Spark源码剖析(八):stage划分原理与源码剖析
引言
对于Spark开发人员来说,了解stage的划分算法可以让你知道自己编写的spark application被划分为几个job,每个job被划分为几个stage,每个stage包括了你的哪些代码,只有知道了这些之后,碰到某个stage执行特别慢或者报错,你才能快速定位到对应的代码,对其进行性能优化和排错。
stage划分原理与源码
接着上期内核源码(五)的最后,每个action操作最终会调用SparkContext初始化时创建的DAGSchedule的runJob方法创建一个job:
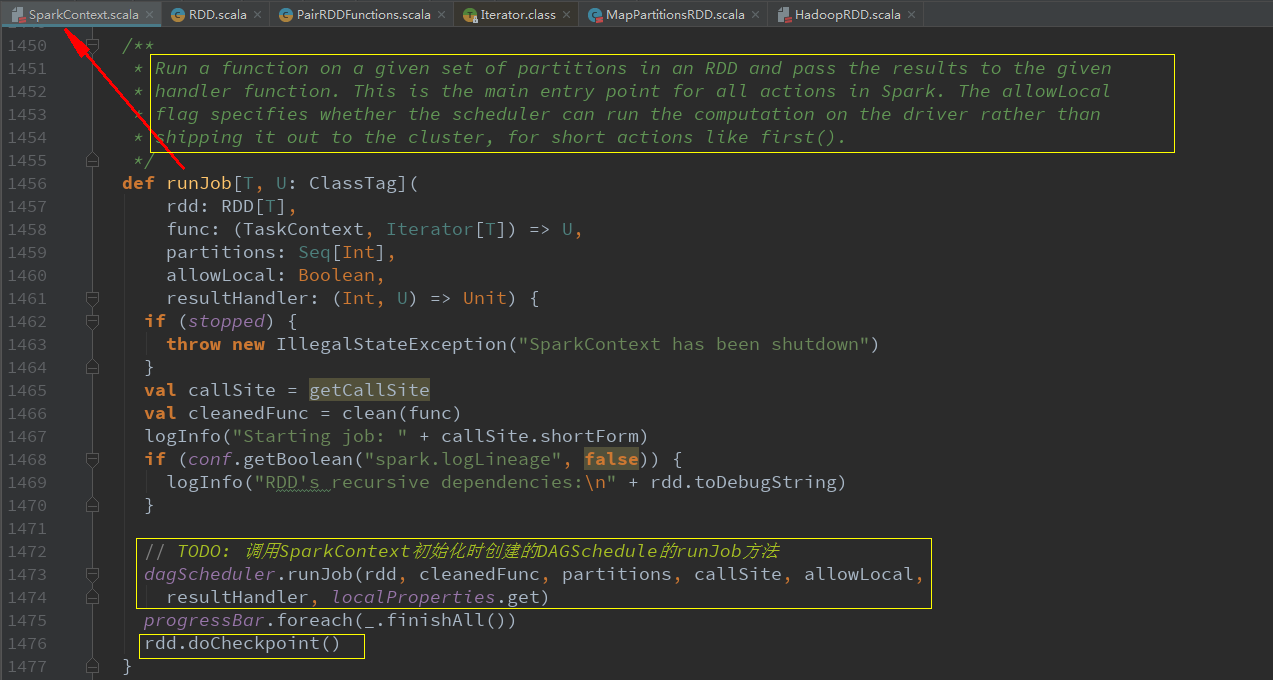
那么这一篇就我们来探究一下每个job中stage到底是如何划分的
