xlrd的使用详细介绍以及基于Excel数据参数化实例详解
1.安装xlrd
xlrd是python用于读取excel的第三方扩展包,所以在使用xlrd前,需要使用以下命令来安装xlrd。pip install xlrd
在使用这个命令之前先确定自己有没有安装pip模块
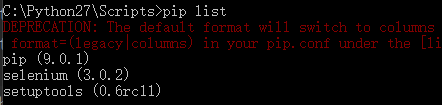
我们需要在C:\Python27\Scripts这个目录下来执行我们的pip命令
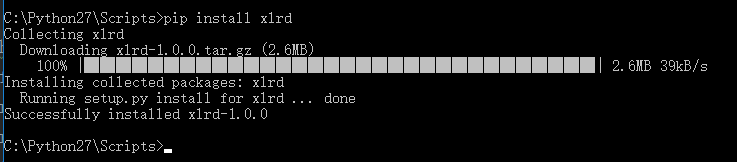
2.使用介绍
- 导入模块
import xlrd
- 打开excel表
excel=xlrd.open_workbook("excel.xls")
- 获取表格
#通过索引顺序获取
sytable=excel.sheets()[0]
sytable=excel.sheet_by_index(0)
#通过工作表名获取
bmtable=excel.sheet_by_name(u"Sheet1")注意:通过工作表名获取的"Sheet1"是填写你excel中标签"Sheet1","Sheet2","Sheet3"....
- 获取行数和列数
#获取行数
hs=bmtable.nrows
#获取列数
ls=bmtable.ncols - 获取整行货整列的值
#打印第一行的值
rows_values=bmtable.row_values(0)
print rows_values
#打印第一列的值
cols_values=bmtable.col_values(0)
print cols_values打印结果为:
C:\Python27\python.exe "D:/PyCharm Community Edition 5.0.3/代码/excel.py"
[u'\u82b1\u82b1 ', u'\u82b1\u82b1_\u767e\u5ea6\u641c\u7d22']
[u'bb', u'\u82b1\u82b1_\u767e\u5ea6\u641c\u7d22', u'\u563f\u563f_\u767e\u5ea6\u641c\u7d22', u'\u62c9\u62c9_\u767e\u5ea6\u641c\u7d22']注意:行号,列号是从索引0开始的
- 循环行列表值
#获取行数
hs=bmtable.nrows
#通过行数值的多少遍历出表格中的值
for i in range(1,hs):
print bmtable.row_values(i) - 单元格
cell_a1=bmtable.cell(0,0).value
print cell_a1
cell_b4=bmtable.cell(3,1).value
print cell_b4打印结果:
C:\Python27\python.exe "D:/PyCharm Community Edition 5.0.3/代码/excel.py"
aa
拉拉_百度搜索
表格信息
注意:索引是从0开始的,cell(3,1)的格式是cell(行row,列col)
总结示例:将表格中的所有的数值打印出来(表格还是上图的表格)
#coding=utf-8
import xlrd
excel=xlrd.open_workbook(u"aa.xlsx")
table=excel.sheet_by_index(0)
hs=table.nrows
for i in range(hs):
print table.row_values
打印结果:
3.示例演示
将上表格中的第一列内容到百度去搜索,然后将搜索的标题与表格的一列作比较
#coding=utf-8
from selenium import webdriver
import unittest
import HTMLTestRunner
import sys
from time import sleep
import xlrd
reload(sys)
sys.setdefaultencoding("utf-8")
class baidutest:
def __init__(self,path):
self.path=path
def load(self):
#打开一个excel文件
excel=xlrd.open_workbook(self.path)
