Scala Data Structure
Arrays
Array固定长度;ArrayBuffer可变长度arr.toBuffer,buf.toArray
- 初始化是不要使用
new - 使用
()访问元素 - 使用
for (elem <- arr)遍历元素;倒序arr.reverse - 使用
for (elem <- arr if ...) ... yield ...转换为新的数组- 等价于
arr.filter(...).map(...)或者更简洁arr filter { ... } map {...}
- 等价于
- 与 Java 的数组通用,如果是
ArrayBuffer, 可配合scala.collection.JavaConversions使用 - 在做任何操作前都会转换为
ArrayOps对象 - 构建多维数组
val matrix = Array.ofDim[Double](3, 4)// 3 行 4 列
Maps & Tuples
- 创建、查询、遍历 Map 的语法便捷
val scores = Map("a" -> 100, "b" -> 90, "c" -> 95)创建的默认为immutable的 hash map- 可变的 Map 需要显式指定
scala.collection.mutable.Map - 创建空的 Map 需指定类型
new scala.collection.mutable.HashMap[String, Int] - Map 是键值对的集合,键值对类型可不相同
"a" -> 100等价于("a", 100);创建的另一种写法Map(("a", 100), ("b", 90), ("c", 95))
- 访问
scores("a")//返回 Optionscores("d").getOrElse(0)// 返回实际值
- mutable 更新
- 更新值
scores("a") = 80 - 增加元素
scores += ("d" -> 70, "e" -> 50) - 删除元素
scores -= "a"
- 更新值
- immutable 不可更新,修改时会产生新的 Map, 但公共部分的元素数据是共享的
- 添加元素会产生新的 Map,
scores + ("d" -> 70, "e" -> 50) - 删除元素产生新的 Map
scores - "a"
- 添加元素会产生新的 Map,
- 遍历
for((k,v) <- map) ... - 排序 Map
- 按照 key 排序存放
scala.collection.immutable.SortedMap("d" -> 1, "b" -> 2, "c" -> 3)// Map(b -> 2, c -> 3, d -> 1) - 按照插入顺序排放
scala.collection.mutable.LinkedHashMap("d" -> 1, "b" -> 2, "c" -> 3)// Map(d -> 1, b -> 2, c -> 3)
- 按照 key 排序存放
- 区分 mutable 和 immutable
- 默认 hash map,也可使用 tree map
- 与 Java 中的 Map 转换方便
scala.collection.JavaConverters- 在很多时候需要使用 Java 的接口完成任务,但是处理结果时可转换为 Scala 的数据接口来处理更方便,如文件操作等
- Tuples 在聚合操作时很有用
- Map 中的键值对就是最简单的元组形式
(k, v) - 类型不必一致
val a = (1, 3.14, "hello") - 下标访问
a._1// 1 - 模式匹配访问
val (first, second, _) = a - 用于返回多个值
- Map 中的键值对就是最简单的元组形式
- Zipping
- 元组可用于绑定多个值同时处理
zip方法
Collections
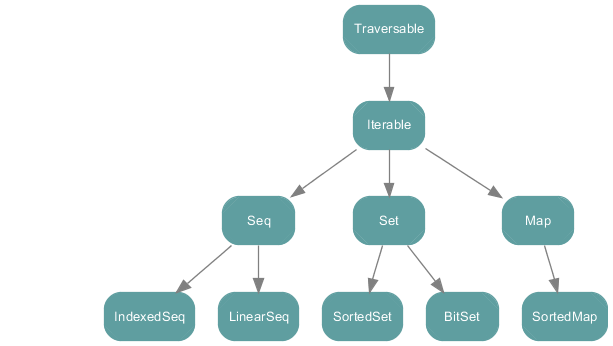
- 集合性能对比
- 多少集合通过
scala.collection.JavaConverters可与 Java 集合互相转换 - 集合区分 generic(
scala.collection)、mutable(scala.collection.mutable) 和 immutable(scala.collection.immutable)- 如果未明确导入包或使用包路径,默认使用 immutable
- 集合
trait或class的伴生对象中,都有apply方法,可直接构造集合实例,如Array(1,2,3) Traversable集合层级的顶部,只有foreach方法是抽象的,其他方法都可直接继承使用Iterable,只有iterator方法是抽象的,其他方法都可直接继承使用- 与
Traversable的区别在于,iterator带状态(可选择获取下一个元素的时间,在获取下一个元素之前会一直跟踪集合中的位置) Iterable中的foreach通过iterator实现