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get)
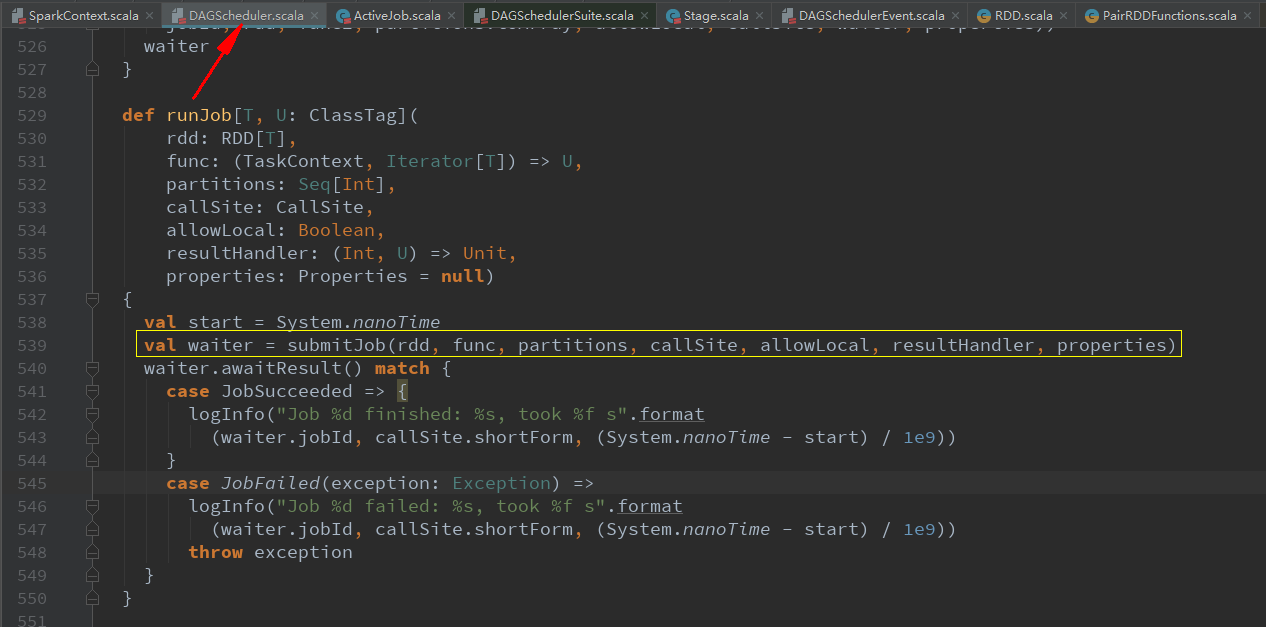
val waiter = submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties)

eventProcessLoop.post(JobSubmitted( jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties))

new DAGSchedulerEventProcessLoop(this)
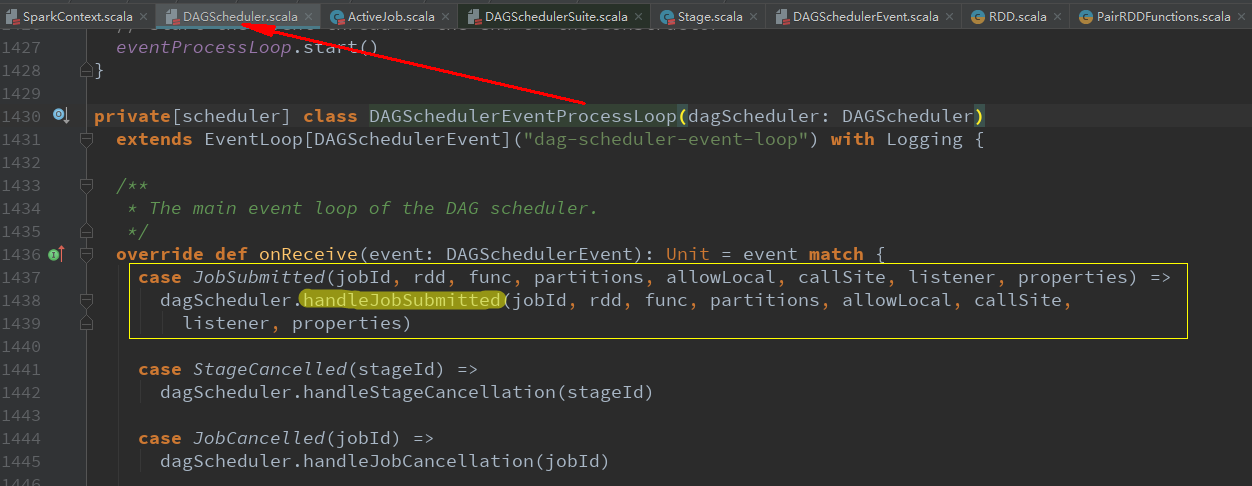
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties)