#获取一个工作表格
table=excel.sheets()[0]
#获取工作表格的行数
nrows=table.nrows
#循环遍历数据,将他存到list中去
test_data=[]
for i in range(1,nrows):
print table.row_values(i)
test_data.append(table.row_values(i))
#返回数据列表
return test_data
class baidu(unittest.TestCase):
def setUp(self):
self.driver=webdriver.Chrome()
self.driver.implicitly_wait(30)
self.url="http://www.baidu.com"
self.path=u"aa.xlsx" def test_baidu_search(self):
driver=self.driver
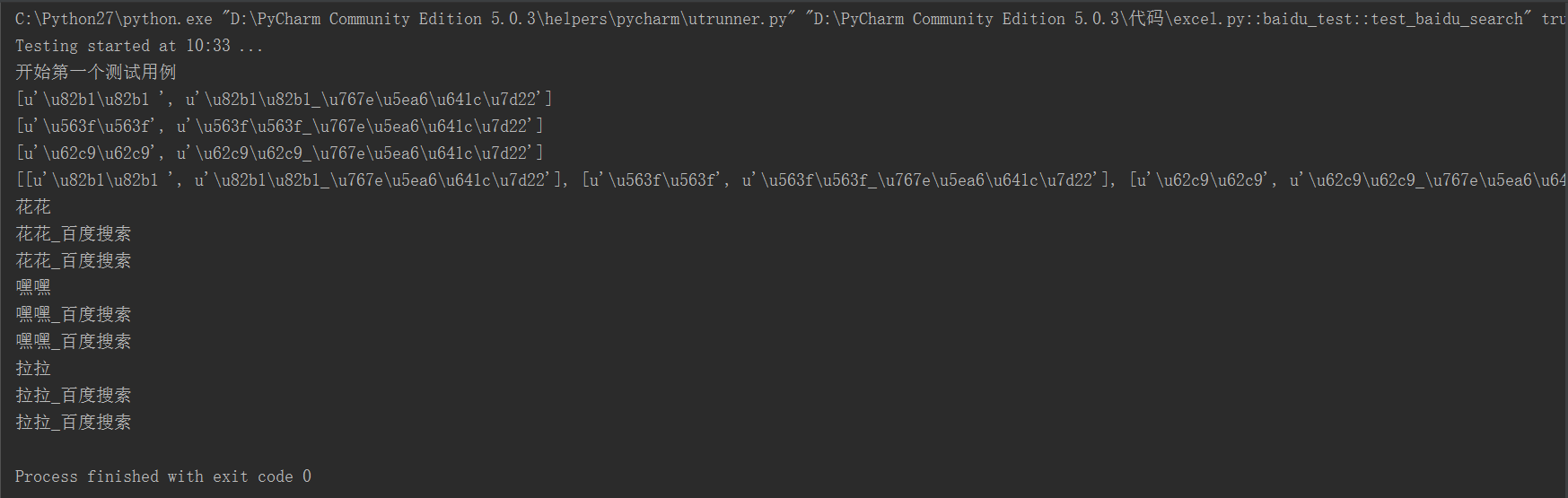
print u"开始第一个用例百度搜索"
#加载测试数据
testinfo=baidutest(self.path)
data=testinfo.load()
print data
#循环参数化
for d in data:
#打开百度首页
driver.get(self.url)
#验证标题
self.assertEqual(driver.title,u"百度一下,你就知道")
sleep(1)
driver.find_element_by_id("kw").clear()
#参数化搜索词
driver.find_element_by_id("kw").send_keys(d[0])
sleep(1)
driver.find_element_by_id("su").click()
sleep(1)
print d[0]
print driver.title
print d[1]
#验证搜索结果的标题
self.assertEqual(driver.title,d[1])
sleep(2) def tearDown(self):
self.driver.quit() if __name__=='__main__':
test=unittest.TestSuite()
test.addTest(baidu("test_baidu_search"))
htmlpath=u"D:\\aaaaaaaa.html"
fp=file(htmlpath,'wb')
runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"baidu测试",description=u"测试用例结果")
runner.run(test)
fp.close()
打印结果:
练习兔展的登录(参数化)
表格数据: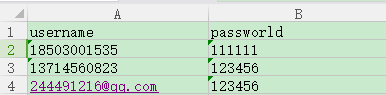
代码实例:
#coding=utf-8
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
import time
import xlrd
def excel():
data=xlrd.open_workbook('login.xlsx')
table=data.sheet_by_index(0)
nrows=table.nrows
print nrows
list=[]
for i in range(1,nrows):
print table.row_values(i)
list.append(table.row_values(i))
print list
return list
def login():
listdata=excel()
for d in listdata:
driver=webdriver.Chrome()
driver.get("http://www.rabbitpre.com/")
time.sleep(3)
driver.implicitly_wait(30)
driver.maximize_window()
driver.find_element_by_css_selector("span[class=\"login j-login\"]").click()
