windows下安装redis3.2.100单机和集群详解
下载redis
下载地址:https://github.com/MicrosoftArchive/redis/releases
我下载的是3.2.100版本的Redis-x64-3.2.100.zip,解压后放到某个目录,比如:D:\Program Files\redis
在此目录下增加三个文件夹:single、cluster、log
Single:存放单机模式的配置文件
Cluster:集群模式下的配置文件等信息
log:存放日志文件
单机模式
在single文件夹下增加配置文件redis.conf,内容如下:
bind 127.0.0.1
port
loglevel verbose
logfile "D:/Program Files/redis/log/logredis7001_log.txt"
appendonly yes
appendfilename "appendonly.7001.aof"
cluster-enabled no
其中cluster-enabled=no表示不启用集群,即单机模式。。port为端口号。
在single文件夹下增加一个启动文件start.bat,内容如下:
@echo off
cd D:\Program Files\redis\Redis-x64-3.2.
D:
start redis-server ../single/redis.conf
双击start.bat开启单机的redis。。
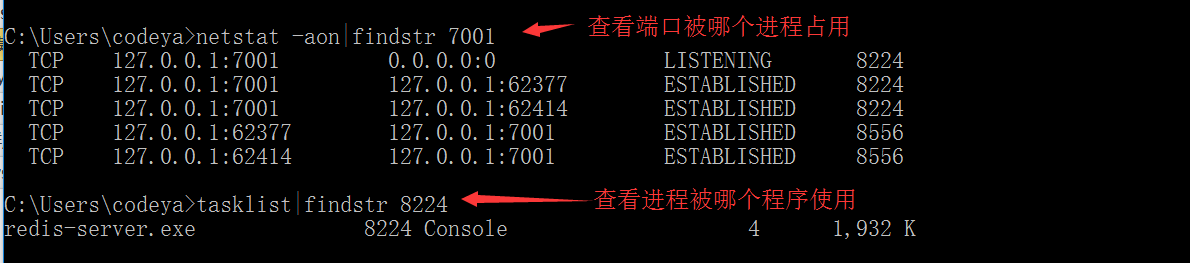
使用netstat -aon|findstr 端口号 查看端口被哪个进程占用
tasklist|findstr 进程号查看进程被哪个程序占用
集群模式
增加配置
在cluster文件夹下增加1个配置文件redis.7001.conf.内容如下。然后复制此文件5份,将内容中的7001部分改为7002、7003、7004、7005、7006
至此,我们增加了6个配置文件。
bind 127.0.0.1
port
loglevel verbose
logfile "D:/Program Files/redis/log/logredis7001_log.txt"
appendonly yes
appendfilename "appendonly.7001.aof"
cluster-enabled yes
cluster-config-file nodes-.conf
cluster-node-timeout
cluster-slave-validity-factor
cluster-migration-barrier
cluster-require-full-coverage yes

图片出自http://www.cnblogs.com/xckk/p/6144447.html
增加启动脚本start.bat,内容如下:
@echo off
cd D:\Program Files\redis\Redis-x64-3.2.
D:
start redis-server ../cluster/redis..conf
start redis-server ../cluster/redis..conf
start redis-server ../cluster/redis..conf
start redis-server ../cluster/redis..conf
start redis-server ../cluster/redis..conf
start redis-server ../cluster/redis..conf
启动6个redis实例
双击start.bat启动6个redis实例,会看到6个窗口。可以查看log目录的日志确认是否启动成功
目前这6个实例都起了,但是是相对独立了,还不是集群。。还需要后面的步骤。。
安装ruby
下载地址http://dl.bintray.com/oneclick/rubyinstaller/。我下载的rubyinstaller-2.3.3.exe。
。
下载后双击安装。。注意勾选
安装Redis的Ruby库
打开ruby客户端:
执行命令gem install redis
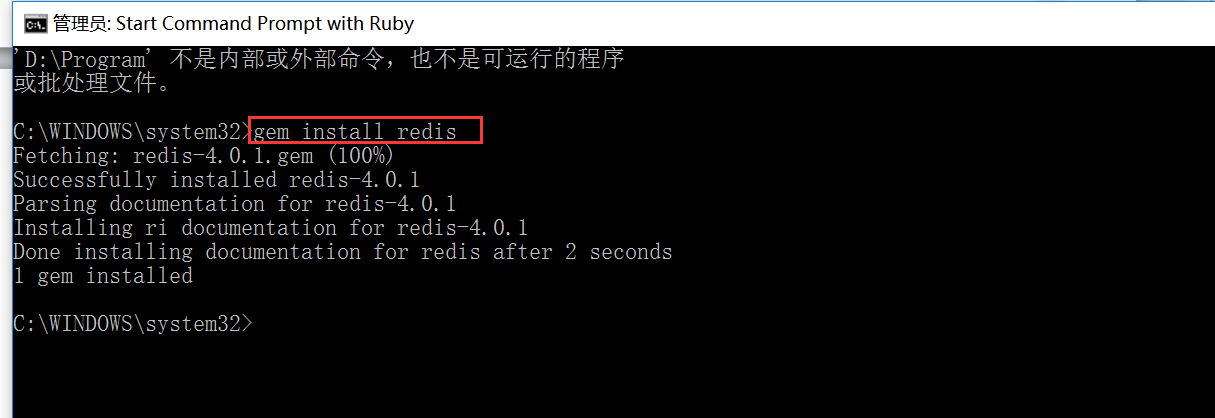
C:\WINDOWS\system32>gem install redis
Fetching: redis-4.0..gem (%)
Successfully installed redis-4.0.
