Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言
上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令:
hdfs dfs -ls xxx
hdfs dfs -mkdir -p /xxx/xxx
hdfs dfs -cat xxx
hdfs dfs -put local cluster
hdfs dfs -get cluster local
hdfs dfs -cp /xxx/xxx /xxx/xxx
hdfs dfs -chmod -R /xxx
hdfs dfs -chown -R zyh:zyh /xxx
注意:这里要说明一下-cp,我们可以从本地文件拷贝到集群,集群拷贝到本地,集群拷贝到集群。
一、Hadoop客户端配置
其实在前面配置的每一个集群节点都可以做一个Hadoop客户端。但是我们一般都不会拿用来做集群的服务器来做客户端,需要单独的配置一个客户端。
1)安装JDK
2)安装Hadoop
3)客户端配置子core-site.xml

4)客户端配置之mapred-site.xml

5)客户端配置之yarn-site.xml

以上就搭建了一个Hadoop的客户端
二、Java访问HDFS集群
2.1、HDFS的Java访问接口
1)org.apache.hadoop.fs.FileSystem
是一个通用的文件系统API,提供了不同文件系统的统一访问方式。
2)org.apache.hadoop.fs.Path
是Hadoop文件系统中统一的文件或目录描述,类似于java.io.File对本地文件系统的文件或目录描述。
3)org.apache.hadoop.conf.Configuration
读取、解析配置文件(如core-site.xml/hdfs-default.xml/hdfs-site.xml等),或添加配置的工具类
4)org.apache.hadoop.fs.FSDataOutputStream
对Hadoop中数据输出流的统一封装
5)org.apache.hadoop.fs.FSDataInputStream
对Hadoop中数据输入流的统一封装
2.2、Java访问HDFS主要编程步骤
1)构建Configuration对象,读取并解析相关配置文件
Configuration conf=new Configuration();
2)设置相关属性
conf.set("fs.defaultFS","hdfs://1IP:9000");
3)获取特定文件系统实例fs(以HDFS文件系统实例)
FileSystem fs=FileSystem.get(new URI("hdfs://IP:9000"),conf,“hdfs");
4)通过文件系统实例fs进行文件操作(以删除文件实例)
fs.delete(new Path("/user/liuhl/someWords.txt"));
2.3、使用FileSystem API读取数据文件
有两个静态工厂方法来获取FileSystem实例文件系统。

常用的就第二个和第四个
三、实战Java访问HDFS集群
3.1、环境介绍
1)使用的是IDEA+Maven来进行测试
2)Maven的pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.jxlg.zyh.hadoop</groupId>
<artifactId>Hadoop_0010</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.8.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.8.</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>commons-configuration</groupId>
<artifactId>commons-configuration</artifactId>
<version>1.9</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-my-jar-with-dependencies</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.0.</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
pom.xml
3)HDFS集群一个NameNode和两个DataNode
3.2、查询HDFS集群文件系统的一个文件将它文件内容打印出来
package com.jslg.zyh.hadoop.hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI; public class CatDemo_0010 {
public static void main(String[] args) throws IOException {
// 创建Configuration对象
Configuration conf=new Configuration();
// 创建FileSystem对象
FileSystem fs=
FileSystem.get(URI.create(args[]),conf);
// 需求:查看/user/kevin/passwd的内容
// args[0] hdfs://1.0.0.5:9000/user/zyh/passwd
// args[0] file:///etc/passwd
FSDataInputStream is=
fs.open(new Path(args[]));
byte[] buff=new byte[];
int length=;
while((length=is.read(buff))!=-){
System.out.println(
new String(buff,,length));
}
System.out.println(
fs.getClass().getName());
}
}
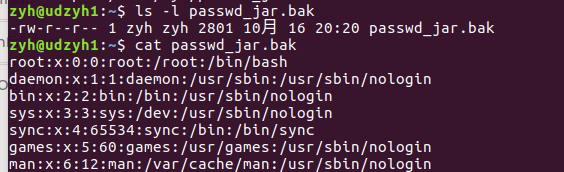
1)需要在HDFS文件系统中有passwd.txt文件,如果没有需要自己创建
hdfs dfs -mkdir -p /user/zyh
hdfs dfs -put /etc/passwd /user/zyh/passwd.txt
2)将Maven打好的jar包发送到服务器中,这里我们就在NameNode主机中执行,每一个节点都是一个客户端。
注意:
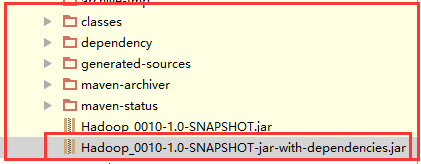 这里要发送第二个包,因为它把相关类也打进jar中
这里要发送第二个包,因为它把相关类也打进jar中
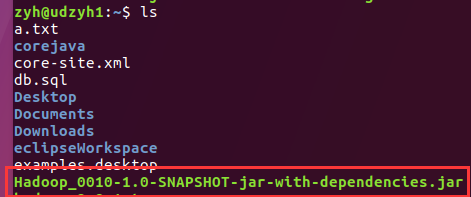 查看服务器已经收到jar包
查看服务器已经收到jar包
3)执行jar包查看结果
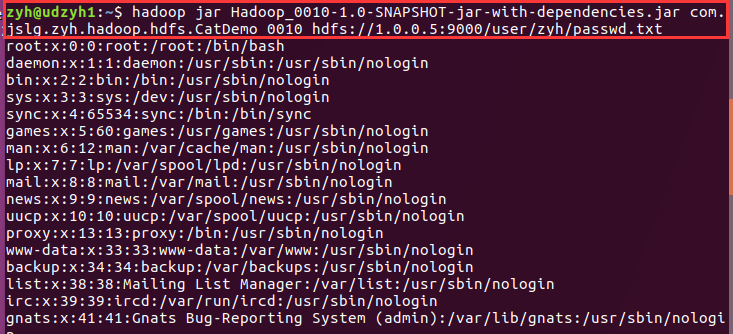
我们可以看到查询出来了passwd.txt中的内容
注意:在最后我们还查看了一下FileSystem类,因为我们知道FileSystem是抽象类,它是根据后面的URI来确定到底调用的是哪一个子类的。

