python爬虫学习---爬取微软必应翻译(中英互译)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:OSinooO
本人属于python新手,刚学习的 python爬虫基础迫不及待地想试一试,看了论坛里大佬们写的在线翻译爬虫程序,想着自己把它写出来,以下是我爬微软翻译的过程,作为笔记记录下来:
1.获取信息
要实现在线翻译过程,首先要获得目标网站的信息,我们先打开微软必应翻译的官网(https://cn.bing.com/translator):
我们需要获得它的翻译请求和响应信息,操作如下:
(1)右键“检查”(用的Google Chrome浏览器),进入这个界面:
也可以通过右上角》更多工具》开发者工具进入。
(2)选择“Network”
(3)输入我们想翻译的内容,先输入“hello”,选择简体中文:
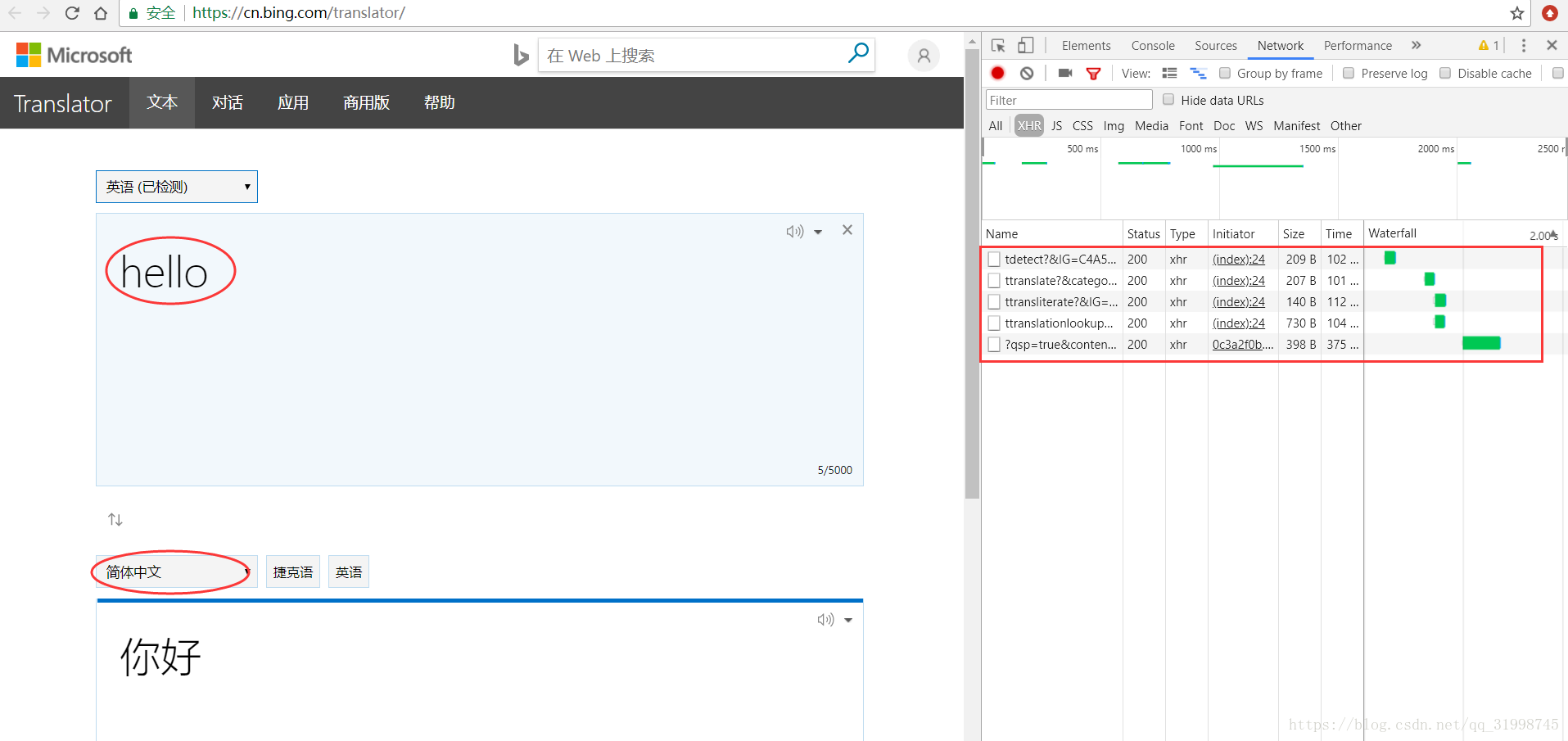
可以看到右边出了很多抓到的包,点开看一下。
(4)找到response(响应)里面出现了翻译结果的包
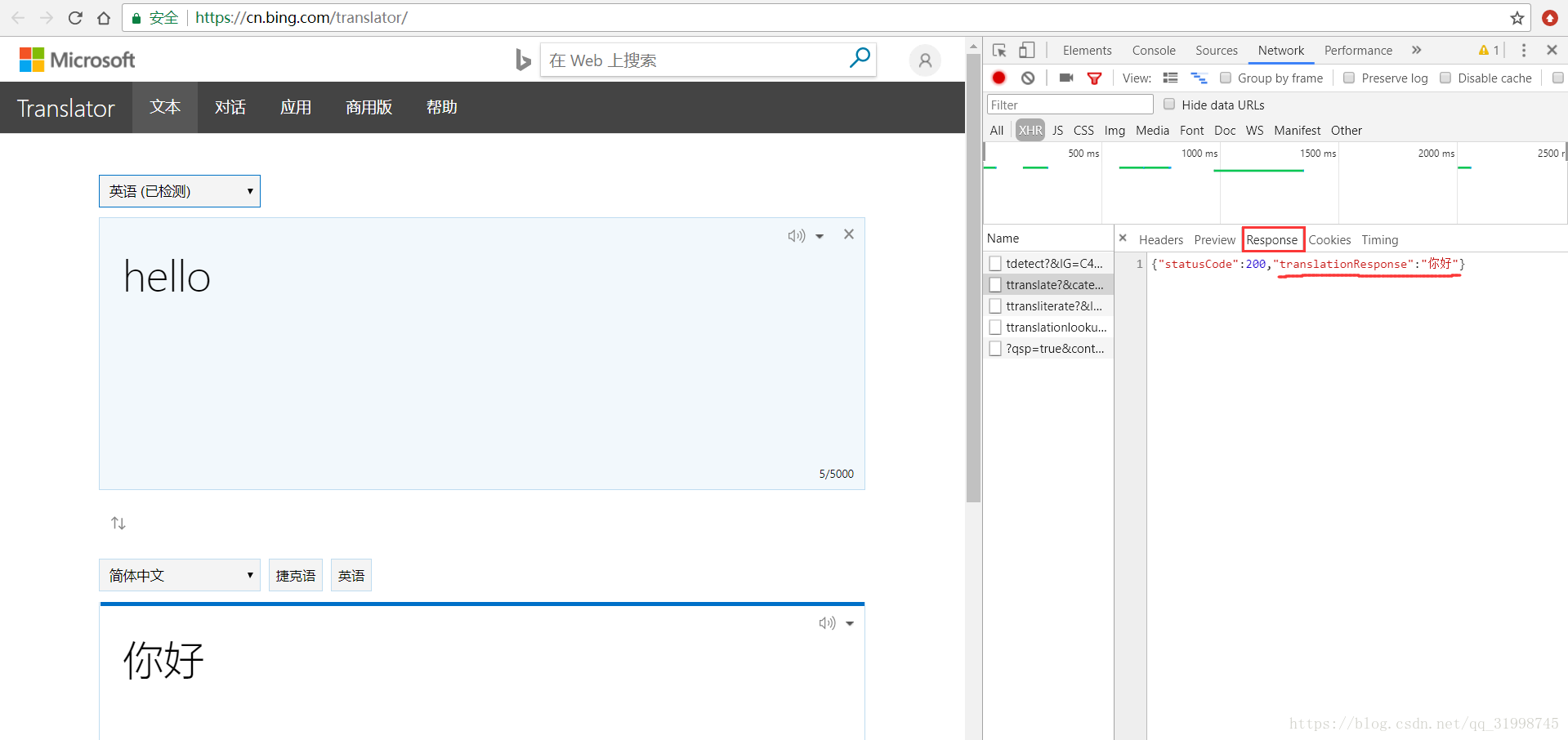
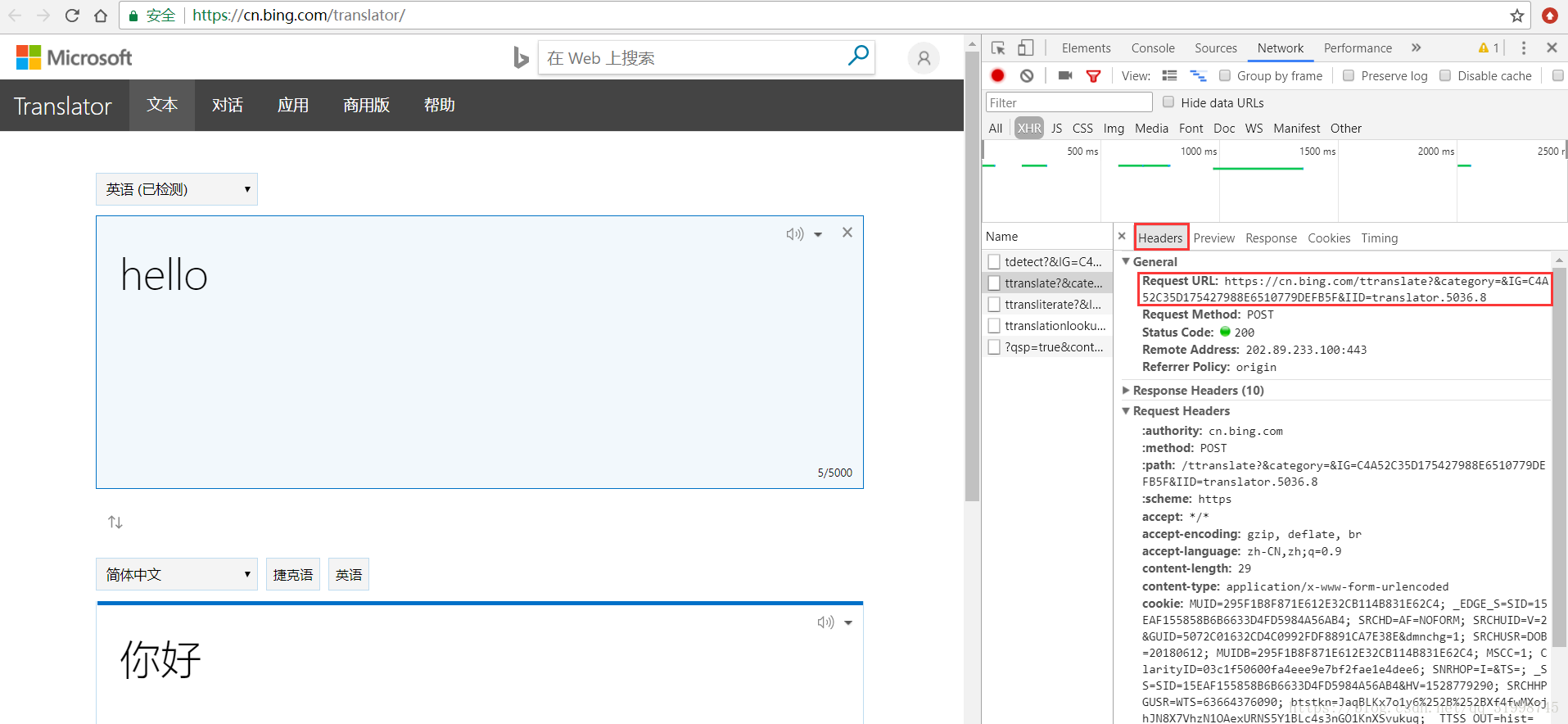
(5)接下来就是获取URL和data信息了,在“Headers”部分就可以看到。