在 Prim 算法中使用 pb_ds 堆优化
在 Prim 算法中使用 pb_ds 堆优化
Prim 算法用于求最小生成树(Minimum Spanning Tree,简称 MST),其本质是一种贪心的加点法。对于一个各点相互连通的无向图而言,Prim 算法的具体步骤如下:
令 \(G=(V,E)\) 表示原图,\(G'=(V',E')\) 表示 \(G\) 的最小生成树,\(dis_u\) 表示节点 \(u\) 到任意 \(v \in V'\) 的最小距离(初始化为 \(+\infty\))。
- 任取节点\(s \in V\),令 \(dis_s=0\);
- 找到一个节点 \(u \in \complement_V V'\),使得 \(dis_u\) 最小;
- 将 \(u\) 加入 \(V'\),\(dis_u\) 所代表的边加入 \(E'\);
- 对于任意边 \((u,v)\in \complement_E E'\),令 \(dis_v=\min \{dis_v,w\}\),其中 \(w\) 为边 \((u,v)\) 的权值;
- 重复过程 2 到 过程 4,直到 \(V'=V\)。
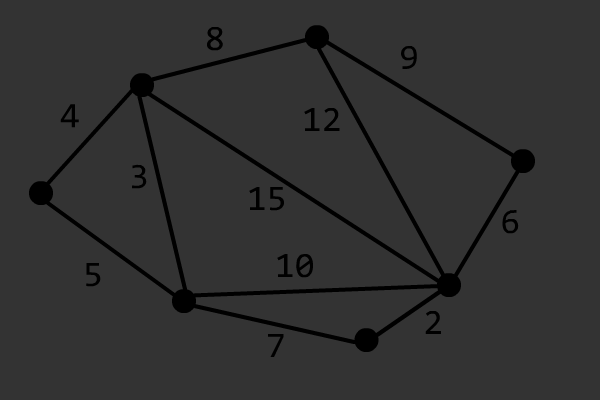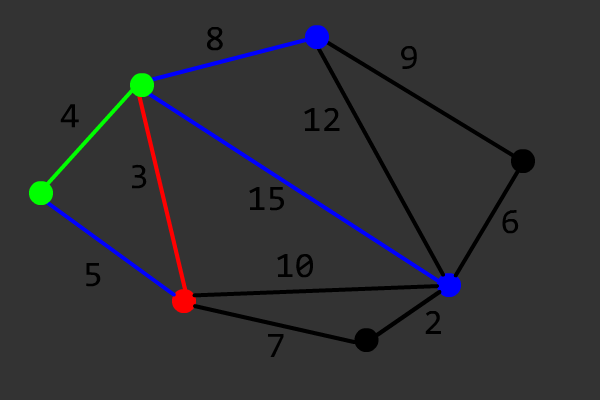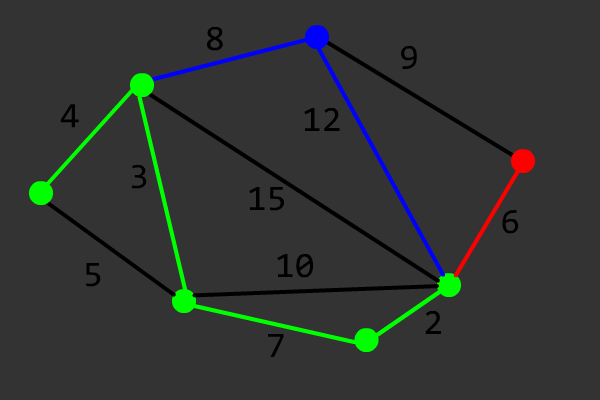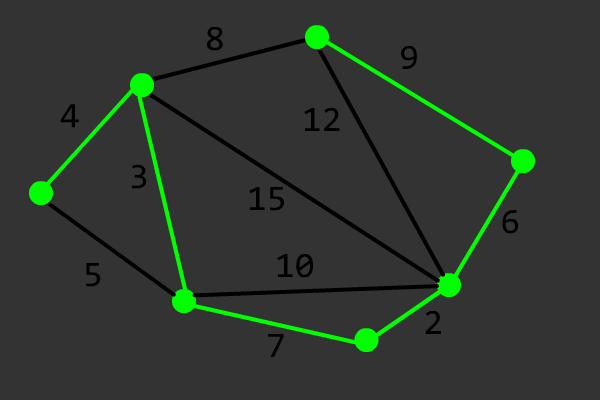
该算法的正确性证明可以参考 OI Wiki。
朴素的 Prim 算法时间复杂度为 \(O(n^2+m)\),其中大部分时间都消耗在操作 2 上,可以考虑利用堆对其进行优化。用二叉堆等不支持 \(O(1)\) decrease-key 操作的堆优化后时间复杂度为 \(O((n+m)\log n)\),用 Fibonacci 堆优化后的时间复杂度为 \(O(n \log n+m)\)(参考 OI Wiki)。相较于 Kruskal 算法,Prim 算法在稠密图上的效率更高。
Prim 算法中大量使用到 decrease-key 操作。在 OI 竞赛中,为节约时间,可以使用 C++ 标准库中封装好的数据结构代替手写堆。由于 std::priority_queue 不支持 decrease-key 操作,常常用 std::map 代替。实际上,std::set 内部实现是一棵常数较大的红黑树,这种用法显然会影响运行效率。鉴于当前 OI 竞赛中几乎全部采用 GNU 编译器,且 CCF 已经明确允许使用 pb_ds,我们可以使用 __gnu_pbds::priority_queue 作为堆来优化 Prim 算法,可以选择不同种类的堆作为内部实现,其中最快也是默认的是 配对堆(Pairing Heap)。具体使用方式见代码模板:
#include <bits/extc++.h>
using namespace std;
const int maxn = 5005;
const int inf = 0x3f3f3f3f;
int n, m;
vector<pair<int, int>> g[maxn];