跳转了这么多,我们终于找到了DAGScheduler的job调度核心入口handleJobSubmitted方法,该方法总共分为五步完成stage的划分和提交。


finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)使用触发job的最后一个rdd创建finalStage
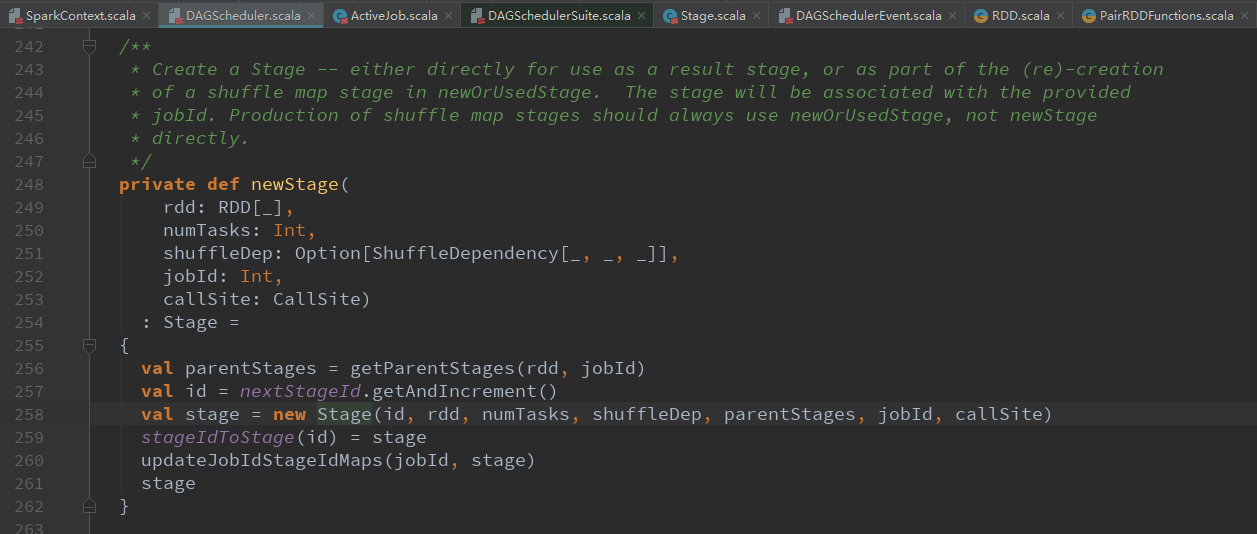
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)用finalStage创建一个job
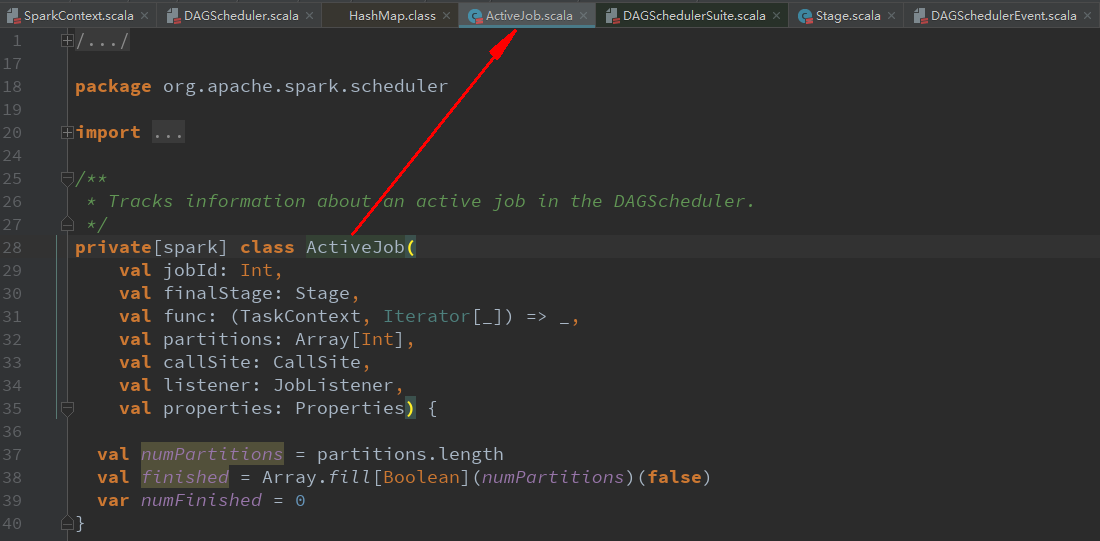
submitStage(finalStage) stage划分算法重点!递归寻找父Stage!
