Python-Unittest多线程执行用例
前言
|
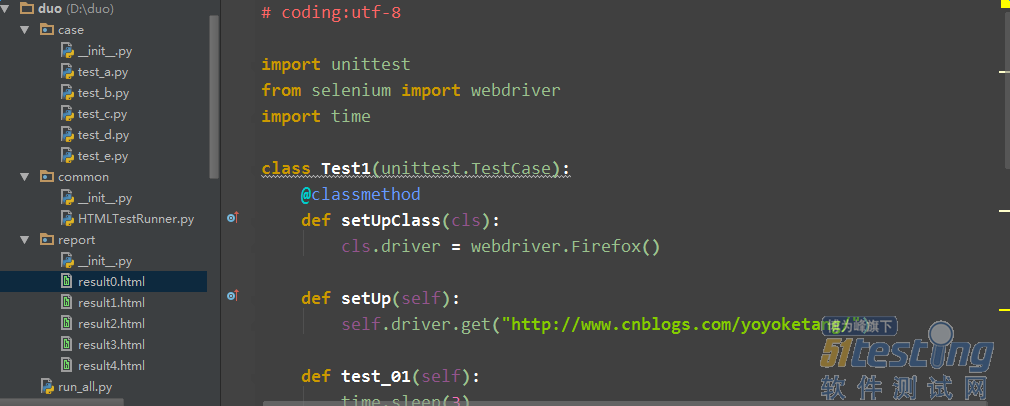
# coding:utf-8
import unittest
from selenium import webdriver
import time
class Test1(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
def setUp(self):
self.driver.get("http://www.cnblogs.com/yoyoketang/")
def test_01(self):
time.sleep(3)
t = self.driver.title
print t
# 随便写的用例,没写断言
def test_02(self):
time.sleep(3)
t = self.driver.title
print t
h = self.driver.window_handles
print h
# 随便写的用例,没写断言
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == "__main__":
unittest.main()
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#设置路径:Defualt Settings---Editor--File and Code Templates import unittest
import HTMLTestRunnerNew
import os
from tomorrow import threads # 获取路径# 当前脚本所在目录
curpath = os.path.dirname(os.path.realpath(__file__))
#测试用例路径
casepath = os.path.join(curpath, "case")
#测试报告路径
reportpath = os.path.join(curpath, "report") def add_case(case_path=casepath, rule="test*.py"): '''加载所有的测试用例''' discover = unittest.defaultTestLoader.discover(case_path, pattern=rule,top_level_dir=None)
return discover @threads(5)
def run_case(all_case, report_path=reportpath, nth=0): '''执行所有的用例, 并把结果写入测试报告''' report_abspath = os.path.join(report_path, "result%s.html"%nth) with open(report_abspath, "wb+") as file: runner = HTMLTestRunnerNew.HTMLTestRunner(stream=file, title=u'自动化测试报告,测试结果如下:',description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case) if __name__ == "__main__": # 用例集合
cases = add_case()
# 之前是批量执行,这里改成for循环执行
for i, j in zip(cases, range(len(list(cases)))):
run_case(i, nth=j) # 执行用例,生成报告
# print(i,j)
|
|
Python-Unittest多线程执行用例的更多相关文章
- unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- python--selenium多线程执行用例实例/执行多个用例
python--selenium多线程执行用例实例/执行多个用例 我们在做selenium测试的时候呢,经常会碰到一些需要执行多个用例的情况,也就是多线 程执行py程序,我们前面讲过单个的py用例怎么 ...
- Pycharm上python unittest不执行"if __name__ == '__main__' "问题or选择非unittest run
转:http://www.cnblogs.com/csjd/p/6366535.html python unittest不执行"if __name__ == '__main__' " ...
- unittest(执行用例)
from selenium import webdriver from time import sleep import unittest#导入unittest库 import HTMLTestRun ...
- python自动化-unittest批量执行用例(discover)
前言 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了. 加载用例后,用unittest里面的Text ...
- selenium+python自动化90-unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- python学习笔记(28)-unittest单元测试-执行用例
执行用例 #写一个测试类 import unittest import HTMLTestRunnerNew #写好的模块可以直接调用 #import HTMLTest #测试报告模板 from cla ...
- selenium+python-unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时...那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线程 ...
- 第二种方式,修改python unittest的执行顺序,使用猴子补丁
1.按照测试用例的上下顺序,而不是按方法的名称的字母顺序来执行测试用例. 之前的文章链接 python修改python unittest的运行顺序 之前写的,不是猴子补丁,而是要把Test用例的类名传 ...
随机推荐
- [RabbitMQ]Java客户端:源码概览
本文简要介绍RabbitMQ提供的Java客户端中最基本的功能性接口/类及相关源码. Mavan依赖: <dependency> <groupId>com.rabbitmq&l ...
- xLua自定义加载器
xLua入门基础 环境配置 github下载xLua文件: xLua是腾讯开发,据说比较先进: 下载下来后将Plugins和XLua文件夹考进项目: Plugins多平台权限:XLua和C#交互: t ...
- 视频需求超平常数 10 倍,却节省了 60% 的 IT 成本投入是一种什么样的体验?
作者 | 山猎 近年来,Serverless 一直在高速发展,并呈现出越来越大的影响力.主流的云服务商也在不断地丰富云产品体系,提供更好的开发工具,更高效的应用交付流水线,更好的可观测性,更细腻的产品 ...
- linux版火狐浏览器部署详解
Firefox下载地址 Firefox全历史版本下载: http://ftp.mozilla.org/pub/firefox/releases/ Firefox驱动问题下载 https://gith ...
- Selenium获取动态图片验证码
Selenium获取动态图片验证码 关于图片验证码的文章,我想大家都有一定的了解了. 在我们做UI自动化的时候,经常会遇到图片验证码的问题. 当开发不给咱们提供万能验证码,或者测试第三方网站比如知乎的 ...
- 深入理解Java虚拟机之类加载机制篇
概述 虚拟机把描述类的数据从 Class 文件加载到内存中,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,就是虚拟机的类加载机制. 在Java语言里面,类型的 ...
- 80. 删除有序数组中的重复项 II
题目 给你一个有序数组 nums ,请你原地删除重复出现的元素(不需要考虑数组中超出新长度后面的元素),使每个元素最多出现两次 ,返回删除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入 ...
- airtest keyevent 按键速查表
- Linux服务器装Anaconda&TensorFlow
远程Linux服务器装Anaconda&指定版本TensorFlow 说明: 由于疫情影响,原先使用的服务器已断电,故重选了一台服务器对环境重选进行搭建,正好补上这篇博文. 01 下载Anac ...
- [no code][scrum meeting] Alpha 6
项目 内容 会议时间 2020-04-13 会议主题 后端技术细节分析 会议时长 30min 参会人员 PM+后端组成员 $( "#cnblogs_post_body" ).cat ...