3.3、我们在IEDA中执行来获取文件系统的内容并打印在控制台和相应的本地文件中
1)主要代码
public static void main(String[] args) throws IOException {
//创建configuration对象
Configuration conf = new Configuration();
//创建FileSystem对象
//需求:查看hdfs集群服务器/user/zyh/passwd.txt的内容
FileSystem fs = FileSystem.get(URI.create("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"), conf);
// args[0] hdfs://1.0.0.3:9000/user/zyh/passwd.txt
// args[0] file:///etc/passwd.txt
FSDataInputStream is = fs.open(new Path("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"));
OutputStream os=new FileOutputStream(new File("D:/a.txt"));
byte[] buff= new byte[];
int length = ;
while ((length=is.read(buff))!=-){
System.out.println(new String(buff,,length));
os.write(buff,,length);
os.flush();
}
System.out.println(fs.getClass().getName());
//这个是根据你传的变量来决定这个对象的实现类是哪个
}
2)Maven重新编译,并执行
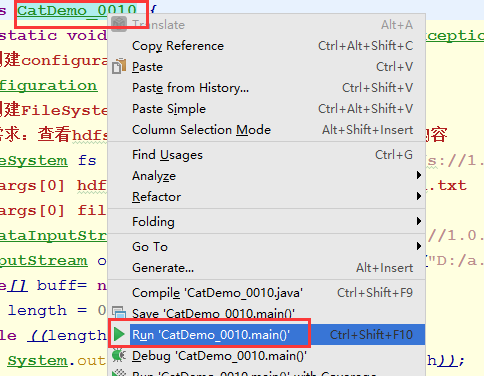
3)结果
在控制台中:
在本地文件中:

3.4、获取HDFS集群文件系统中的文件到本地文件系统
1)主要代码
public class GetDemo_0010 {
public static void main(String[] args) throws IOException {
Configuration conf=
new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create(args[]),conf);
FSDataInputStream is=
inFs.open(new Path(args[]));
// 获取本地文件系统对象
//当然这个你也可以用FileOutputStream
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(args[]));
byte[] buff=new byte[];
int length=;
while((length=is.read(buff))!=-){
os.write(buff,,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
}
}
2)结果