- 与
Seq有序序列,包含length,有固定下标IndexedSeq快速随机访问,通过Vector实现LinearSeq高效的head/tail操作,通过ListBuffer实现
Set无序集合、无重复元素- 默认实现为
HashSet,即元素其实是按照对应的哈希值排序的- 在
HashSet中查找元素远快于在Array或List中查找
- 在
- 默认实现为
Map键值对集合,scala.Predef提供了隐式转换,可直接使用key -> value表示(key, value)SortedMap按 key 排序
Immutable
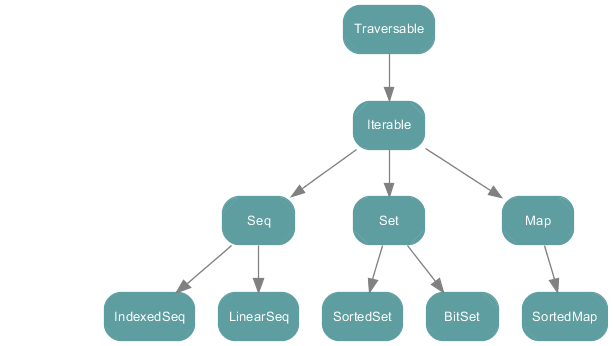
Vector带下标的集合,支持快速的随机访问,相当于 不可变的ArrayBuffer- 通过高分叉因子的树实现,每个节点包含 32 个元素或子节点
- 在快速随机选择和快速随机更新之间保持平衡
- 弥补
List在随机访问上的缺陷
Range有序的整型集合,步长一致1 to 10 by 3即生成 1 到 10 的序列,步长为 3util不包含上边界,to包含上边界- 不存储实际值,只保存
start,end,step三个值
List有限的不可变序列- 为空
Nil,或包含两部分head元素和tail(子List) ::根据给定head和tail构建新的List- 右结合性,即从右侧开始调用
1 :: 2 :: Nil等价于1 :: (2 :: Nil)// 结果 `List(1,2)
- 右结合性,即从右侧开始调用
- 根据
head,tail的特性,可很容易进行递归操作def multi(l: List[Int]): Int = l match {
case Nil => 1
case h :: t => h * multi(t)
}
- 复杂度
- 获取
head,tail只需要常数时间O(1) - 在头部添加元素也只需要常数时间
O(1);可使用mutable.ListBuffer可在头部 或 尾部进行增/删元素操作 - 其他操作需要线性时间
O(N)
- 获取
- 为空
SortedSet有序集合,按顺序访问元素,默认实现为红黑树immutable.BitSet非负整数集合,底层使用Long数组存储- 用较小的整型表示较大的整型,如 3,2,0 二进制表示为
1101,即十进制的 13
- 用较小的整型表示较大的整型,如 3,2,0 二进制表示为
ListMap- 通过键值对的
LinkedList来表示Map - 多数情况下比标准的
Map要慢,因此使用较少- 只有在获取第一个元素较频繁时才比较有优势 (即
List的head)
- 只有在获取第一个元素较频繁时才比较有优势 (即
- 通过键值对的
Stream与List类似,但其元素都是延迟计算的- 长度无限制
- 只有请求的元素会被计算
- 可通过
force来强制进行计算所有元素
- 可通过
- 通过
#::构造,1 #:: 2 #:: 3 #:: Stream.empty结果为Stream(1, ?)此处只打印了head1,而tail未打印,因为还未计算tail
immutable.StackLIFO 序列push入栈 ,pop出栈,top查看栈顶元素- 很少使用,因为其操作都可以被
List包括(push=::,pop=tail,top=head)
immutable.QueueFIFO 序列enqueue入列,可使用集合做参数,一次性入列多个元素dequeue出列,结果包含两部分(element, rest)
Mutable
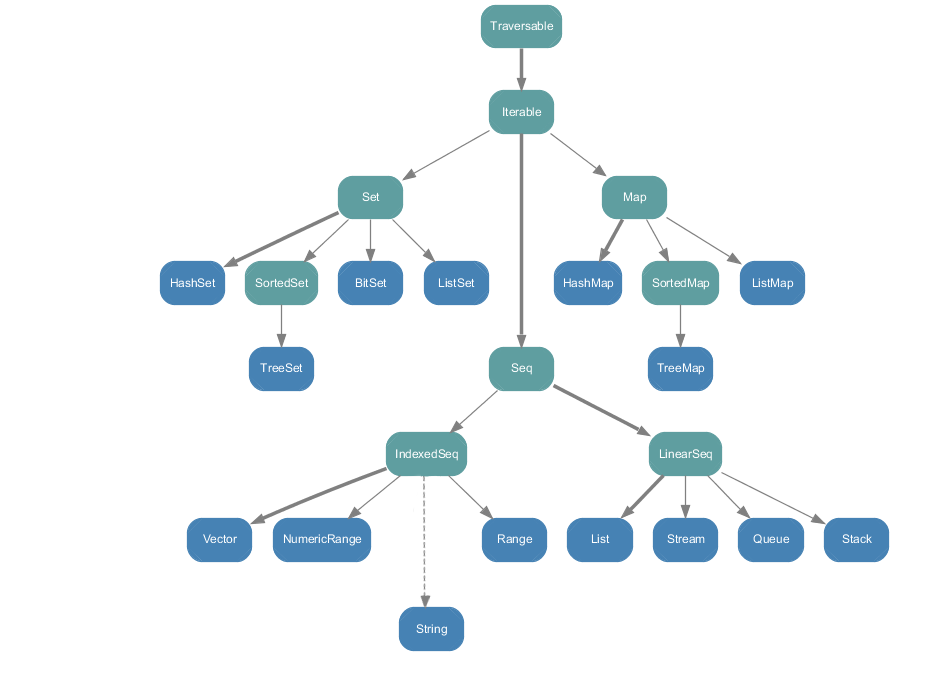
ArrayBuffer- 包含一个
array和size(继承自ResizableArray) - 多数操作速度与
Array相同 - 可向尾部添加元素 (恒定分摊时间,对于更大的集合也可以高效的添加元素)
- 包含一个
ListBuffer,类似于ArrayBuffer但是基于链表实现LinkedList- 元素包含指向下一元素的链接
- 空链表元素自己指向自己
LinkedHashSet除了 Hash 的特点外,会记录元素插入的顺序mutable.Queue+=添加单个元素;++=添加多个元素dequeue移除并返回队首元素
mutable.Stack与不可变版本相同,除了会对原数据发生修改mutable.BitSet直接修改原数据,更新操作比immutable.BitSet更高效
Scala Data Structure的更多相关文章
- [LeetCode] All O`one Data Structure 全O(1)的数据结构
Implement a data structure supporting the following operations: Inc(Key) - Inserts a new key with va ...