这里的URL是处理我们请求翻译的网页地址,当网页请求方式为POST时,请求参数存放在data(类型为字典)里。
URL:https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8
这里我要说明一下,我在第一次找URL的时候找到的是这个:
https://cn.bing.com/ttranslate?&category=&IG=7E72C4A882064F48BAD8D7C06B7F22A9&IID=translator.5036.1
用这个URL也可以翻译,但是只能翻译单个单词和词语,在后面的代码中如果翻译了长句子就会报错。所以提取参数的时候可以把翻译内容多写一点,找到能长句翻译的URL。
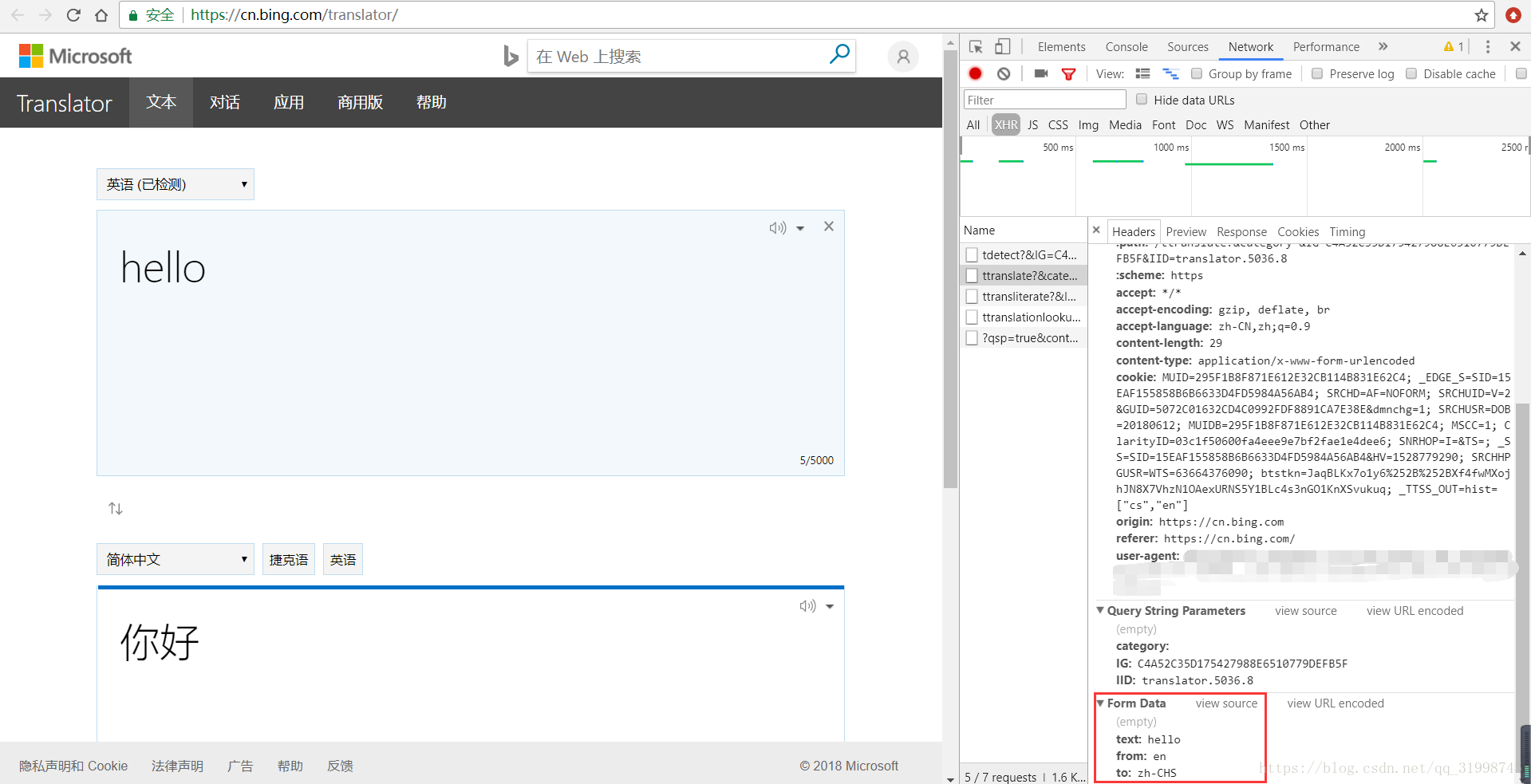
data:{‘text’:'hello', 'from':'en', 'to':'zh-CHS'}这里用字典形式写出来,简单解读就是'text'是翻译的内容,'from'是翻译内容的语言,这里的'en'就代表英语,'to'是翻译结果的语言,'zh-CHS'代表简体中文。这些之后要用到。
2.代码构建
得到信息之后就可以开始写代码了,具体可以参考文章开头的两篇参考博文,这里直接给出代码:如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!