Parsing documentation for redis-4.0.
Installing ri documentation for redis-4.0.
Done installing documentation for redis after seconds
gem installed
下载集群脚本redis-trib
下载地址 https://raw.githubusercontent.com/antirez/redis/unstable/src/redis-trib.rb
拷贝到某个文件夹,比如D:\Program Files\redis\cluster下

启动集群
打开命令窗口,执行命令
ruby redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
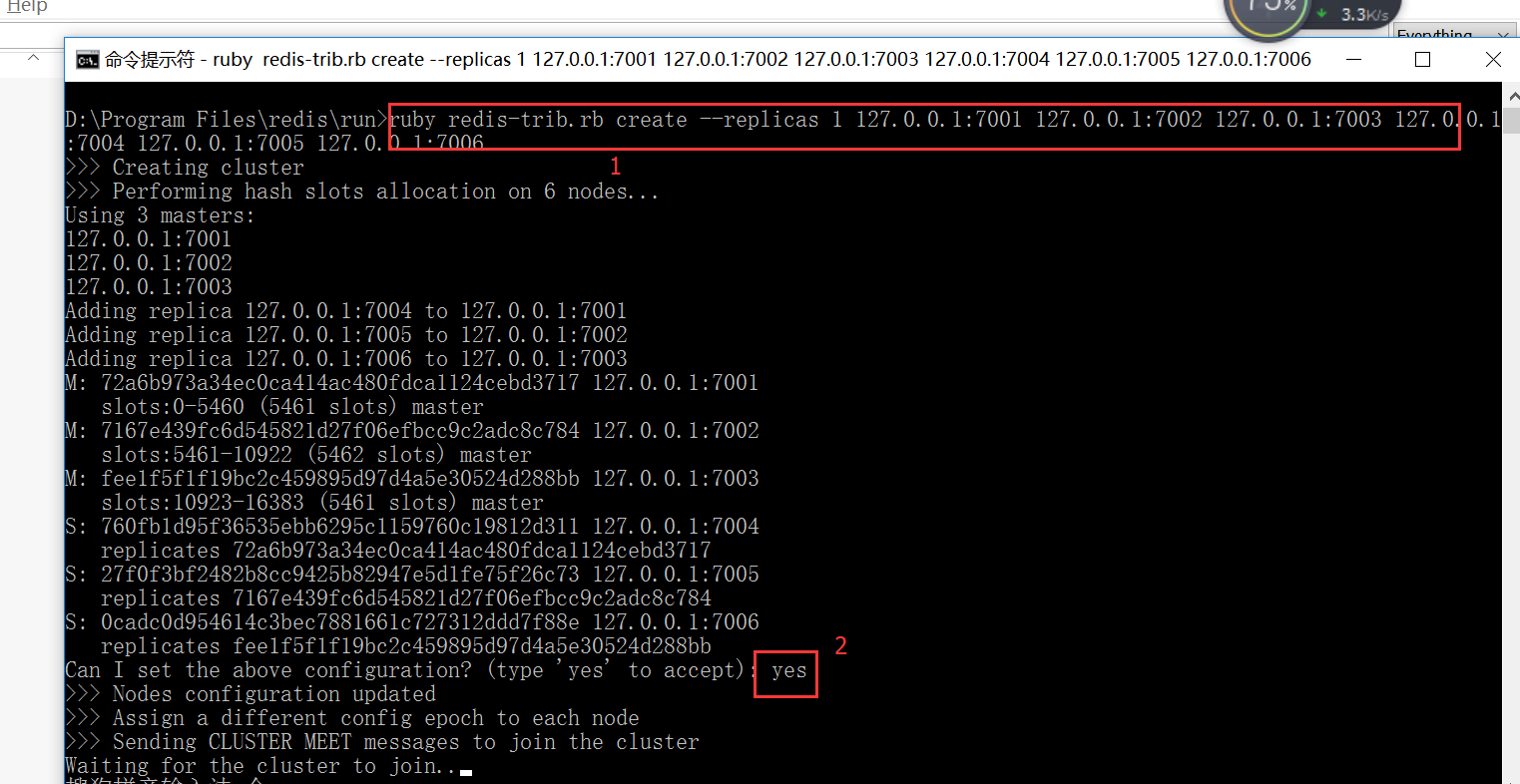
D:\Program Files\redis\run>ruby redis-trib.rb create --replicas 127.0.0.1: 127.0.0.1: 127.0.0.1: 127.0.0.1: 127.0.0.1: 127.0.0.1:
>>> Creating cluster
>>> Performing hash slots allocation on nodes...