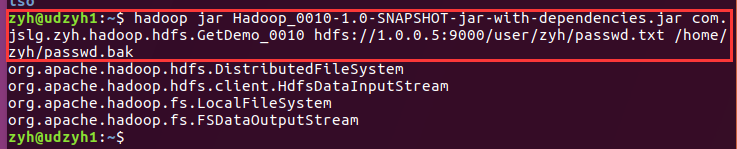
我们可以看到对于HDFS集群中获取的FileSystem对象是分布式文件系统,而输入流是HdfsDataInputStream主要用来做数据的传输。
对于本地来说获取到的FileSystem对象时本地文件系统,而输出流就是FSDataOutputStream。
将HDFS中的文件拿到windows中:
//创建configuration对象
Configuration conf = new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create("file://1.0.0.5:9000/user/kevin/passwd"),conf);
FSDataInputStream is=
inFs.open(new Path("hdfs://1.0.0.5:9000/user/kevin/passwd"));
// 获取本地文件系统对象
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path("C:\\passwd"));
byte[] buff=new byte[];
int length=;
while((length=is.read(buff))!=-){
os.write(buff,,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
3.5、通过设置命令行参数变量来编程
这里需要借助Hadoop中的一个类Configured、一个接口Tool、ToolRunner(主要用来运行Tool的子类也就是run方法)
分析:
1)我们查看API可以看到ToolRunner中有一个run方法:

里面需要一个Tool的实现类和使用args用来传递参数的String类型的数据
2)分析Configured
这是Configurable接口中有一个getConf()方法
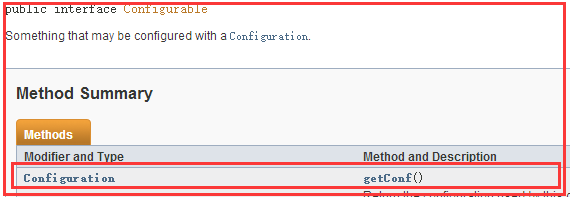
而在Configured类中实现了Configurable接口

所以Configured类中实现了Configurable接口的getConf()方法,使用它来获得一个Configuration对象
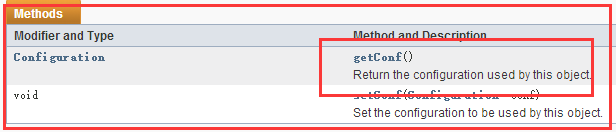
3)细说Configuration对象
可以获取Hadoop的所有配置文件中的数据
还可以通过使用命令行中使用-D(-D是一个标识)使用的变量以及值
1)主要代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class GetDemo_0011
extends Configured
implements Tool{
@Override
public int run(String[] strings) throws Exception{
//我们所有的代码都写在这个run方法中
Configuration conf=
getConf();
String input=conf.get("input");
String output=conf.get("output");
FileSystem inFs=
FileSystem.get(
URI.create(input),conf);
FSDataInputStream is=
inFs.open(new Path(input));
FileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(output));
IOUtils.copyBytes(is,os,conf,true);
return ;
} public static void main(String[] args) throws Exception{
//ToolRunner中的run方法中需要一个Tool的实现类,和
System.exit(
ToolRunner.run(
new GetDemo_0011(),args));
}
}
分析:
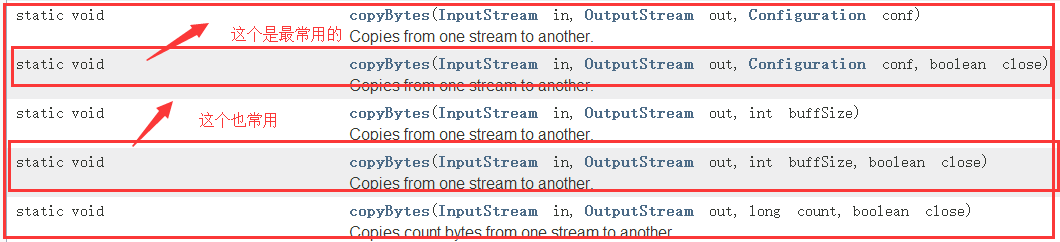
1)介绍IOUtils
它是Hadoop的一个IO流的工具类,查看API中可知!
2)打包jar发送给服务器执行

