python爬虫——写出最简单的网页爬虫
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一、开发工具
笔者使用的工具是sublimetext3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷。推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你。
sublime text3搭建python开发环境推荐查看此博客:
[sublime搭建python开发环境][http://www.cnblogs.com/codefish/p/4806849.
二、爬虫介绍
爬虫顾名思义,就是像虫子一样,爬在Internet这张大网上。如此,我们便可以获取自己想要的东西。
既然要爬在Internet上,那么我们就需要了解URL,法号“统一资源定位器”,小名“链接”。其结构主要由三部分组成:
(1)协议:如我们在网址中常见的HTTP协议。
(2)域名或者IP地址:域名,如:www.baidu.com,IP地址,即将域名解析后对应的IP。
(3)路径:即目录或者文件等。
三、urllib开发最简单的爬虫
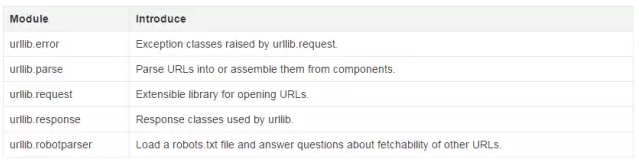
(1)urllib简介
(2)开发最简单的爬虫
百度首页简洁大方,很适合我们爬虫。
爬虫代码如下:

结果如图

我们可以通过在百度首页空白处右击,查看审查元素来和我们的运行结果对比。
当然,request也可以生成一个request对象,这个对象可以用urlopen方法打开。
代码如下:
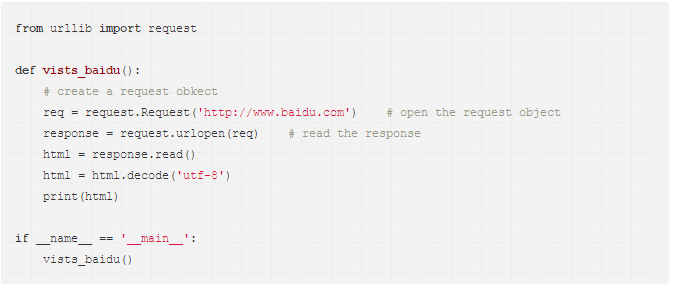
运行结果和刚才相同。
(3)错误处理
错误处理通过urllib模块来处理,主要有URLError和HTTPError错误,其中HTTPError错误是URLError错误的子类,即HTTRPError也可以通过URLError捕获。HTTPError可以通过其code属性来捕获。
处理HTTPError的代码如下:

运行结果如图:
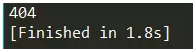
404为打印出的错误代码,关于此详细信息大家可以自行百度。
URLError可以通过其reason属性来捕获。
chuliHTTPError的代码如下:
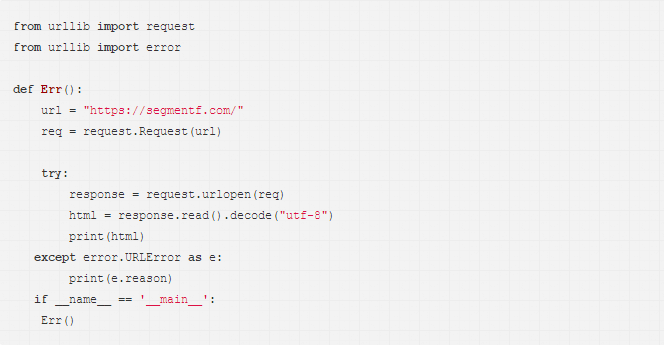
运行结果如图:

既然为了处理错误,那么最好两个错误都写入代码中,毕竟越细致越清晰。须注意的是,HTTPError是URLError的子类,所以一定要将HTTPError放在URLError的前面,否则都会输出URLError的,如将404输出为Not Found。
代码如下:

文章来源:https://segmentfault.com/a/1190000010567472
作者:xiaomi
交流QQ群:238757010
python爬虫——写出最简单的网页爬虫的更多相关文章
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- [置顶]
如何用PYTHON代码写出音乐
如何用PYTHON代码写出音乐 什么是MIDI 博主本人虽然五音不全,而且唱歌还很难听,但是还是非常喜欢听歌的.我一直在做这样的尝试,就是通过人工智能算法实现机器自动的作词和编曲(在这里预告下,通过深 ...
- 如何用PYTHON代码写出音乐
什么是MIDI 博主本人虽然五音不全,而且唱歌还很难听,但是还是非常喜欢听歌的.我一直在做这样的尝试,就是通过人工智能算法实现机器自动的作词和编曲(在这里预告下,通过深度学习写歌词已经实现了,之后会分 ...
- 用sublime写出的第一个网页
STEP1 完成语义分析器 我用的vs2013 c语言写的 这个过程会在下一篇文章中详讲 准备好几个编译好的图,放在一个文件夹里,像下面这样 STEP2 规划好html的框架 上代码! (截图版) ( ...
- python3爬虫.1.简单的网页爬虫
此为记录下我自己的爬虫学习过程. 利用url包抓取网页 import urllib.request #url包 def main(): url = "http://www.douban.co ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- nodeJS实现简单网页爬虫功能
前面的话 本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/h ...
随机推荐
- C#换行 System.Environment.NewLine。
为保持平台的通用性,可以用系统默认换行符 System.Environment.NewLine.
- lodash源码分析之compact中的遍历
小时候, 乡愁是一枚小小的邮票, 我在这头, 母亲在那头. 长大后,乡愁是一张窄窄的船票, 我在这头, 新娘在那头. 后来啊, 乡愁是一方矮矮的坟墓, 我在外头, 母亲在里头. 而现在, 乡愁是一湾浅 ...
- Scala入门系列(十一):模式匹配
引言 模式匹配是Scala中非常有特色,非常强大的一种功能. 类似于Java中的switch case语法,但是模式匹配的功能要比它强大得多,switch只能对值进行匹配,但是Scala的模式匹配除了 ...
- MySql的隔离级别和锁的关系
一.事务的4个基本特征 Atomic(原子性): 事务中包括的操作被看做一个逻辑单元.这个逻辑单元中的操作要 么所有成功.要么所有失败. Consistency(一致性): 仅仅有合法的数据能 ...
- json篇
QQ:1187362408 欢迎技术交流和学习 json篇(json): TODO: 1,json:json是什么( JSON(JavaScript Object Notation) 是一种轻量级的数 ...
- C#调用RESTful API
如今非常多的网络服务都用RESTful API来实现. 比方百度的搜索推广API介绍使用Rest原因:REST+JSON风格的API相比SOAP+XML,优点是:调用更加灵活.也更easy扩展:JSO ...
- Android使用gradle不同配置多项目打包
//build.gradle该配置文件里路径均是相对路径 apply plugin: 'com.android.application' android { def suffix = "su ...
- Git 经常使用命令总结
一 关于加入.删除和回退 1 git rm --cached file 想要git不再跟踪这个文件,可是又不想在硬盘中删除该文件 2 在被git管理的文件夹中删除文件时,能够选择例如以下两种方式: ...
- Android4.0-4.4 加入支持状态栏显示耳机图标方法(支持带不带MIC的两种耳机自己主动识别)
效果如图: 一. 在frameworks/base/packages/SystemUI/res/values/strings.xml 里加入 <string name="headset ...
- Mongodb 3.4 + Centos6.5 配置 + mysql.sql转为csv 或 json导入和导出Mongo (64位系统)
Centos下通过yum安装步骤如下: 声明:相对比那些用源码安装,少了配置和新建log和data目录,这种简单粗暴, ,创建仓库文件, vi /etc/yum.repos.d/mongodb-org ...