import requests url = 'https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8' def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse']) def is_Chinese(str): #判断输入的内容是否是中文
for ch in str:
if '\u4e00' <= ch <= '\u9fff':
return True
else:
return False def start_translate():
trans = input('翻译内容:')
if is_Chinese(trans): #实现自动判断,中英互译
translate_weiruan(trans)
else:
translate_weiruan(trans,fr='en',to='zh-CHS') if __name__ == '__main__':
print(' 翻译结果由微软翻译提供!(请确保网络已连接)')
while True:
start_translate()
print('\n')
这里用的requests模块,可以用一句话实现我们的功能,具体参考文章开头的第二篇博文。
再简单解释一下:
def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse'])
这段代码的功能就是用POST方式连接翻译网站(url)并给它传参数(data),返回一个 json 类型的信息,再用 json()方法对信息进行处理。返回的信息如下:
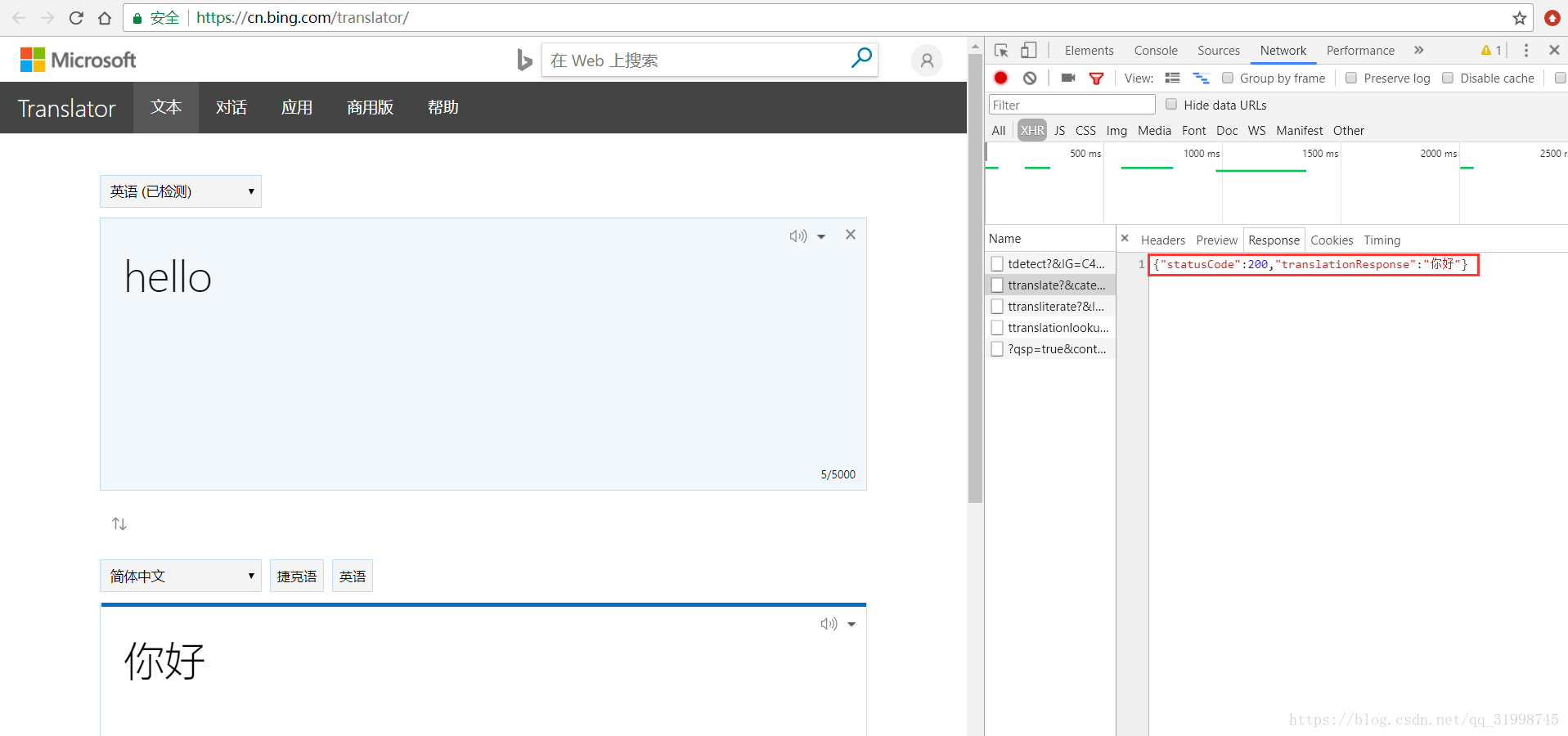
很简单的字典类型:{"statusCode":200,"translationResponse":"你好"}
再用关键字"translationResponse"提取翻译结果。
3.实战结果
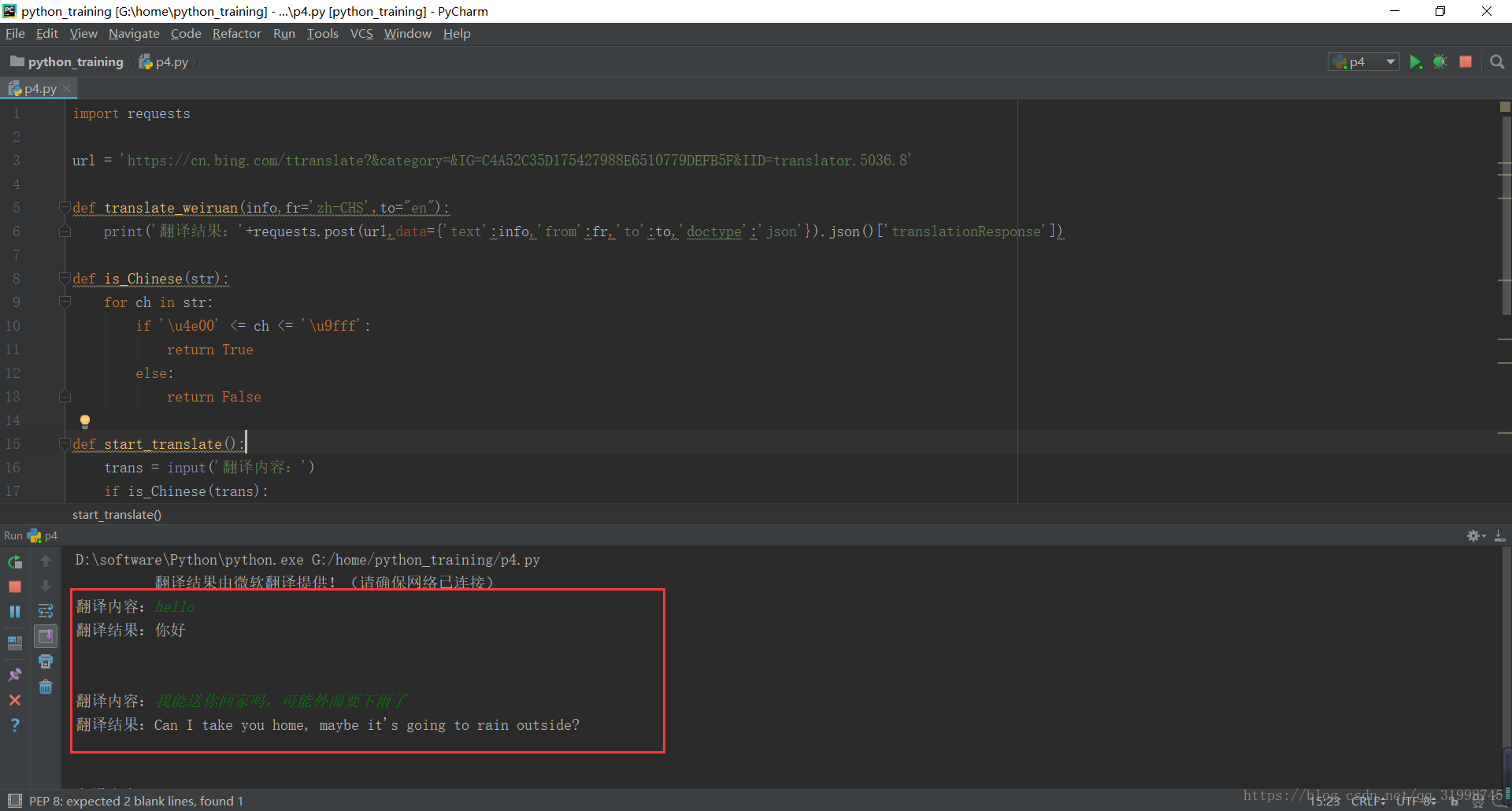
OK,也算是初步完成功能啦!当然里面也还是有很多不足,还请各位大牛指点。如果你也正在学习,可以去如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!