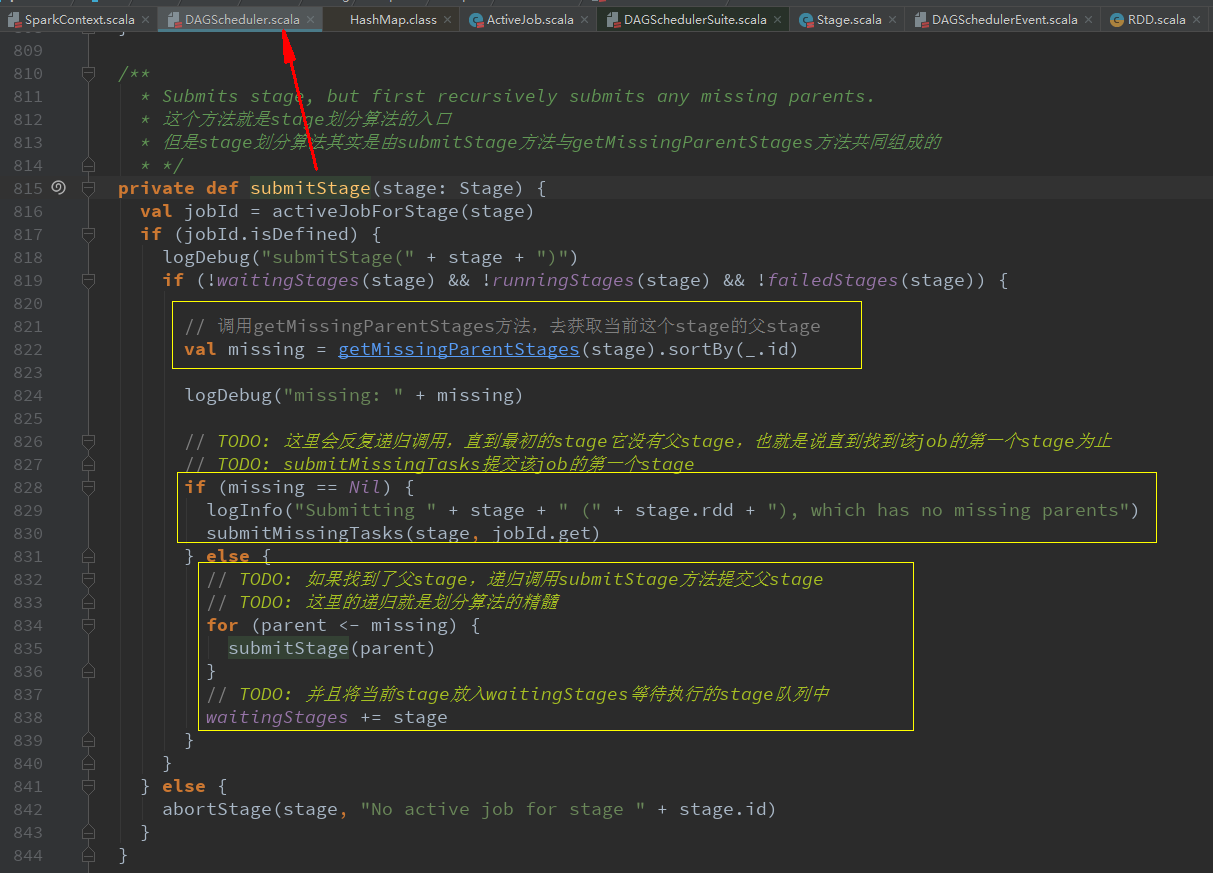
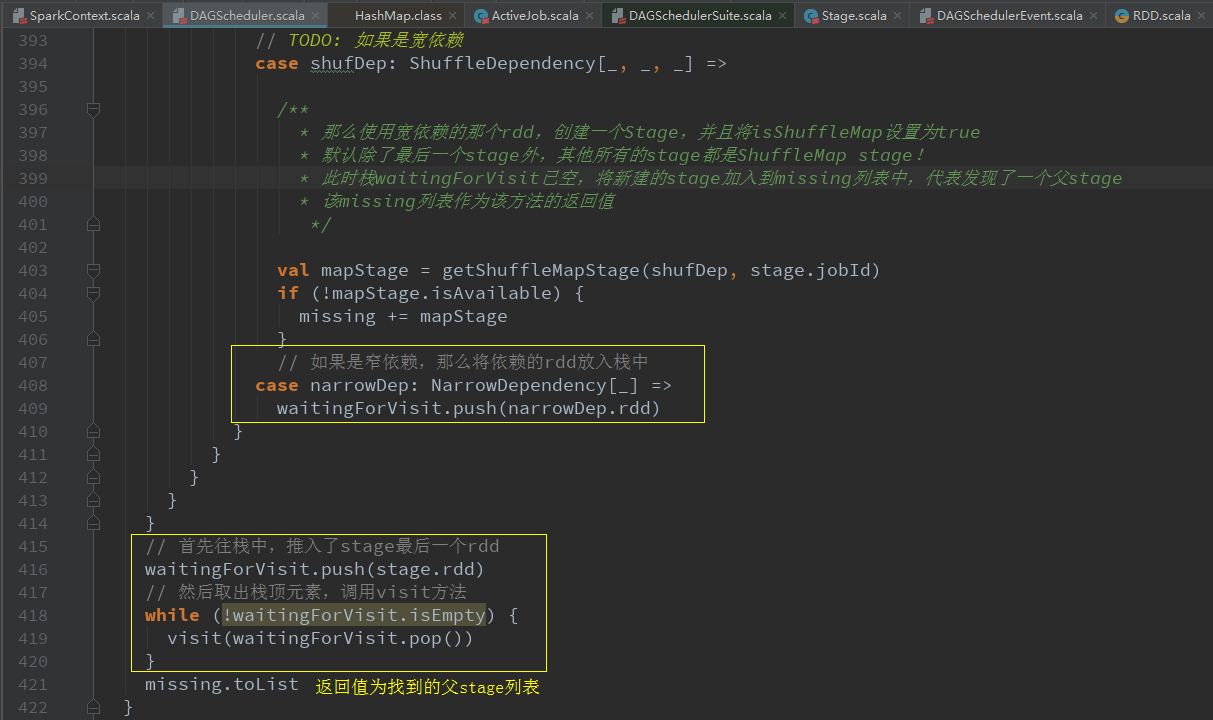
val missing = getMissingParentStages(stage).sortBy(_.id)获取当前stage的父stage

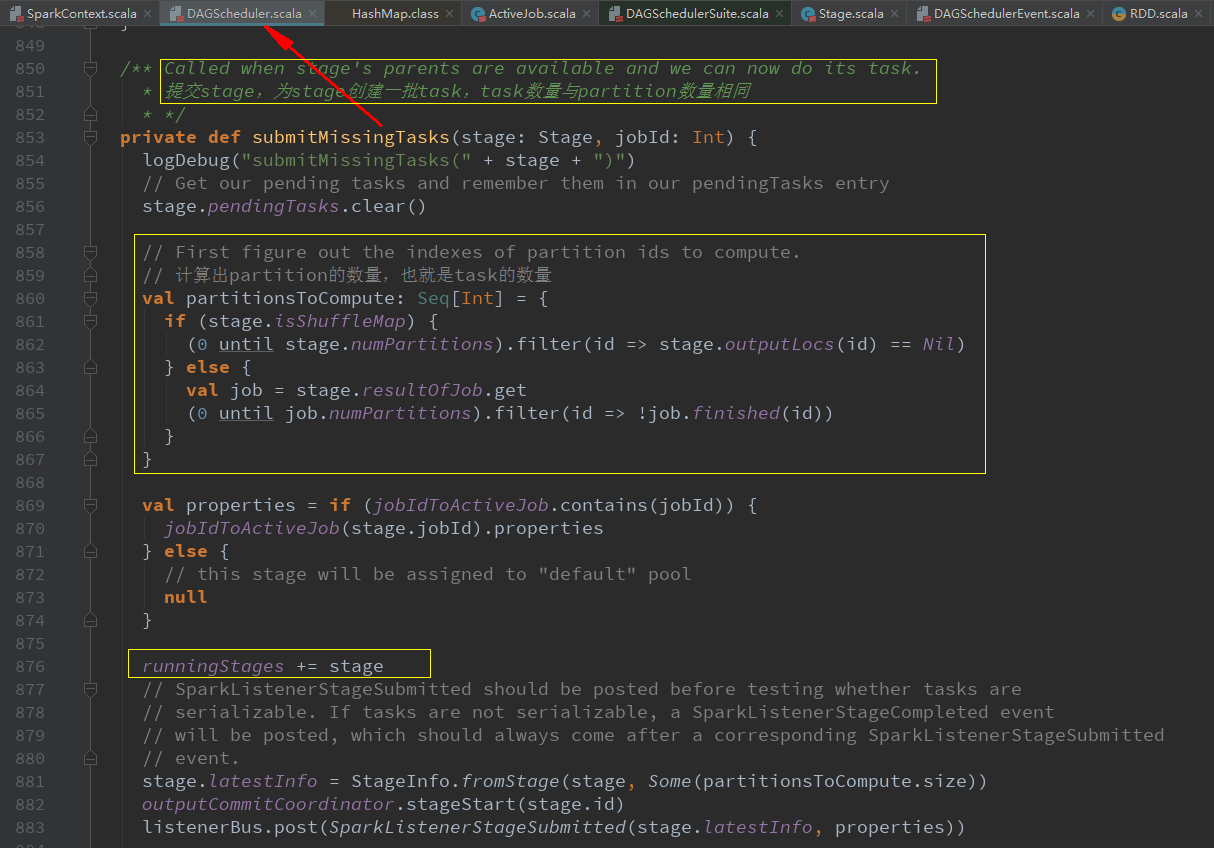
submitMissingTasks(stage, jobId.get)提交某一个stage