__gnu_pbds::priority_queue<pair<int, int>, greater<>> heap;
__gnu_pbds::priority_queue<pair<int, int>, greater<>>::point_iterator p[maxn]; // dis[i] and iterator for decrease-key
int prim() {
int ans = 0;
p[1] = heap.push(make_pair(0, 1));
for (int i = 2; i <= n; ++i)
p[i] = heap.push(make_pair(inf, i));
while (!heap.empty()) {
if (heap.top().first == inf)
return -1;
int u = heap.top().second;
ans += heap.top().first;
heap.pop();
p[u] = heap.end();
for (auto& i : g[u])
if (p[i.first] != heap.end() && i.second < p[i.first]->first)
heap.modify(p[i.first], make_pair(i.second, i.first));
}
return ans;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 1; i <= m; ++i) {
int u, v, w;
cin >> u >> v >> w;
g[u].emplace_back(v, w);
g[v].emplace_back(u, w);
}
int ans = prim();
if (ans != -1)
cout << ans << endl;
else
cout << "orz" << endl;
return 0;
}
转载请注明出处。原文地址:https://www.cnblogs.com/na-sr/p/clang-format.html
在 Prim 算法中使用 pb_ds 堆优化的更多相关文章
- 一步一步写算法(之prim算法 中)
原文:一步一步写算法(之prim算法 中) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] C)编写最小生成树,涉及创建.挑选和添加过程 MI ...
- Dijkstra算法的二叉堆优化
Dijkstra算法的二叉堆优化 算法原理 每次扩展一个距离最小的点,再更新与其相邻的点的距离. 如何寻找距离最小的点 普通的Dijkstra算法的思路是直接For i: 1 to n 优化方案是建一 ...
- 最短路径——Dijkstra算法以及二叉堆优化(含证明)
一般最短路径算法习惯性的分为两种:单源最短路径算法和全顶点之间最短路径.前者是计算出从一个点出发,到达所有其余可到达顶点的距离.后者是计算出图中所有点之间的路径距离. 单源最短路径 Dijkstra算 ...
- 图论——最小生成树:Prim算法及优化、Kruskal算法,及时间复杂度比较
最小生成树: 一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边.简单来说就是有且仅有n个点n-1条边的连通图. 而最小生成树就是最小权 ...
