BFM模型介绍及可视化实现(C++)
BFM模型介绍及可视化实现(C++)
BFM模型基本介绍
Basel Face Model是一个开源的人脸数据库,其基本原理是3DMM,因此其便是在PCA的基础上进行存储的。
目前有两个版本的数据库(2009和2017)。
官方网站:2009,2017
数据内容(以2009版本为例)
文件内容

01_MorphableModel.mat(数据主体)

BFM模型由53490个顶点构成,其shape/texture的数据长度为160470(53490*3),因为其排列方式如下:
shape: x_1, y_1, z_1, x_2, y_2, z_2, ..., x_{53490}, y_{53490}, z_{53490}
texture: r_1, g_1, b_1, r_2, g_2, b_2, ..., r_{53490}, g_{53490}, b_{53490}
.h5文件与.mat文件对应关系
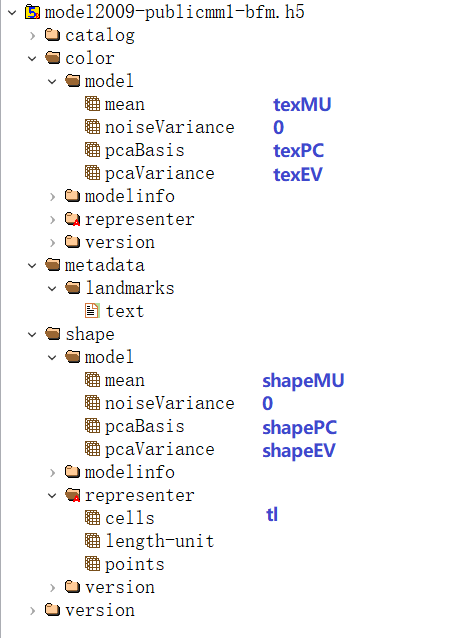
[注] .h5文件中的tl数量与.mat数量不同,主成分方差的值也不同,且shape的值是.mat中shape值的0.001倍(见/shape/representer/length-unit)。
Matlab脚本
建议阅读script_gen_random_head.m文件,该脚本实现了如何生成随机脸,从中我们可以学习到BFM模型的使用方法。
2009与2017版本区别
2009年版本数据集:
- 提供数据格式:mat(
01_MorphableModel.mat)和h5(model2009-publicmm1-bfm.h5); - 提供一系列Matlab脚本,有生成随机脸等功能;
- 提供多种特征点(
PublicMM1/11_feature_points); - 提供segment的mask(
PublicMM1/09_mask); - 提供对称点的对应关系(
PublicMM1/13_symmetry_indices); - 提供属性(
PublicMM1/04_attributes.mat) - 不提供表情;
2017年版本数据集:
- 提供数据格式:h5(原版(
model2017-1_bfm_nomouth.h5)和裁剪过的版本(model2017-1_face12_nomouth.h5)); - 不提供Matlab脚本(本身也无mat格式数据);
- 提供单种特征点(
metadata/landmarks/text); - 不提供segment、对称点的对应关系和属性;
- 提供表情(
expression);
基本原理
目标shape或者texture都可以通过如下式子得到:
obj = average + pc * (coeficient .* pcVariance)
其中系数(coeficient)是变量,其余均是数据库里的常量,其是一个199维(对应199个PC)的向量。
C++实现BFM模型可视工具
数据读取
我们可以读取.mat文件或者.h文件,因为读取.mat文件需要使用Matlab的库文件,我们暂时不考虑。
读取.h5格式文件
.h5文件无法直接通过文本工具打开,需要下载专门的可视工具,此处我使用了HDFView。
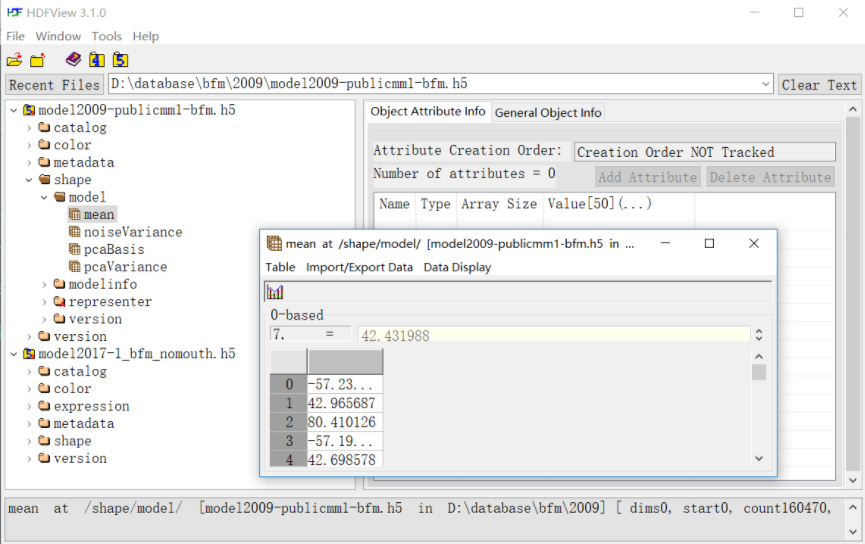
通过该文件我们可以了解到HDF5文件的内部格式。
在C++中使用HDF5读写需要下载官方的库:
HDF5库下载地址
官网右上角注册后下载,随后选择对应版本下载。
[注] 在Windows的Visual Studio使用shared库需要编译过程定义H5_BUILT_AS_DYNAMIC_LIB。(若出现LINK2001错误可以添加这个来解决)
[注] static库命名前面以lib开头,例如hdf5.lib是shared库,libhdf5.lib是static库。
在VS的包含目录和库目录中添加对应的inlcude和lib目录。
在链接器的输入中增加szip.lib;zlib.lib;hdf5.lib;hdf5_cpp.lib;,并将对应的.dll文件放置到Windows/System32或Windows/SysWOW64。
我们只需要用到HDF5中的读取功能,步骤是打开文件->打开数据库->读取数据->关闭数据库->关闭文件。我们以shape平均值为例:
float *shape_mu_raw = new float[N_VERTICE * 3];
H5File file(bfm_h5_path, H5F_ACC_RDONLY);
DataSet shape_mu_data = file.openDataSet("/shape/model/mean");
shape_mu_data.read(shape_mu_raw, PredType::NATIVE_FLOAT);
raw2vector(shape_mu, shape_mu_raw); // 自行将数组转换成想要存放的格式
shape_mu_data.close();
file.close();
shape平均值读取后需要再乘以1000才等同于.mat格式的读取。
需要注意的是数据的读取类型一定要根数据库中的类型一致。shape/tex的类型均为float,对应PredType::NATIVE_FLOAT,tl的类型为unsigned int,对应PredType::NATIVE_UINT32。