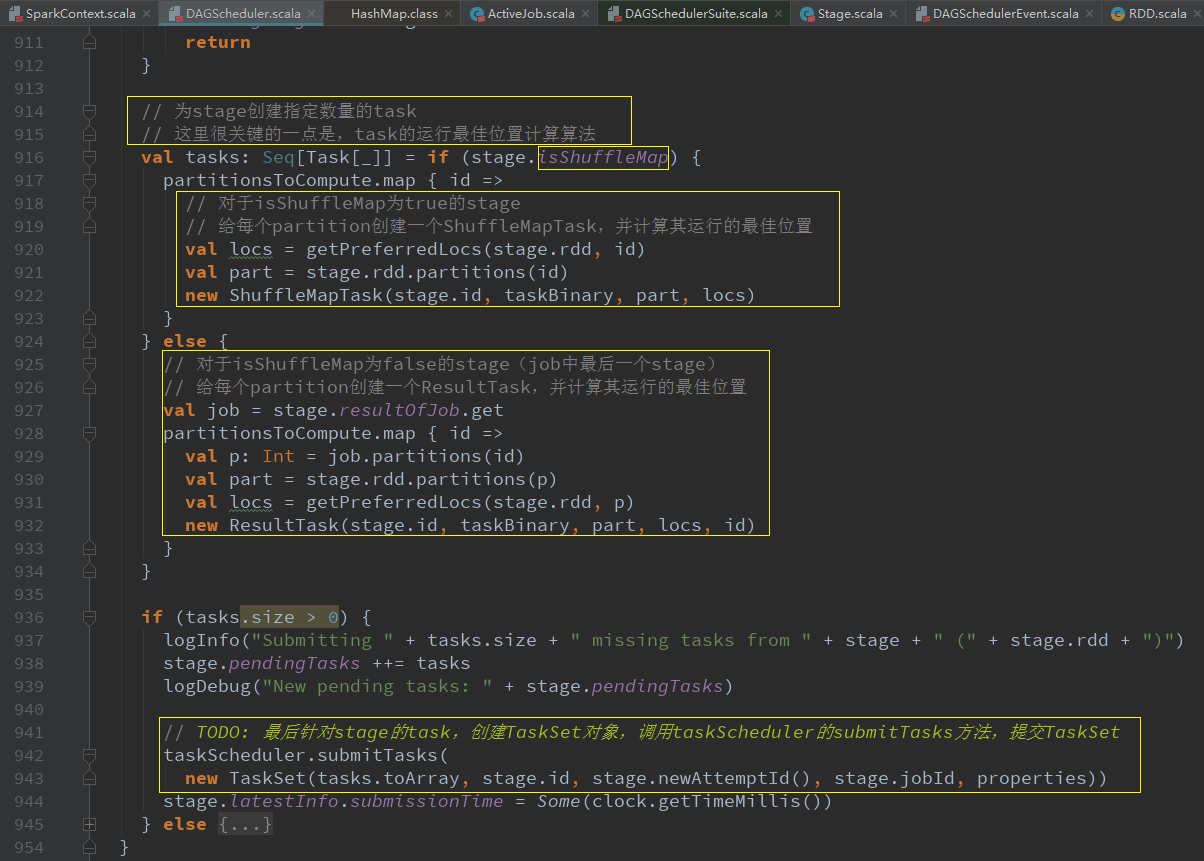
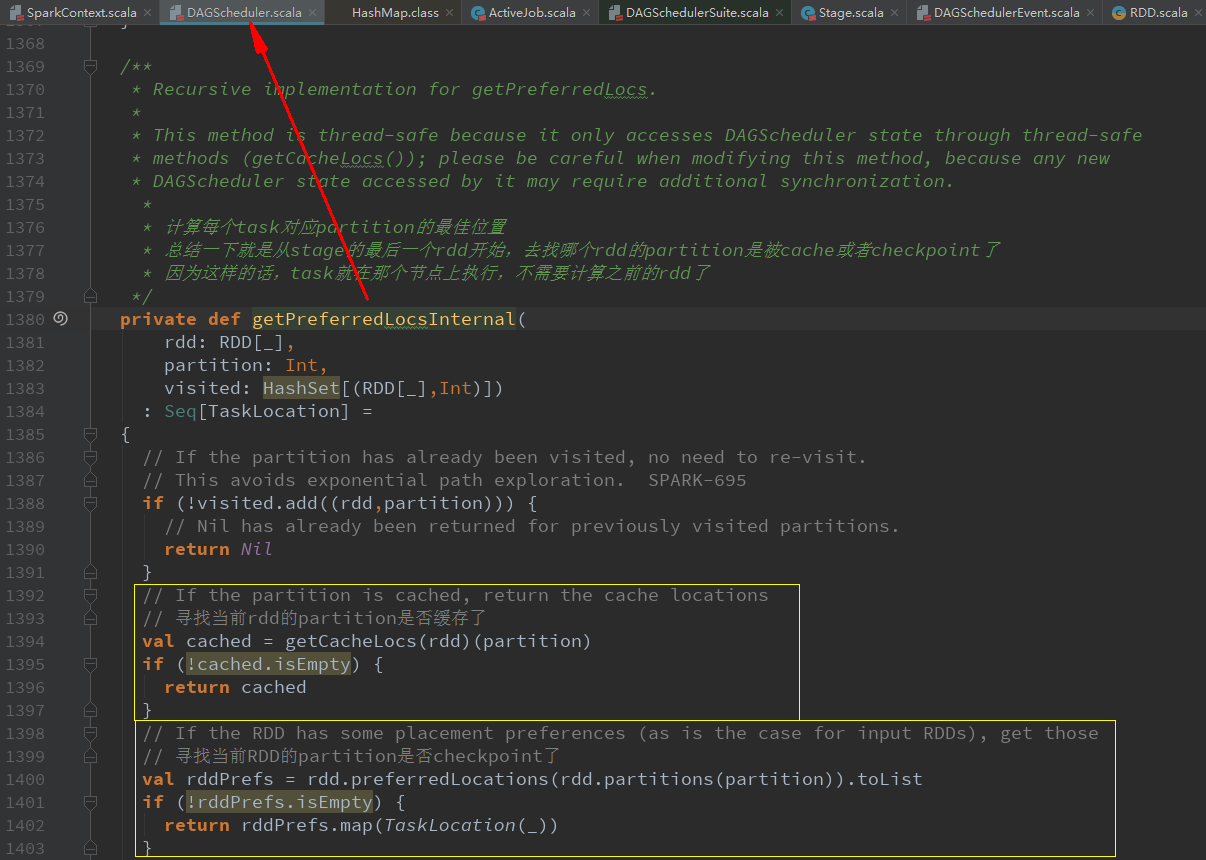
val locs = getPreferredLocs(stage.rdd, id)给每个partition创建一个ShuffleMapTask或ResultTask(最后一个stage),并计算其运行的最佳位置

stage划分算法总结
1. 从finalStage倒推