3)查看结果
3.6、从HDFS集群中下载文件到本地
1)普通版
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class P00032_HdfsDemo_PutFile_0010 extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Configuration configuration
=getConf();
String input=
configuration.get("input");
String output=
configuration.get("output");
LocalFileSystem inFs=
FileSystem.getLocal(
configuration);
FileSystem outFs=
FileSystem.get(
URI.create(output),
configuration);
FSDataInputStream is=
inFs.open(new Path(input));
FSDataOutputStream os=
outFs.create(new Path(output));
IOUtils.copyBytes(is,os,,true);
System.out.println(os.getClass().getName());
inFs.close();
outFs.close();
return ;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00032_HdfsDemo_PutFile_0010(),args));
}
}
P00032_HdfsDemo_PutFile_0010
2)可以观察到写入了多少
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class P00031_HdfsDemo_PutFile_0010 extends Configured implements Tool{
FSDataOutputStream os=null;
@Override
public int run(String[] strings) throws Exception{
Configuration configuration=getConf();
String input=configuration.get("input");
String output=configuration.get("output");
LocalFileSystem inFs=FileSystem.getLocal(configuration);
FileSystem outFs=FileSystem.get(URI.create(output),configuration);
FSDataInputStream is=inFs.open(new Path(input));
os=outFs.create(new Path(output),()->{
try{
System.out.println("已经写入了"+os.getPos()+"bytes");
}catch(IOException e){
e.printStackTrace();
}
});
IOUtils.copyBytes(is,os,,true);
System.out.println(os.getClass().getName());
inFs.close();
outFs.close();
return ;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00031_HdfsDemo_PutFile_0010(),args));
}
}
P00031_HdfsDemo_PutFile_001
喜欢就“推荐”哦!
Hadoop(五)搭建Hadoop与Java访问HDFS集群的更多相关文章
- Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content) 一.Hadoop客户端配置 二.Java访问HDFS集群 2.1.HDFS的Java访问接口 2.2.Java访问HDFS主要编程步骤 2.3.使用FileSystem A ...
- 大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述 NameNode 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中 这个集群有哪些DataNode ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- Hadoop学习笔记1 - 使用Java API访问远程hdfs集群
转载请标注原链接 http://www.cnblogs.com/xczyd/p/8570437.html 2018年3月从新司重新起航了.之前在某司过了的蛋疼三个月,也算给自己放了个小假了. 第一个小 ...
- 马士兵hadoop第三课:java开发hdfs
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第三课:java开发hdfs(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
随机推荐
- 团队作业9——测试与发布(Beta版本)
Beta版本测试报告 一bug汇总 计时没有显示即倒计时,难度不同的功能没有实现(已修复) 没有导入试卷和错题功能(不打算修复) 前台管理功能(部分修复) 界面美观问题(没有修复也不打算修复) 二.场 ...
- 201521123066《Java程序设计》第八周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 2. 书面作业 本次作业题集集合 1.List中指定元素的删除(题目4-1) 1.1 实验总结** 用cont ...
- 201521123087 《java程序设计》 第七周学习总结
1. 本周学习总结 2. 书面作业 ArrayList代码分析1.1 解释ArrayList的contains源代码 ...
- 201521123067 《Java程序设计》第4周学习总结
201521123067 <Java程序设计>第4周学习总结 1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. ●总结: (1)在 ...
- 201521123004《Java程序设计》第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 本周主要内容为: 继承:extends 抽取共同特征(行为与属性) 复用代码 继承时子类将获 ...
- 201521123037 《Java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu ...
- 如何定制 Calico 网络 Policy - 每天5分钟玩转 Docker 容器技术(70)
Calico 默认的 policy 规则是:容器只能与同一个 calico 网络中的容器通信.本节讨论如何定制 policy. calico 能够让用户定义灵活的 policy 规则,精细化控制进出容 ...
- Activiti-06-.事件
Events 事件 1, 事件用于对发生在流程生命周期的事情进行建模.事件总是被形象成一个圆圈.在BPMN 2.0 中,存在两种主要的事件类型:捕获事件和抛出事件. 捕获:流程执行到该事件时,会等待 ...
- net core 安装web模板
---恢复内容开始--- 今天想试试在Linux用C#开发WebAPI,查了下,要用: dotnet new -t Web 来建立工程,结果我试了下,出来这段: Invalid input switc ...
- junit initializationError和找不到或无法加载主类
今天在做Junit测试的时候 出现了initialzationError , 在网上查找,一般都是因为Jar 包冲突或者缺少Jar包导致的, 但是我的其他方法是可以使用Junit 的, 所以感觉应该跟 ...