[注] 因为缺少pdb文件,HDF5中的代码如果报错可能无法进行调试,需要逐行进行错误的排除,常见错误就是类型不匹配或者长度不匹配。
其他读取方式
在最开始不了解.h5格式的时候,我便使用一些笨方法进行读取,例如先将.mat格式数据转换成二进制文件/文本文件再进行读取。
例如这样一个matlab脚本:
function mat2binary(filename, mat, type)
fid=fopen(filename, 'wb');
matrix = mat;
[m,n]=size(matrix);
for i=1:1:m
for j=1:1:n
fwrite(fid, matrix(i,j), type);
end
end
fclose(fid);
end
这些脚本能够简单地将mat格式进行转换,成为容易被C++进行读取的格式。但是弊端也很明显,在C++中的读写速度非常慢。.h5格式读写1s左右完成,二进制文件读写1分钟左右完成,文本文件读写5分钟左右完成。且在存储大小上,.h5文件(249MB)≈ 二进制文件 < 文本文件(超过710M)。
生成人脸
即按照上述基本原理中的式子进行实现。
OpenGL进行显示
这里使用了Qt5内置的OpenGL模块,通过最简单的glBegin()和glEnd()即可绘出人脸。
double sint = sin(theta), cost = cos(theta);
for (auto t = tl.begin(); t != tl.end(); t++) {
glBegin(GL_TRIANGLES);
vec3 tmp = *t;
glColor3f(tex[tmp.x].x / 255.0, tex[tmp.x].y / 255.0, tex[tmp.x].z / 255.0);
glVertex3f(shape[tmp.x].x * scale * cost - shape[tmp.x].z * scale * sint, shape[tmp.x].y * scale, shape[tmp.x].x * scale * sint + shape[tmp.x].z * scale * cost);
glColor3f(tex[tmp.y].x / 255.0, tex[tmp.y].y / 255.0, tex[tmp.y].z / 255.0);
glVertex3f(shape[tmp.y].x * scale * cost - shape[tmp.y].z * scale * sint, shape[tmp.y].y * scale, shape[tmp.y].x * scale * sint + shape[tmp.y].z * scale * cost);