2. 通过宽依赖,来进行新stage的划分
3. 使用递归,优先提交父stage
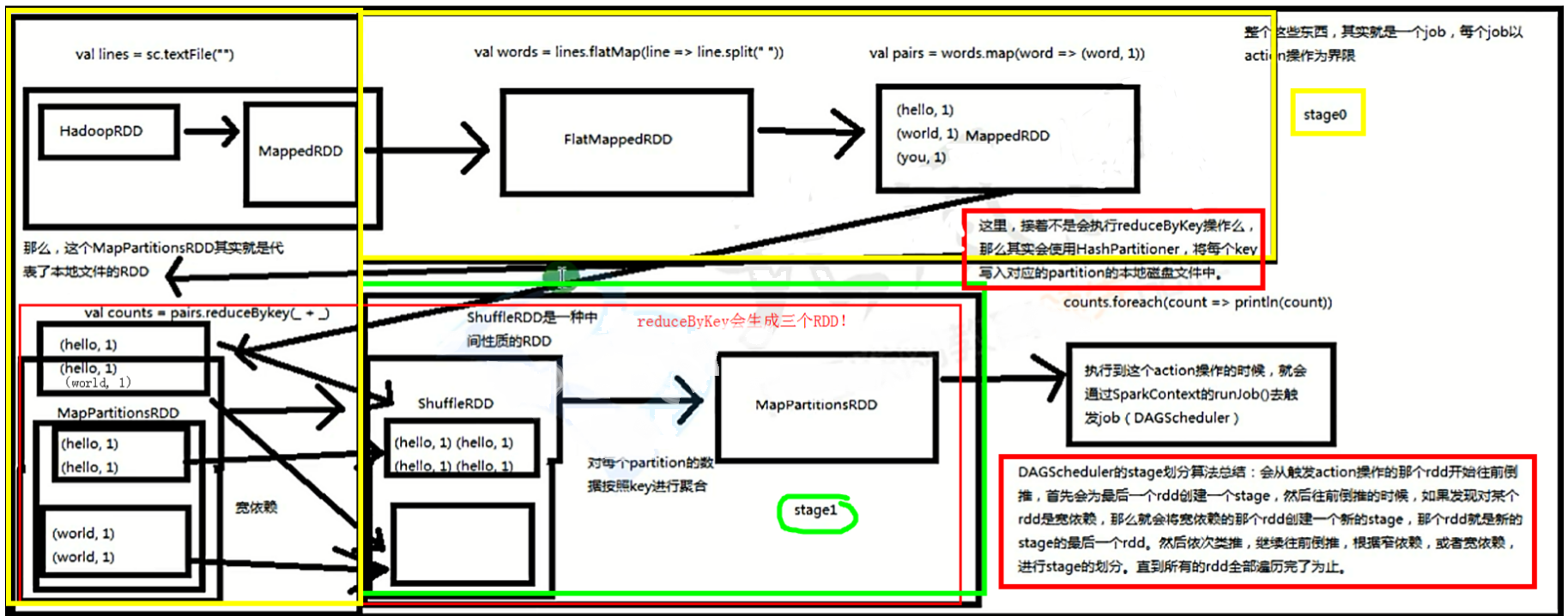
重要知识点
对于每一种有shuffle的操作,例如:groupByKey、reduceByKey、countByKey等,底层都对应了三个RDD:
- MapPartitionsRDD:对应父stage的最后一个RDD
- ShuffleRDD:对应子stage的第一个RDD
- MapPartitionsRDD:对应子stage的第二个RDD
Spark源码剖析(八):stage划分原理与源码剖析的更多相关文章
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- 【Spark工作原理】stage划分原理理解
Job->Stage->Task开发完一个应用以后,把这个应用提交到Spark集群,这个应用叫Application.这个应用里面开发了很多代码,这些代码里面凡是遇到一个action操作, ...