time.sleep(1)
driver.switch_to_frame(1)
print u"我要开始登陆咯"
time.sleep(3)
driver.find_element_by_xpath("//div[@id='LOGREG_1000']//input[@class='user-account']").clear()
driver.find_element_by_xpath("//input[@class='user-account']").send_keys(str(d[0]))
driver.find_element_by_xpath("//div[@id='LOGREG_1000']//div[contains(@class,'login-container')]//input[@class='user-pass']").clear()
driver.find_element_by_xpath("//div[contains(@class,'login-container')]//input[@class='user-pass']").send_keys(str(d[1]))
driver.find_element_by_xpath("//div[@id='LOGREG_1000']//div[contains(@class,'login-container')]//button").click()
time.sleep(3)
try:
elem=driver.find_element_by_xpath("//div[@id='DIALOG_1000']//i[@class='icon icon-close']")
print u"登陆成功"
except NoSuchElementException:
assert 0,u"登录失败,找不到兔展公告" driver.quit()
if __name__ == '__main__':
login()
运行结果:

需要注意的地方:
- 在参数化表格数据的时候,如果数据是手机号,在运行代码的时候会自己后面补一位小数(解决方法,在excel中输入的时候,前面补上一个单引号)
- 在第17行与第18行之间,一定要记住是在for语句循环之后才能return的。不然永远都只能return第一行的数据
xlrd的使用详细介绍以及基于Excel数据参数化实例详解的更多相关文章
- 在java poi导入Excel通用工具类示例详解
转: 在java poi导入Excel通用工具类示例详解 更新时间:2017年09月10日 14:21:36 作者:daochuwenziyao 我要评论 这篇文章主要给大家介绍了关于在j ...
- 个人用户永久免费,可自动升级版Excel插件,使用VSTO开发,Excel催化剂安装过程详解及安装失败解决方法
因Excel催化剂用了VSTO的开发技术,并且为了最好的用户体验,用了Clickonce的布署方式(无需人工干预自动更新,让用户使用如浏览器访问网站一般,永远是最新的内容和功能).对安装过程有一定的难 ...
- 基于STM32的uCOS-II移植详解
百度:基于STM32的uCOS-II移植详解 源:基于STM32的uCOS-II移植详解
- NPOI2.2.0.0实例详解(十)—设置EXCEL单元格【文本格式】 NPOI 单元格 格式设为文本 HSSFDataFormat
NPOI2.2.0.0实例详解(十)—设置EXCEL单元格[文本格式] 2015年12月10日 09:55:17 阅读数:3150 using System; using System.Collect ...
- Java 并发专题 : Executor详细介绍 打造基于Executor的Web服务器
转载标明出处:http://blog.csdn.net/lmj623565791/article/details/26938985 继续并发,貌似并发的文章很少有人看啊~哈~ 今天准备详细介绍java ...
- Spring框架入门之基于xml文件配置bean详解
关于Spring中基于xml文件配置bean的详细总结(spring 4.1.0) 一.Spring中的依赖注入方式介绍 依赖注入有三种方式 属性注入 构造方法注入 工厂方法注入(很少使用,不推荐,本 ...