glColor3f(tex[tmp.z].x / 255.0, tex[tmp.z].y / 255.0, tex[tmp.z].z / 255.0);
glVertex3f(shape[tmp.z].x * scale * cost - shape[tmp.z].z * scale * sint, shape[tmp.z].y * scale, shape[tmp.z].x * scale * sint + shape[tmp.z].z * scale * cost);
glEnd();
}
使用theta和scale参数用于实现鼠标和键盘对模型方向的控制。
根据模型大小,我们设置相应的视角:
void OpenGLWidget::resizeGL(int width, int height) {
glViewport(0, 0, width, height);
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluPerspective(60.0, (GLfloat)width / (GLfloat)height, 1.0, 600000.0);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
gluLookAt(0, 0, 300000.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0);
}
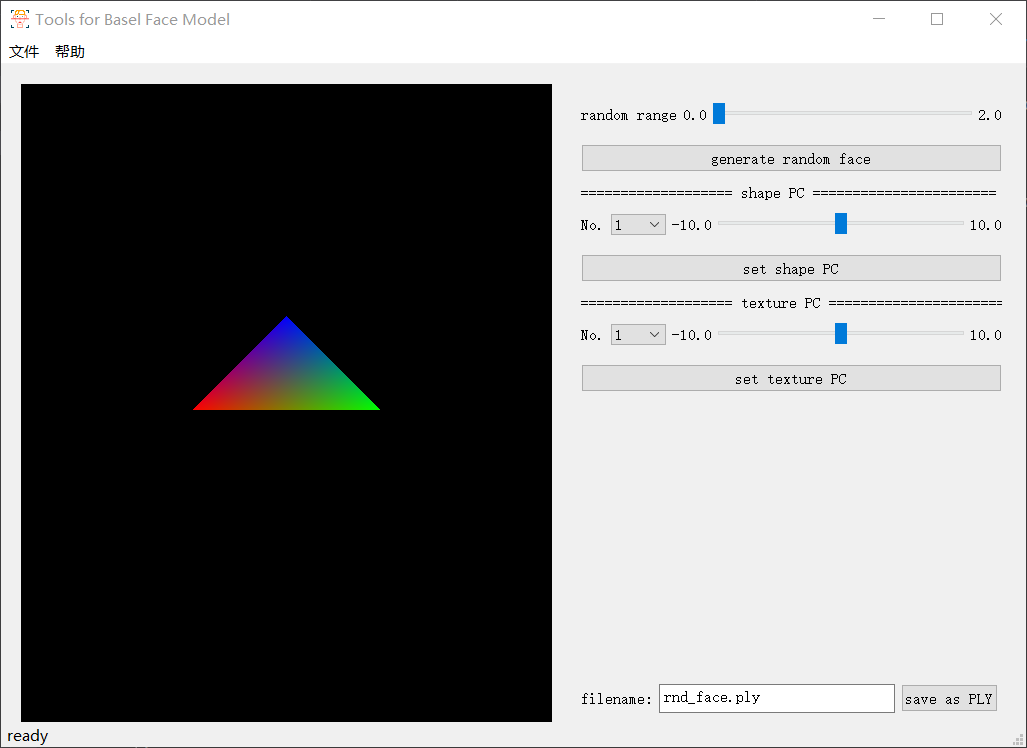
结果展示
初始界面(左侧显示一个彩色三角形):
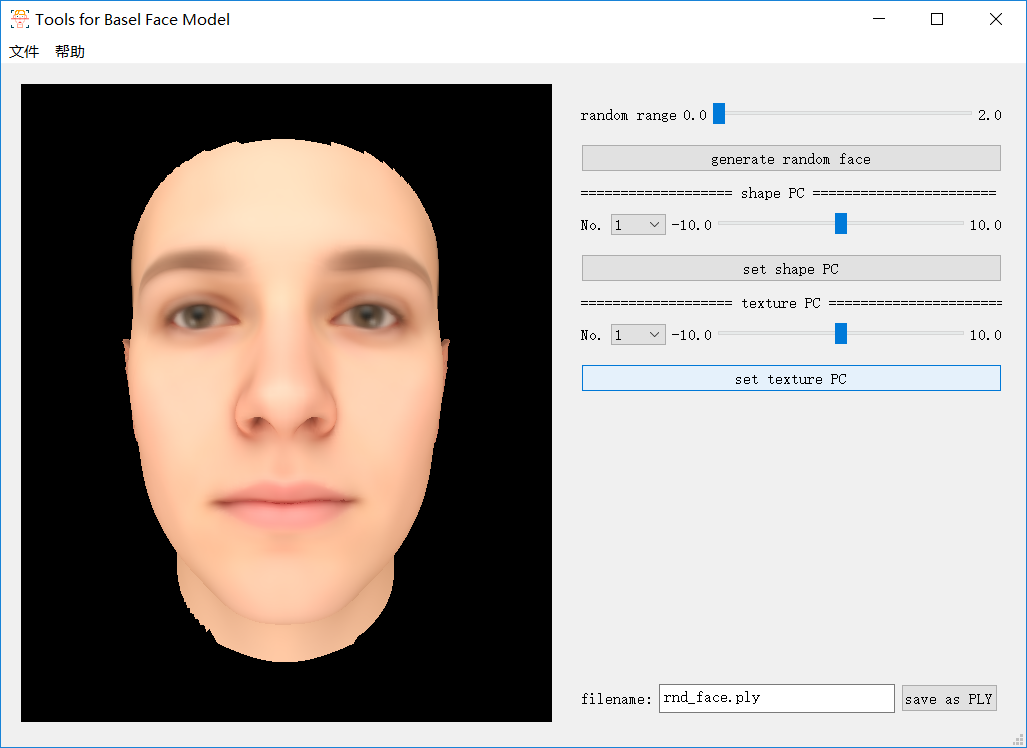
当随机性设置为0(即coeficient设为[0, ..., 0]),生成平均脸:
随机生成人脸,或随机设置PC值:
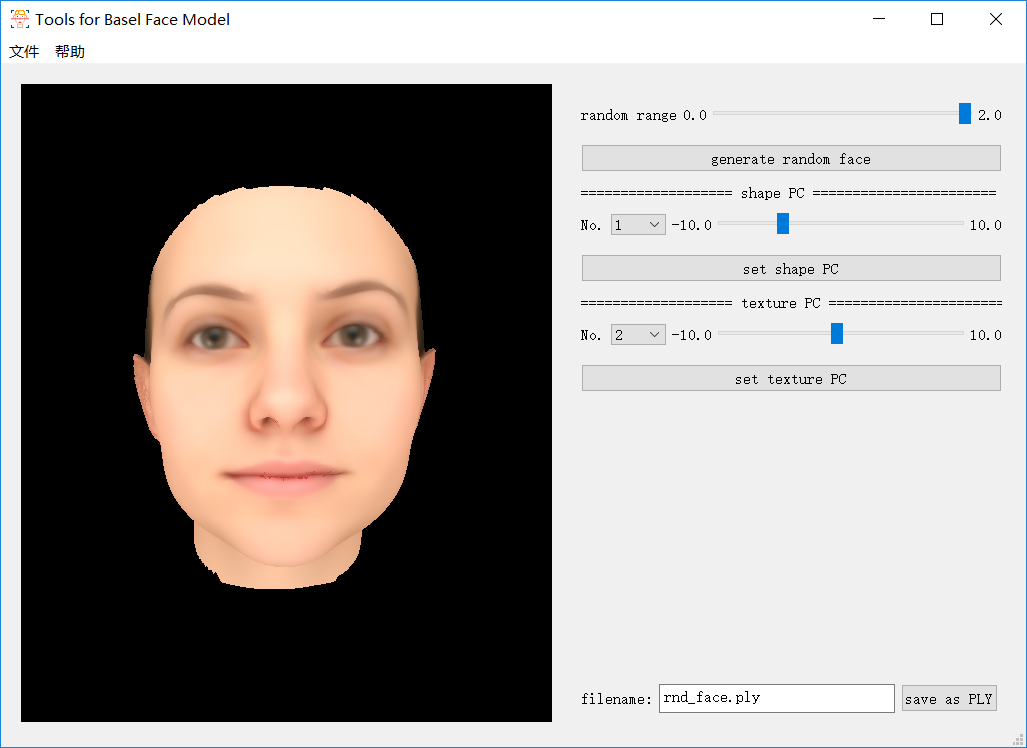
源代码
GitHub:https://github.com/Great-Keith/bfm-visual-tool
BFM模型介绍及可视化实现(C++)的更多相关文章
- 【转载 | 翻译】Visualizing A Neural Machine Translation Model(神经机器翻译模型NMT的可视化)
转载并翻译Jay Alammar的一篇博文:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models Wi ...
- IO模型介绍
先理解几个问题: (1)为什么读取文件的时候,需要用户进程通过系统调用内核完成(系统不能自己调用内核)什么是用户态和内核态?为什么要区分内核态和用户态呢? 在 CPU 的所有指令中,有些指令是非常危险 ...
