用Python爬取猫眼上的top100评分电影
代码如下:
# 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字
import requests
from requests.exceptions import RequestException
import re
import json
#from multiprocessing import Pool # 测试了下 这里需要自己添加头部 否则得不到网页
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
# 得到html代码
def get_one_page(url):
try:
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None # 解析html代码
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?">(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?(/dd)', re.S)
items = re.findall(pattern, html)
for item in items:
# 将元组形式变为字典
yield {
'【排名】': item[0],
'【图片】': item[1],
'【标题】': item[2],
'【主演】': item[3].strip()[3:],
'【上映时间】': item[4].strip()[5:],
'【评分】': item[5] + item[6]
} # 写入文件,写入的是一个json格式的数据
def write_to_file(content):
with open('top100.csv', 'a', encoding = 'utf-8') as f:
f.write(json.dumps(content, ensure_ascii = False) + '\n')
f.close() # 主函数
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item) if __name__ == '__main__':
for i in range(10):
main(i * 10) # 多进程(测试有bug)
# if __name__ == '__main__':
# pool = Pool()
# pool.map(main, [i * 10 for i in range(10)])
# pool.join()
# pool.close()
运行结果如下:
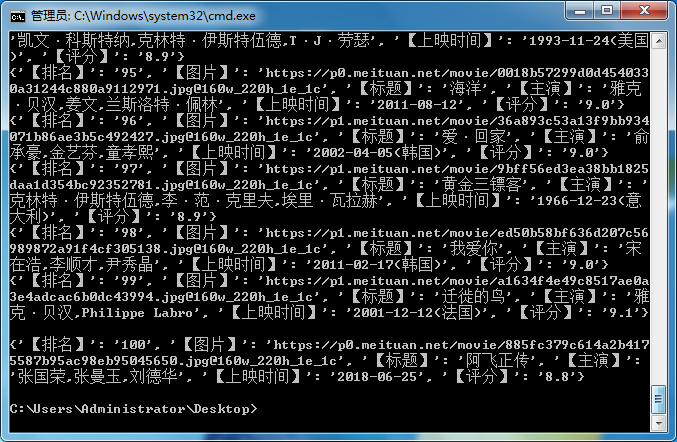
在top100.csv文件中的数据如下:
因为没有下载模块所以这里只是显示首页图片的链接,如果想下载首页图片还需再加上下载模块
用Python爬取猫眼上的top100评分电影的更多相关文章
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- Python爬取猫眼top100排行榜数据【含多线程】
# -*- coding: utf-8 -*- import requests from multiprocessing import Pool from requests.exceptions im ...
随机推荐
- HttpClient基本功能的使用 Get方式
一.GET 方法 使用 HttpClient 需要以下 6 个步骤: 1. 创建 HttpClient 的实例 2. 创建某种连接方法的实例,在这里是 GetMethod.在 ...
- pl/sql中record和%rowtype整理
1. 创建stu表,如下: create table stu(s1 number, s2 number); 2. 定义多维数组, 能用来接受多条返回数据 方式一: type type_name i ...
- react的this.setState中的坑
react的this.setState中的有两个. 1.this.setState异步的,不能用同步的思维讨论问题 2.在进行组件通讯的回调的时候,this指向子组件,没有指向父亲这,怎么办呢.在 c ...
- 导出HTML5 Canvas图片并上传服务器功能
这篇文章主要介绍了导出HTML5 Canvas图片并上传服务器功能,文中通过实例代码给大家介绍了HTML5 Canvas转化成图片后上传服务器,代码简单易懂非常不错,具有一定的参考借鉴价值,需要的朋友 ...
- JS 查找数组的父节点及祖先节点
function findAllParent(node, tree, parentNodes=[], index = 0){ if(!node || node.parentId === 0){ ret ...
- 动态SQL屏幕条件选择(里面还有赋值的新语法)
有时候屏幕条件中使用PARAMETERS时候,如果你为空的话,会查不出数据,但是可能你的想法是不想限制而已,但是系统默认理解为了空值,这个时候,如果取判断一下条件是不是空,在SQL里决定写不写的话,会 ...
- python基础(15):内置函数(一)
1. 内置函数 什么是内置函数? 就是python给你提供的,拿来直接⽤的函数,比如print,input等等,截⽌到python版本3.6.2 python⼀共提供了68个内置函数.他们就是pyth ...
- WeakHashMap,源码解读
概述 WeakHashMap也是Map接口的一个实现类,它与HashMap相似,也是一个哈希表,存储key-value pair,而且也是非线程安全的.不过WeakHashMap并没有引入红黑树来尽量 ...
- XAF中多对多关系 (XPO)
In this lesson, you will learn how to set relationships between business objects. For this purpose, ...
- 解决webservice(Java)中dao层注入为null问题
首先在webservice指定发布的路径类中实现 ServletContextListener, 例如: import javax.servlet.ServletContextEvent; impor ...