- [LeetCode] Add and Search Word - Data structure design 添加和查找单词-数据结构设计
Design a data structure that supports the following two operations: void addWord(word) bool search(w ...
- [LeetCode] Two Sum III - Data structure design 两数之和之三 - 数据结构设计
Design and implement a TwoSum class. It should support the following operations:add and find. add - ...
- Finger Trees: A Simple General-purpose Data Structure
http://staff.city.ac.uk/~ross/papers/FingerTree.html Summary We present 2-3 finger trees, a function ...
- Mesh Data Structure in OpenCascade
Mesh Data Structure in OpenCascade eryar@163.com 摘要Abstract:本文对网格数据结构作简要介绍,并结合使用OpenCascade中的数据结构,将网 ...
- ✡ leetcode 170. Two Sum III - Data structure design 设计two sum模式 --------- java
Design and implement a TwoSum class. It should support the following operations: add and find. add - ...
- leetcode Add and Search Word - Data structure design
我要在这里装个逼啦 class WordDictionary(object): def __init__(self): """ initialize your data ...
- Java for LeetCode 211 Add and Search Word - Data structure design
Design a data structure that supports the following two operations: void addWord(word)bool search(wo ...
- HDU5739 Fantasia(点双连通分量 + Block Forest Data Structure)
题目 Source http://acm.hdu.edu.cn/showproblem.php?pid=5739 Description Professor Zhang has an undirect ...
随机推荐
- MongoDB 数据库的学习与使用
MongoDB 数据库 一.MongoDB 简介(了解) MongoDB 数据库是一种 NOSQL 数据库,NOSQL 数据库不是这几年才有的,从数据库的初期发展就以及存在了 NOSQL 数据库. ...
- Oracle笔记_查询
1 单条件查询 select -- from -- where 条件 -- = > >= < <= != <> -- 单引号用于数据表示字符串 -- 双引号用于数据 ...
- Codeforces 975C
题意略. 思路:这题考察的是二分搜索. #include<bits/stdc++.h> #define maxn 200005 using namespace std; typedef l ...
- xib上的控件属性为什么要使用weak
常规中,从xib拖出一个控件时,系统会自动生成一段代码,如下: 从这个图片中,可以看到控件的属性都是用的weak,这是为什么呢? 首先,如果把weak修改成strong其实也是可以的,但是会出现一个问 ...
- 转载 江南一点雨 一键部署docker
一键部署 Spring Boot 到远程 Docker 容器,就是这么秀! 不知道各位小伙伴在生产环境都是怎么部署 Spring Boot 的,打成 jar 直接一键运行?打成 war 扔到 To ...
- P2486 [SDOI2011]染色 维护区间块数 树链剖分
https://www.luogu.org/problemnew/show/P2486 题意 对一个树上维护两种操作,一种是把x到y间的点都染成c色,另一种是求x到y间的点有多少个颜色块,比如11 ...
- 线段树离散化 unique + 二分查找 模板 (转载)
离散化,把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率. 通俗的说,离散化是在不改变数据相对大小的条件下,对数据进行相应的缩小.例如: 原数据:1,999,100000,15:处理 ...
- poj 3159 Candies(dijstra优化非vector写法)
题目链接:http://poj.org/problem?id=3159 题意:给n个人派糖果,给出m组数据,每组数据包含A,B,c 三个数,意思是A的糖果数比B少的个数不多于c,即B的糖果数 - A的 ...
- CF 450E Jzzhu and Apples 数学+模拟
E. Jzzhu and Apples time limit per test 1 second memory limit per test 256 megabytes input standard ...
- 树莓派4B NAS系统搭建
一.硬盘挂载 由于之前硬盘(NTFS格式)里有数据不想格式化想直接挂载,就没有格式化成ext4文件格式的. 安装ntfs-3g sudo apt-get install ntfs-3g 加载内核模块 ...