HBase优化相关
1.HBase预分区
HBase在创建表时,默认会自动创建一个Region分区。在导入数据时,所有客户端都向这个Region写数据,直到这个Region足够大才进行切分。这样在大量数据并行写入时,容易引起单点负载过高,从而影响入库性能。一个好的方法是在建立HBase表时预先分配数个Region,这样写入数据时,会按照Region分区情况,在集群内做数据的负载均衡。常用命令:
--自定义预分区的RowKey
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30']
--使用文件内容预分区
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe'
--使用内置的分区算法HexStringSplit
hbase> create 't1', 'f1', {NUMREGIONS => 3, SPLITALGO => 'HexStringSplit'}
--指定列族'info'使用'GZ'压缩
hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ'}, {NUMREGIONS =>3, SPLITS => ['10', '20']}
使用最后一个创建'pre'表,然后通过Web页面 http://ncst:60010/table.jsp?name=pre 或者通过HBase shell命令scan 'hbase:meta' 查看hbase命名空间下所有标的元数据信息。
pre,,1442404691018.d514 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => d
e0dcd3d83aa48704d7f9a64 514e0dcd3d83aa48704d7f9a64db575, NAME => 'pre,,1442404691018.d514e0d
db575. cd3d83aa48704d7f9a64db575.', STARTKEY => '', ENDKEY => ''}
pre,10,1442404691018.50 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => 5
42efafeac5c9b6adce9868a 042efafeac5c9b6adce9868a9d0f72e, NAME => 'pre,10,1442404691018.5042e
9d0f72e. fafeac5c9b6adce9868a9d0f72e.', STARTKEY => '', ENDKEY => ''}
pre,20,1442404691018.81 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => 8
77de50218057a033be26c93 177de50218057a033be26c937c07be5, NAME => 'pre,20,1442404691018.8177d
7c07be5. e50218057a033be26c937c07be5.', STARTKEY => '', ENDKEY => ''}
可以看到第一个Region的 STARTKEY => '', ENDKEY => '10',第二个Region的 STARTKEY => '10', ENDKEY => '20',第三个Region的 STARTKEY => '20', ENDKEY => ''。
需要注意的是:
hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ'}, {NUMREGIONS =>3, SPLITS => ['10', '20']}
--上述命令不等同于下面这条命令,并且下面这条命令还是错误的.
--这是因为【预分区】是针对整个Table,而不是某个Column Family
hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ', NUMREGIONS =>3, SPLITS => ['10', '20']}
2.hbase merge regions
对一个表进行预分区后,导入数据发现很多预分的region都没有数据,预分的规则不太好,然后把那些没有数据的region合并,使用hbase 有个merge工具。
用法:hbase org.apache.hadoop.hbase.util.Merge <table_name> <region1> <region2>
具体写法:
//注意:执行该命令前需要停止hbase集群
hbase org.apache.hadoop.hbase.util.Merge pre pre,10,1442404691018.5042efafeac5c9b6adce9868a9d0f72e. pre,20,1442404691018.8177de50218057a033be26c937c07be5.
执行完后重新启动集群,master:60010查看一下该表的regions,可以看到已经合并了。
3.HBase的Bloom Filter
最根本的解释:判断一个元素是否属于这个集合。Bloom Filter是一个很长的二进制向量和一系列随机映射函数
如果这个集合中的元素足够多,那么通过传统遍历的方法进行判断耗时会很多。Bloom Filter就是一种利用很少的空间换取时间的实用方法。但是要说明的是:Bloom Filter的这种高效是有一定代价的,在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(误判存在 false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
1.Bloom Filter的原理?