Using masters:
127.0.0.1:
127.0.0.1:
127.0.0.1:
Adding replica 127.0.0.1: to 127.0.0.1:
Adding replica 127.0.0.1: to 127.0.0.1:
Adding replica 127.0.0.1: to 127.0.0.1:
M: 72a6b973a34ec0ca414ac480fdca1124cebd3717 127.0.0.1:
slots:- ( slots) master
M: 7167e439fc6d545821d27f06efbcc9c2adc8c784 127.0.0.1:
slots:- ( slots) master
M: fee1f5f1f19bc2c459895d97d4a5e30524d288bb 127.0.0.1:
slots:- ( slots) master
S: 760fb1d95f36535ebb6295c1159760c19812d311 127.0.0.1:
replicates 72a6b973a34ec0ca414ac480fdca1124cebd3717
S: 27f0f3bf2482b8cc9425b82947e5d1fe75f26c73 127.0.0.1:
replicates 7167e439fc6d545821d27f06efbcc9c2adc8c784
S: 0cadc0d954614c3bec7881661c727312ddd7f88e 127.0.0.1:
replicates fee1f5f1f19bc2c459895d97d4a5e30524d288bb
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join......
>>> Performing Cluster Check (using node 127.0.0.1:)
M: 72a6b973a34ec0ca414ac480fdca1124cebd3717 127.0.0.1:
slots:- ( slots) master
M: 7167e439fc6d545821d27f06efbcc9c2adc8c784 127.0.0.1:
slots:- ( slots) master
M: fee1f5f1f19bc2c459895d97d4a5e30524d288bb 127.0.0.1:
slots:- ( slots) master
M: 760fb1d95f36535ebb6295c1159760c19812d311 127.0.0.1:
slots: ( slots) master
replicates 72a6b973a34ec0ca414ac480fdca1124cebd3717
M: 27f0f3bf2482b8cc9425b82947e5d1fe75f26c73 127.0.0.1:
slots: ( slots) master
replicates 7167e439fc6d545821d27f06efbcc9c2adc8c784
M: 0cadc0d954614c3bec7881661c727312ddd7f88e 127.0.0.1:
slots: ( slots) master
replicates fee1f5f1f19bc2c459895d97d4a5e30524d288bb
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All slots covered.
根据运行结果可见前三个端口是主,后面三个是从。
可能会发现报错:
[136] 26 Jan 11:58:58.721 # Creating Server TCP listening socket *:7001: listen: Unknown error
[16656] 26 Jan 12:00:18.728 # Creating Server TCP listening socket *:7001: listen: Unknown error
这个报错需要在配置文件里加上
bind 127.0.0.1
参考文档
http://blog.csdn.net/yys79/article/details/51566417
http://blog.csdn.net/qiuyufeng/article/details/70474001
http://www.cnblogs.com/xckk/p/6144447.html
Linux安装可参考:
http://blog.csdn.net/chen8238065/article/details/52318635
http://www.cnblogs.com/cxzdy/p/5132108.html
http://www.cnblogs.com/xckk/p/6144447.html
windows下安装redis3.2.100单机和集群详解的更多相关文章
- ActiveMQ基础教程(二):安装与配置(单机与集群)
因为本文会用到集群介绍,因此准备了三台虚拟机(当然读者也可以使用一个虚拟机,然后使用不同的端口来模拟实现伪集群): 192.168.209.133 test1 192.168.209.134 test ...
