcurrentHashMap的对比和分析
大家可能平时用HashMap比较多,相对于ConcurrentHashMap 来说并不是很熟悉.ConcurrentHashMap 是 JDK 1.5 添加的新集合,用来保证线程安全性,提升 Map ...
- 并发编程——ConcurrentHashMap#transfer() 扩容逐行分析
前言 ConcurrentHashMap 是并发中的重中之重,也是最常用的数据结果,之前的文章中,我们介绍了 putVal 方法.并发编程之 ConcurrentHashMap(JDK 1.8) pu ...
- concurrenthashmap jdk1.8
参考:https://www.jianshu.com/p/c0642afe03e0 CAS的思想很简单:三个参数,一个当前内存值V.旧的预期值A.即将更新的值B,当且仅当预期值A和内存值V相同时,将内 ...
- 多线程-ConcurrentHashMap(JDK1.8)
前言 HashMap非线程安全的,HashTable是线程安全的,所有涉及到多线程操作的都加上了synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下 ...
- 6.ConcurrentHashMap jdk1.7
6.1 hash算法 就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值.这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所 ...
- ConcurrentHashMap 并发HashMap原理分析
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁.如图 左边便是Hashtable的实现方式---锁整个hash表:而右边则是Concurrent ...
随机推荐
- 深入理解第三范式(3NF):数据库设计中的重要性与实践
title: 深入理解第三范式(3NF):数据库设计中的重要性与实践 date: 2025/1/17 updated: 2025/1/17 author: cmdragon excerpt: 在数据库 ...
- Django-Admin和第三方插件Xadmin
Admin django内置了一个强大的组件叫Admin,提供给网站管理员快速开发运营后台的管理站点. 站点文档: https://docs.djangoproject.com/zh-hans/2.2 ...
- 闲话 6.30 -JL 引理
参考了 https://spaces.ac.cn/archives/8679/comment-page-1,有一些增删. JL 引理 首先下面需要应用马尔可夫不等式的另一个形式: \[\newcomm ...
- 2024.11.14随笔&联考总结
前言 今天联考直接炸纲了.但是不得不说:HEZ 的题要比 BSZX 好多了. 联考 今天联考题说实话难度应该比较适合我.第一题是推结论的题,我赛时 20min 想出正解,但是有两个细节没有考虑清楚,导 ...
- 使用cy7c68013调试mt9v011 ov7670 摄像头测试 icamera视频采集调试
使用cy7c68013调试mt9v011 ov7670 摄像头测试 icamera视频采集调试 采集底板选用cp601d,原理图参考icamera设计,使用cy7c68013a芯片设计,固件刷ic ...
- 面试题30. 包含min函数的栈
地址:https://leetcode-cn.com/problems/bao-han-minhan-shu-de-zhan-lcof/ <?php /** 定义栈的数据结构,请在该类型中实现一 ...
- C语言线程池的常见实现方式详解
在 C 语言中,线程池通常通过 pthread 库来实现.以下是一个详细的说明,介绍了 C 语言线程池的常见实现方式,包括核心概念.实现步骤和具体的代码示例. 点击查看代码 1. 线程池的基本结构 线 ...
- Python脚本 | 提取pdf页面为jpg
功能: 提取pdf文件中的每一页,输出为jpg文件 以markdown语法写入文本文件 将该文本复制到剪贴板 # python 3.10 # ! 运行在 conda-myv虚拟环境 import fi ...
- 自己修改的一款Typora学术主题Academic-zh-vq
这款typora主题是在Academic-Zh主题的基础上修改而来的. 主题衍生路径: 官方Academic主题-->zh-academic主题-->Academic-Zh主题--> ...
- excel 文件提示已受损 解决方案
1.打开office excel 2.python 语言save 方法导致,将后缀改为.xls 3.用WPS打开