- RDIFramework.NET框架基于Quartz.Net实现任务调度详解及效果展示
在上一篇Quartz.Net实现作业定时调度详解,我们通过实例代码详细讲解与演示了基于Quartz.NET开发的详细方法.本篇我们主要讲述基于RDIFramework.NET框架整合Quartz.NE ...
- SQL Server-聚焦SNAPSHOT基于行版本隔离级别详解(三十)
前言 上一篇SQL Server详细讲解了隔离级别,但是对基于行版本中的SNAPSHOT隔离级别仍未完全理解,本节再详细讲解下,若有疑义或不同见解请在评论中提出,一起探讨. SNAPSHOT行版本隔离 ...
- Solr系列五:solr搜索详解(solr搜索流程介绍、查询语法及解析器详解)
一.solr搜索流程介绍 1. 前面我们已经学习过Lucene搜索的流程,让我们再来回顾一下 流程说明: 首先获取用户输入的查询串,使用查询解析器QueryParser解析查询串生成查询对象Query ...
随机推荐
- C语言 一维数组叠加为二维数组样例
这里参看memcpy的用法,将一个一维整型数组不停的叠加为二维数组 使用宏定义来控制二维数组的行列 代码如下: #include <stdio.h> #include <stdlib ...
- 读书笔记 effective c++ Item 12 拷贝对象的所有部分
1.默认构造函数介绍 在设计良好的面向对象系统中,会将对象的内部进行封装,只有两个函数可以拷贝对象:这两个函数分别叫做拷贝构造函数和拷贝赋值运算符.我们把这两个函数统一叫做拷贝函数.从Item5中,我 ...
- git 命令用法 流程操作
Git 是一款免费的.开源的.分布式的版本控制系统.旨在快速高效地处理无论规模大小的任何软件工程. 每一个 Git克隆 都是一个完整的文件库,含有全部历史记录和修订追踪能力,不依赖于网络连接或中心服务 ...
- BZOJ 1033: [ZJOI2008]杀蚂蚁antbuster(模拟)
坑爹的模拟题QAQ DEBUG多了1kb QAQ 按题意做就行了 注意理解题意啊啊啊啊 尼玛输出忘换行wa了3次QAQ CODE: #include<cstdio>#include< ...
- 使用yum安装cmake
一.搜索yum源中的CMake,查看源中最新的版本是什么,使用命令[root@localhost ~]# yum search cmake ,如果搜索出的结果过多可以配合grep命令来控制搜索结果. ...
- React Native与原生项目连接与发布
前面的各种环境配置按照官方文档一步一步来,挺详细,宝宝在这里就不多说废话了. 其次,前面的配置,我参照的这个博主的文章React Native 集成到iOS原生项目 下面是宝宝掉过的坑(半径15M): ...
- C#之系统异常处理机制
在系统开发过程中,BUG和异常产生是无处不在的,但是需要我们去做的就是不断去发掘异常.修改异常. 这篇文章主要谈谈我在系统中解决异常的几种方法: 1.控制台程序产生的异常: 在大多数的控制台程序中,运 ...
- MySQL备份说明
第一次发布博客,发现目录居然不会生成,后续慢慢熟悉博客园的设置.回正文--- 1 使用规范 1.1 实例级备份恢复 使用innobackupex,在业务空闲期执行,考虑到IO影响及 FLUSH TAB ...
- 每天一个Linux命令(07)--mv命令
mv命令是move的缩写,可以用来移动文件或者将文件改名,这也是个常用命令,经常用来备份文件或者目录. 1.命令格式: mv [选项] 源文件或目录 目标文件或目录 2.命令功能: 视mv命令中第 ...
- EntityFrameworkCore使用Migrations自动更新数据库
EntityFrameworkCore使用Migrations自动更新数据库 系统环境:Win10 IDE:VS2017 RC4 .netcore版本:1.1 一.新建ASP.NET Core Web ...