Bloom Filter是m位的数组,且这个数组的每一位都是零。

Step 1 映射:假如我们有A={x1,x2,x3….xn} n个元素,那么我们需要k个相互独立的哈希Hash函数,将其中每个元素进行k次哈希,他们分别将这个元素映射到m位的数组中,而其映射的位置就置为1,如果有重复的元素映射到这个数组的同一个元素,那么这个元素只会记录一次1,后续的映射将不会改变的这个元素的值。如图:
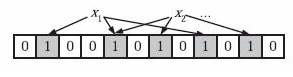
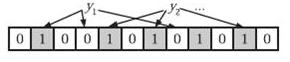
Step 2 判断:在判断B={y1,y2} 这两个元素是否属于A集合时,我们就将这两个元素分别进行上步映射中的k个哈希函数的哈希,如果结果全为1,那么就判断属于A集合,否则判断其不属于A集合。如下图 y2属于,y1则不属于。
2.Bloom filter在HBase中的作用?
HBase利用Bloom filter来提高随机读(Get&Scan)的性能
3.Bloom filter在HBase中的开销?
Bloom filter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloom filter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
4.Bloom filter如何提高随机读的性能?
对于某个region的随机读,HBase会按照一定的顺序遍历每个memstore及storefile,将结果合并返回给客户端。如果你设置了bloomfilter,那么在遍历读storefile时,就可以利用bloomfilter,忽略某些storefile。
5.HBase中的Bloom filter的类型及使用?
a). ROW行级过滤器, 根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloom filter为ROW,那么get(r1)时就会过滤sf1,get(r3)就会过滤sf2
b). ROWCOL行加列级过滤器,根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloom filter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloom filter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
6.ROWCOL一定比ROW效果好么?不一定
a). ROWCOL只对指定列(Qualifier)的随机读(Get)有效,如果应用中的随机读get,只含row,而没有指定读哪个qualifier,那么设置ROWCOL是没有效果的,这种场景就应该使用ROW
b). 如果随机读中指定的列(Qualifier)的数目大于等于2,在0.90版本中ROWCOL是无效的,而在0.92版本以后,HBASE-2794对这一情景作了优化,是有效的(通过KeyValueScanner#seekExactly)
c). 如果同一row多个列的数据在应用上是同一时间put的,那么ROW与ROWCOL的效果近似相同,而ROWCOL只对指定了列的随机读才会有效,所以设置为ROW更佳
7.ROWCOL与ROW只在名称上有联系,ROWCOL并不是ROW的扩展,不能取代ROW
8.region下的storefile数目越多,bloom filter的效果越好
9.region下的storefile数目越少,HBase读性能越好
4.hbaseadmin.balancer()
用hbaseadmin.split()手动对region进行拆分,拆分完之后,每个子region并没有均衡分布到3个regionserver上去。于是手工执行了一下hbaseadmin.balancer(),还是没效果。
查看源码发现原因:banancer()是针对整个集群的region分布,而不是针对某个表的region分布。它只保证每个regionserver上分布的regions在平均regions的0.8到1.2倍之间。
avg = 整个集群的总region数/regionserver个数
min = floor(avg*(1-0.2))
max=ceiling(avg*(1+0.2))
即所有regionserver上的regions个数都在min和max之间的话,就不会执行balancer。
补充说明:默认情况下是针对整个集群的region分布来均衡的,也可以针对表的region来均衡,需要配置:
<property>
<name>hbase.master.loadbalance.bytable</name>
<value>true</value>
</property>
然后重启集群。再执行hbaseadmin.balancer()。可以发现分布在一个regionserver上的一个表的regions被均匀的分布在所有的regionserver上了。
5.hbase宕机处理
HBase的RegionServer宕机超过一定时间后,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据Store和日志HLog都持久在HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
但是重新分配的region需要根据日志HLog恢复原RegionServer中的内存MemoryStore表,这会导致宕机的region在这段时间内无法对外提供服务。
而一旦重分布,宕机的节点重新启动后就相当于一个新的RegionServer加入集群,为了平衡,需要再次将某些Region分布到该server。
HBase优化相关的更多相关文章
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- js DOM优化相关探索
我在这尝试两个方面:-->DOM与js -->DOM与浏览器 (最近在秒味视频上学到不少,哈哈哈) 一.DOM与js 1.js与dom的交互问题 频繁的与dom交互,是一件浪费时间与金钱的 ...
- MySql性能优化相关
原来使用MySql处理的数据量比较少,小打小闹的,没有关注过性能的问题.最近要处理的数据量飙升,每天至少20W行的新增数据,导致MySql在性能方面已经是差到不可用的地步了,必须要重视MySql的优化 ...