- 模型介绍之FastText
模型介绍一: 1. FastText原理及实践 前言----来源&特点 fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新.但是它的优点也 ...
- python 全栈开发,Day44(IO模型介绍,阻塞IO,非阻塞IO,多路复用IO,异步IO,IO模型比较分析,selectors模块,垃圾回收机制)
昨日内容回顾 协程实际上是一个线程,执行了多个任务,遇到IO就切换 切换,可以使用yield,greenlet 遇到IO gevent: 检测到IO,能够使用greenlet实现自动切换,规避了IO阻 ...
- {python之IO多路复用} IO模型介绍 阻塞IO(blocking IO) 非阻塞IO(non-blocking IO) 多路复用IO(IO multiplexing) 异步IO(Asynchronous I/O) IO模型比较分析 selectors模块
python之IO多路复用 阅读目录 一 IO模型介绍 二 阻塞IO(blocking IO) 三 非阻塞IO(non-blocking IO) 四 多路复用IO(IO multiplexing) 五 ...
- (zhuan) 深度学习全网最全学习资料汇总之模型介绍篇
This blog from : http://weibo.com/ttarticle/p/show?id=2309351000224077630868614681&u=5070353058& ...
- LDA模型数据的可视化
""" 执行lda2vec.ipnb中的代码 模型LDA 功能:训练好后模型数据的可视化 """ from lda2vec import p ...
- 深入理解 Java 内存模型(一)- 内存模型介绍
深入理解 Java 内存模型(一)- 内存模型介绍 深入理解 Java 内存模型(二)- happens-before 规则 深入理解 Java 内存模型(三)- volatile 语义 深入理解 J ...
- OSI七层网络模型与TCP/IP四层模型介绍
目录 OSI七层网络模型与TCP/IP四层模型介绍 1.OSI七层网络模型介绍 2.TCP/IP四层网络模型介绍 3.各层对应的协议 4.OSI七层和TCP/IP四层的区别 5.交换机工作在OSI的哪 ...
随机推荐
- 【系统设计】分布式唯一ID生成方案总结
目录 分布式系统中唯一ID生成方案 1. 唯一ID简介 2. 全局ID常见生成方案 2.1 UUID生成 2.2 数据库生成 2.3 Redis生成 2.4 利用zookeeper生成 2.5 雪花算 ...
- centos 升级
yum -y update升级所有包同时也升级软件和系统内核 yum -y upgrade只升级所有包,不升级软件和系统内核
- SD-WAN 配置及应用模板**(二)
目录 0. 前言 1. 配置模板 1.1 创建各类 'Feature' 模板: 1.1.1 添加波特率模板 1.1.2 添加 'VPN0' 模板 1.1.3 添加 'VPN10' 模板 1.1.4 添 ...
- 虚拟现实中的Motion Sickness晕动症问题 - VIMS
虚拟现实(VR)中的晕动症 - VIMS 在玩VR的时候,很多玩家都遇到过发晕恶心等症状,这就是晕动症(Motion Sickness,以下或简称MS).MS并不是VR特有的问题.我们在坐船.坐车.坐 ...
- 文件操作——RandomAccessFile
文件操作——RandomAccessFile 构建RandomAccessFileJava提供了一个可以对文件随机访问的操作,访问包括读和写操作.该类名为RandomAccessFile.该类的读 ...
- (7)Cmake的使用简介
CMake是一个跨平台的安装(编译)工具,是一个比Make更高级的的编译配置工具,可以根据不同平台.不同编译器,通过编写CmakeLists,可以控制生成的Makefile,从而控制编译过程. ...
- Android 横竖屏切换生命周期
默认情况下,屏幕会旋转并且会重新走生命周期. 1. 屏幕不旋转 在AndroidManifest文件中的对应Activity中配置android:screenOrientation=”landsc ...
- SpringBoot第二十五篇:SpringBoot与AOP
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/11457867.html 版权声明:本文为博主原创文章,转载请附上博文链接! 引言 作者在实际 ...
- idea中添加Run Dashboard
可以在工程目录下找到.idea文件夹下的workspace.xml,在其中加入以下代码即可: <component name="RunDashboard"> <o ...
- python编程基础之三十五
系统的魔术方法:系统的魔术方法特别多,但是也都特别容易懂,简单的讲就是对系统的内置函数进行重写,你需要什么效果就重写成什么样, 比如说len()方法针对的对象本来没有自定义类的对象,但是当你重写了__ ...