python爬虫学习---爬取微软必应翻译(中英互译)的更多相关文章
- python爬虫学习-爬取某个网站上的所有图片
最近简单地看了下python爬虫的视频.便自己尝试写了下爬虫操作,计划的是把某一个网站上的美女图全给爬下来,不过经过计算,查不多有好几百G的样子,还是算了.就首先下载一点点先看看. 本次爬虫使用的是p ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
随机推荐
- java多线程与线程并发三:线程同步通信
本文章内容整理自:张孝祥_Java多线程与并发库高级应用视频教程. 有些时候,线程间需要传递消息,比如下面这道面试题: 子线程循环10次,然后主线程循环100次,然后又回到子线程循环50次,然后再回到 ...
- (十七)golang--闭包(简单明了)
所谓闭包:就是一个函数和其相关的引用环境组合的一个整体: 首先,有如下一个小例子,最终的输出结果是什么呢?是输出11,12吗? 对上述代码说明:(1)addUpper是一个函数,返回的是func(in ...
- 深入理解 DNS
深入理解 DNS 简介 DNS(Domain Name System)域名系统,它是一个将域名和 IP 地址相互映射的一个分布式数据库,把容易记忆的主机名转换成主机 IP 地址. DNS使用 TCP ...
- Head First设计模式——命令模式
前言:命令模式我们平常可能会经常使用,如果我们不了解命令模式的结构和定义那么在使用的时候也不会将它对号入座. 举个例子:在winform开发的时候我们常常要用同一个界面来进行文件的下载,但是并不是所有 ...
- java实现两个json的深度对比
两个json的深度对比 在网上找了好多资料都没有找到想要的,还是自己写个吧! 上代码!!! 1.pom.xml中加入 <dependency> <groupId>com.ali ...
- thinkphp6.0 开启调试模式以及Driver [Think] not supported
thinkphp6.0 开启调试模式 首先确认自己是通过 composer 进行的下载,然后修改系统目录下的 .example.env 为 .env 文件 修改 config->app.php ...
- Arduino 配置 ESP8266环境
Arduino 配置 ESP8266环境 将 http://arduino.esp8266.com/stable/package_esp8266com_index.json 添加到 [附加开发板管理器 ...
- suseoj 1211: 子集和问题 (dfs)
1211: 子集和问题 时间限制: 1 Sec 内存限制: 128 MB提交: 2 解决: 2[提交][状态][讨论版][命题人:liyuansong] 题目描述 子集和问题的一个实例为<S ...
- 从最近面试聊聊我所感受的.net天花板
#0 前言 入职新公司没多久,闲来无事在博客园闲逛,看到园友分享的面试经历,正好自己这段时间面试找工作,也挺多感想的,干脆趁这个机会总结整理一下.博主13年开始实习,14年毕业.到现在也工作五六年了. ...
- Android ConstraintLayout
对官方例子加上自己的容器即可调整ConstraintLayout实时运行中观察这种布局的变化