- Mysql优化相关总结
Mysql优化相关总结 2016-05-31 数据库集中营 优化顺序: 选择适当的引擎和表结构和数据类型 建立索引,优化sql. 增加缓存,redis.memcache. 主从.主主,读写分离. my ...
- Spark读Hbase优化 --手动划分region提高并行数
一. Hbase的region 我们先简单介绍下Hbase的架构和Hbase的region: 从物理集群的角度看,Hbase集群中,由一个Hmaster管理多个HRegionServer,其中每个HR ...
- HBASE 优化之REGIONSERVER
HBASE 优化之REGIONSERVER 一,概述 本人在使用优化regionserver的过程有些心得,借此随笔的机会,向大家介绍我的心得,有些是网上拿来的有些是自己在使用过程自己的经验,希望对大 ...
- HBase数据库相关基本知识
HBase数据库相关知识 1. HBase相关概念模型 l 表(table),与关系型数据库一样就是有行和列的表 l 行(row),在表里数据按行存储.行由行键(rowkey)唯一标识,没有数据类 ...
- Web 前端性能优化相关内容解析
Web 前端性能优化相关内容,来源于<Google官方网页载入速度检测工具PageSpeed Insights 使用教程>一文中PageSpeed Insights 的相关说明.大家可以对 ...
- Web 前端性能优化相关内容解析[转]
Web 前端性能优化相关内容,来源于<Google官方网页载入速度检测工具PageSpeed Insights 使用教程>一文中PageSpeed Insights 的相关说明.大家可以对 ...
随机推荐
- webpack中,require的五种用法
a.js: module.exports = function(x){ console.log(x); } 一,commonjs同步: var b = require('./a');b('你好')// ...
- 【BZOJ2815】[ZJOI2012]灾难 拓扑排序+LCA
[BZOJ2815][ZJOI2012]灾难 题目描述 阿米巴是小强的好朋友. 阿米巴和小强在草原上捉蚂蚱.小强突然想,果蚂蚱被他们捉灭绝了,那么吃蚂蚱的小鸟就会饿死,而捕食小鸟的猛禽也会跟着灭绝,从 ...
- 边的双联通+缩点+LCA(HDU3686)
Traffic Real Time Query System Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ...
- Code Forces 652A Gabriel and Caterpillar
A. Gabriel and Caterpillar time limit per test 1 second memory limit per test 256 megabytes input st ...
- 第二次去苹果店维修MacBook
今天上午,在使用外接鼠标的情况下,屏幕上鼠标指针乱窜.乱点.不受控制的故障再次出现,这次拍下了视频. 再次去苹果网站预约Genius Bar(天才吧),中午的时候去了苹果店.这次没有像上次那样检查身份 ...
- Use of ‘const’ in Functions Return Values
Use of 'Const' in Function Return Values 为什么要在函数的返回值类型中添加Const? 1.Features Of the possible combinati ...
- HDU_1457_后缀自动机四·重复旋律7
#1457 : 后缀自动机四·重复旋律7 时间限制:15000ms 单点时限:3000ms 内存限制:512MB 描述 小Hi平时的一大兴趣爱好就是演奏钢琴.我们知道一段音乐旋律可以被表示为一段数构成 ...
- scrapy爬虫系列之四--爬取列表和详情
功能点:如何爬取列表页,并根据列表页获取详情页信息? 爬取网站:东莞阳光政务网 完整代码:https://files.cnblogs.com/files/bookwed/yangguang.zip 主 ...
- python重定向sys.stdin、sys.stdout和sys.stderr
转自:https://www.cnblogs.com/guyuyuan/p/6885448.html 标准输入.标准输出和错误输出. 标准输入:一般是键盘.stdin对象为解释器提供输入字符流,一般使 ...
- C++ new 长度为0的数组
在C++中可以new一个长度为0的数组,通过下面的语句: char* p = new char[0]; 指针p中保存一个非NULL的地址,但是你不能够对p指向的内存进行写入,因为p的内存长度为0, 该 ...