- 求最小生成树(暴力法,prim,prim的堆优化,kruskal)
求最小生成树(暴力法,prim,prim的堆优化,kruskal) 5 71 2 22 5 21 3 41 4 73 4 12 3 13 5 6 我们采用的是dfs的回溯暴力,所以对于如下图,只能搜索 ...
- Dijkstra算法堆优化详解
DIJ算法的堆优化 DIJ算法的时间复杂度是\(O(n^2)\)的,在一些题目中,这个复杂度显然不满足要求.所以我们需要继续探讨DIJ算法的优化方式. 堆优化的原理 堆优化,顾名思义,就是用堆进行优化 ...
- 算法8-5:Prim算法
Prim算法用于计算最小生成树.Prim算法分为两种,一种是懒汉式,一种是饿汉式. 懒汉式Prim 懒汉式Prim算法过程例如以下: 首先将顶点0增加到MST中 从MST与未訪问顶点之间边中选出最短的 ...
- Dijkstra和Prim算法的区别
Dijkstra和Prim算法的区别 1.先说说prim算法的思想: 众所周知,prim算法是一个最小生成树算法,它运用的是贪心原理(在这里不再证明),设置两个点集合,一个集合为要求的生成树的点集合A ...
- 算法导论--最小生成树(Kruskal和Prim算法)
转载出处:勿在浮沙筑高台http://blog.csdn.net/luoshixian099/article/details/51908175 关于图的几个概念定义: 连通图:在无向图中,若任意两个顶 ...
随机推荐
- Ubuntu Server服务器上架设Git Server服务器
1.设置公钥 ubuntu:/home/git$ ssh-keygen -t rsa #生成密钥 这里会提示输入密码,我们不输入直接回车即可. 然后用刚生成公钥/home/git/.ssh/id_rs ...
- Android JNI 启动线程,并设置线程名称
p.p1 { margin: 0; font: 12px Menlo; color: rgba(100, 56, 32, 1); background-color: rgba(255, 255, 25 ...
- 深度学习中常见的 Normlization 及权重初始化相关知识(原理及公式推导)
Batch Normlization(BN) 为什么要进行 BN 防止深度神经网络,每一层得参数更新会导致上层的输入数据发生变化,通过层层叠加,高层的输入分布变化会十分剧烈,这就使得高层需要不断去重新 ...
- Centos/Docker/Nginx/Node/Jenkins 操作
Centos Centos 是一个基于 Linux 的开源免费操作系统 # 本地拷贝文件到远程服务器scp output.txt root@47.93.242.155:/data/ output.tx ...
- C++中常用的数学函数总结
我们在C++程序设计的过程中往往会使用到一些数学函数,那么不同的数学运算要用到什么函数哪?大家可以参考我的总结如下: 首先引用到数学函数时一定要记得加函数头文件 #include<cmath&g ...
- 源码解析C#中PriorityQueue(优先级队列)的实现
前言 前段时间看到有大佬对.net 6.0新出的PriorityQueue(优先级队列)数据结构做了解析,但是没有源码分析,所以本着探究源码的心态,看了看并分享出来.它不像普通队列先进先出(FIFO) ...
- InfoGAN
目录 概 主要内容 Chen X., Duan Y., Houthooft R., Schulman J., Sutskever I., Abbeel P. InfoGAN: Interpretabl ...
- ACE_Get_Opt函数笔记
#include "ace/OS_NS_string.h" #include "ace/Configuration.h" #include "ace/ ...
- docker启动emqx官方镜像,顺便启动exporter
注意,我是把把官方镜像放到了自己的仓库 1.emqx官方镜像启动 docker run -d --name emqx31 -p 1883:1883 -p 8083:8083 -p 8883:8883 ...
- pytest执行用例:明明只写了5个测试用例, 怎么收集到33个!?
pytest收集测试用例的顺序: 同一个项目中搜索所有以test_开头的测试文件.test_开头的测试类.test_开头的测试函数 执行测试用例的顺序: 是按照先数据(0~9)>再字母(a~z) ...