- linux安装redis-6.0.1单机和集群
redis作为一个直接操作内存的key-value存储系统,也是一个支持数据持久化的Nosql数据库,具有非常快速的读写速度,可用于数据缓存.消息队列等. 一.单机版安装 1.下载redis 进入re ...
- Linux ->> UBuntu 14.04 LTE下安装Hadoop 1.2.1(集群分布式模式)
安装步骤: 1) JDK -- Hadoop是用Java写的,不安装Java虚拟机怎么运行Hadoop的程序: 2)创建专门用于运行和执行hadoop任务(比如map和reduce任务)的linux用 ...
- zookeeper的安装与配置(单机和集群)
单机模式: 1.首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz 2.用FTP上传到服务器或者Linux虚拟机的/usr/local目录下 3.解压文件tar -z ...
- Git学习系列之Windows上安装Git之后的一些配置(图文详解)
不多说,直接上干货! 前面博客 Git学习系列之Windows上安装Git详细步骤(图文详解) 第一次使用Git时,需要对Git进行一些配置,以方便使用Git. 不过,这种配置工作只需要进行一次便可, ...
- windows下在eclipse上远程连接hadoop集群调试mapreduce错误记录
第一次跑mapreduce,记录遇到的几个问题,hadoop集群是CDH版本的,但我windows本地的jar包是直接用hadoop2.6.0的版本,并没有特意找CDH版本的 1.Exception ...
- windows下通过idea连接hadoop和spark集群
###windows下链接hadoop集群 1.假如在linux机器上已经搭建好hadoop集群 2.在windows上把hadoop的压缩包解压到一个没有空格的目录下,比如是D盘根目录 3.配置环境 ...
- linux下安装 zookeeper-3.4.9并搭建集群环境
本文主要记录作者在实践过程中实现在centos7环境下安装zookeeper并搭建集群的详细步骤,关于zookeeper本文将不做详细介绍,安装步骤详情如下: 前提准备:3台linux服务器(因为zo ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
随机推荐
- CentOS下LAMP环境安装配置
本来几下yum都能装好的,yum却出问题了,报错:AttributeError: 'YumBaseCli' object has no attribute '_not_found_i',可能是某个文件 ...
- Layout 不可思议(一)—— CSS 实现自适应的正方形卡片
最近被一个布局问题给难住了,枉我一向自称掌握最好的前端技能是 CSS,写完博客就得敷脸去 需求是实现一个自适应的正方形卡片,效果如下: 顺便(开个坑)写个系列,总结那些设计精妙的布局结构 本次页面的 ...
- Ubuntu 16.04 升级 PHP 版本至 7.1
安装swoole扩展,怎么安装到7.0下去了,我本来编译的版本是7.19版本,但是没吃 升级步骤 $ sudo add-apt-repository ppa:ondrej/php $ sudo apt ...
- HttpRuntime.Cache .Net自带的缓存类
.Net自带的缓存有两个,一个是Asp.Net的缓存 HttpContext.Cache,一个是.Net应用程序级别的缓存,HttpRuntime.Cache. MSDN上有解释说: HttpCont ...
- Sql Server Configuration Manager 网络配置为空,没有实例
新用户一天内不准提问...Sql Server Configuration Manager 网络配置为空,没有实例无法设置ip和端口进行连接..
- es6 的循环
for-of 循环 for-of 不能直接用来遍历对象的属性,如果你想遍历对象的属性,你可以使用 for-in 语句(for-in 就是用来干这个的),或者使用下面的方式: for (let key ...
- java.io与网络通信
文件IO java.io.File是用于操作文件或目录的类: File file = new File("hello.txt"); 实例化File时不关心路径的目标并不会去读取文件 ...
- IdentityServer(15)- 第三方快速入门和示例
这些示例不由IdentityServer团队维护. IdentityServer团队提供链接到了社区示例,但不能对示例做任何保证. 如有问题,请直接与作者联系. 各种ASP.NET Core安全示例 ...
- 获取tranform参数函数的封装
平时我们都会去获取元素的各种属性值,例如宽高等等的值!但是tranform是个让人很头疼的点,获取出来的是矩阵,耐何线性代数学的并不是那么6啊. 解决方法的思路:只能采取有点取巧的方法,在我们设置的时 ...
- JavaScript字符串转换成数字的三种方法
在js读取文本框或者其它表单数据的时候获得的值是字符串类型的,例如两个文本框a和b,如果获得a的value值为11,b的value值为9 ,那么a.value要小于b.value,因为他们都是字符串形 ...