- 用实例说明Spark stage划分原理
注意:此文的stage划分有错,stage的划分是以shuffle操作作为边界的,可以参考<spark大数据处理技术>第四章page rank例子! 参考:http://litaotao. ...
- Spark源码阅读(1): Stage划分
Spark中job由action动作生成,那么stage是如何划分的呢?一般的解答是根据宽窄依赖划分.那么我们深入源码看看吧 一个action 例如count,会在多次runJob中传递,最终会到一个 ...
- 6.Spark streaming技术内幕 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作, ...
- 源码分析八( hashmap工作原理)
首先从一条简单的语句开始,创建了一个hashmap对象: Map<String,String> hashmap = new HashMap<String,String>(); ...
- Spring Boot源码(八):Spring AOP源码
关于spring aop的应用参见:Spring AOP-基于@AspectJ风格 spring在初始化容器时就会生成代理对象: 关于创建bean的源码参见:Spring Boot源码(六):Bean ...
- Spark源码剖析(七):Job触发流程原理与源码剖析
引言 我们知道在application中每存在一个action操作就会触发一个job,那么spark底层是怎样触发job的呢?接下来我们用一个wordcount程序来剖析一下job的触发机制. 解析w ...
- 17、stage划分算法原理及DAGScheduler源码分析
一.stage划分算法原理 1.图解 二.DAGScheduler源码分析 1. ###org.apache.spark/SparkContext.scala // 调用SparkContext,之前 ...
随机推荐
- CCF-201512-3-画图
问题描述 试题编号: 201512-3 试题名称: 画图 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 用 ASCII 字符来画图是一件有趣的事情,并形成了一门被称为 ASC ...
- memcache调整value大小限制
> *事件背景: 当Redis有问题时按预案就会切换到本机memcache,但是我们首页 key:value现 在是1.5M同时memcache item限制是1M,导致首页写入memcache ...
- velocity 是如何实现内省 屏蔽反射的
velocity的标签中支持$abc 这样的语法,如果abc是一个对象,则写模板时就可以利用它来进行反射,调用一些危险的方法,如 $vm.getClass().newInstance() #set ( ...
- bitcms内容管理系统 3.1版源码发布
开源bitcms内容管理系统采用ASP.NET MVC5+MySql的组合开发,更适应中小型系统低成本运行. bitcms的主要功能 1.重写了APS.NET MVC的路由机制.bitcms使用路由参 ...
- 小白的Python之路 day1 Python3的bytes/str之别
原文:The bytes/str dichotomy in Python 3 Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分.文本总是Unicode,由str类型表示,二 ...
- 如何使用 Secret?- 每天5分钟玩转 Docker 容器技术(108)
我们经常要向容器传递敏感信息,最常见的莫过于密码了.比如: docker run -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql 在启动 MySQL 容器时我 ...
- 【微服务】之六:轻松搞定SpringCloud微服务-API网关zuul
通过前面几篇文章的介绍,我们可以轻松搭建起来微服务体系中比较重要的几个基础构建服务.那么,在本篇博文中,我们重点讲解一下,如何将所有微服务的API同意对外暴露,这个就设计API网关的概念. 本系列教程 ...
- Dell poweredge r210进BIOS改动磁盘控制器(SATA Controller)接口模式
Dell poweredge r210进BIOS改动磁盘控制器(SATA Controller)接口模式 开机后按F2键进入BIOS设置,例如以下图: BIOS设置主界面: 使用上下键移动光标到&qu ...
- 第一次面试&第一次霸面
哈哈哈哈,第一次面试和第一次都献给了CVTE! CVTE的招聘流程有点特别:网測-- 一面--笔试--二面--offer 想起网測那天就心酸.那先在做第三部分的专业測试.计时器突然出错........ ...
- Codeforces 149 E. Martian Strings
正反两遍扩展KMP,维护公共长度为L时.出如今最左边和最右边的位置. . .. 然后枚举推断... E. Martian Strings time limit per test 2 seconds m ...