10分钟了解一致性hash算法
应用场景
当我们的数据表超过500万条或更多时,我们就会考虑到采用分库分表;当我们的系统使用了一台缓存服务器还是不能满足的时候,我们会使用多台缓存服务器,那我们如何去访问背后的库表或缓存服务器呢,我们肯定不会使用循环或者随机了,我们会在存取的时候使用相同的哈希算法定位到具体的位置。
简单的哈希算法
我们可以根据某个字段(比如id)取模,然后将数据分散到不同的数据库或表中。
例如前期规划,我们某个业务数据5个库就能满足了,根据id取模 如下图
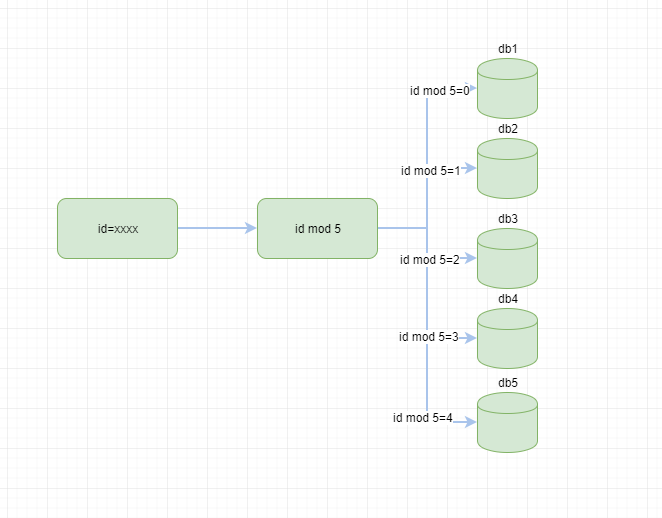
我们通过hash取模很方便的路由到对应的库上,但是上述的简单的hash算法还是有一些缺陷的,假如,5个库也无法满足业务的时候,我们需要9个库,那么原来的取模公式mod 5要变成 mod 9了,并且大部分数据都要重新分布,涉及到数据转移工作量也是巨大的。有没有一劳永逸的方法,答案是有的一致性hash算法
一致性哈希算法
算法概述
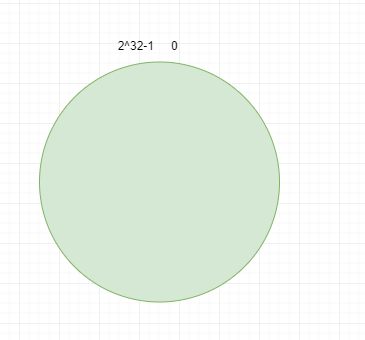
一致性哈希算法(Consistent Hashing),是MIT的karge及其合作者在1997年发表的学术论文提出的,最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - 2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
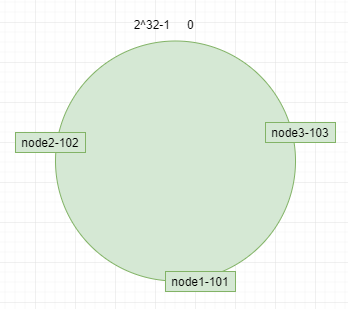
服务器(ip或者主机名)本身进行哈希,确认每台机器在哈希环上的位置,例如ip:192.168.4.101,192.168.4.102,192.168.4.103 分别对应节点node1-101,node2-102,node3-103 如图
数据key使用相同的函数计算出哈希值h,根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,最近的服务器就是其应该定位到的服务器。 例如 我们使用"10","11","12","13","14" 四个数据对象对应key10,key11,key12,key13,key14,经过哈希计算后,在环空间的位置如下:
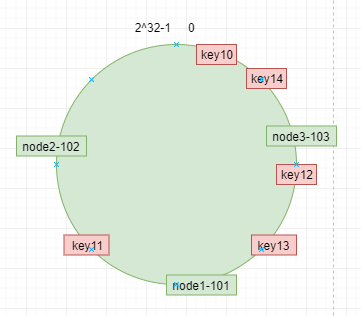
根据一致性哈希算法,数据key10,key14会被定位到节点node3-103上,key12,key13被定位到节点node1-101上,而key11会被定位到节点node2-102上。
扩展性
节点添加
如果我们新增一个节点node4-104 对应的ip:192.168.4.104通过对应的哈希算法得到哈希值,并映射到环中,如下图

通过按顺时针迁移的规则,那么key10被迁移到了node4-104中,其它数据还保持这原有的存储位置
节点删除
如果删除一个节点node3-103,那么按照顺时针迁移的方法,key10,key14将会被迁移到node1-101上,其它的对象没有任何的改动。如下图:

如果服务节点太少的时候,会出现数据分配不均,比如极端情况下所有数据都落到node1-101节点上,如何解决数据倾斜问题,需要引入虚拟节点
虚拟节点
如果节点比较少的情况下,在0到2^32-1形成的环中,会出每个节点存放的数据不均匀;一致性哈希算法提出虚拟节点的解决方案。即虚拟节点时实际节点(物理机器)在hash环中的复制品,一个实际节点对应N多个虚拟节点,这个对应个数也成为了复制个数,虚拟节点在hash环中以hash值排列。
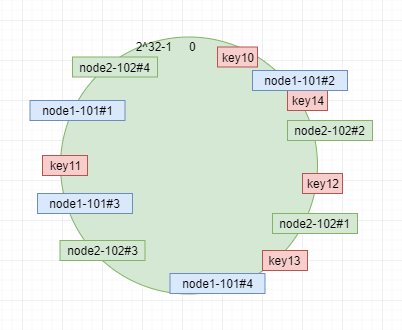
例如 我们以删除了一个点,只剩下 node1 和node2 两个节点的图;我们添加4个虚拟节点,两个节点 则对应8个节点,最后映射关系 如图

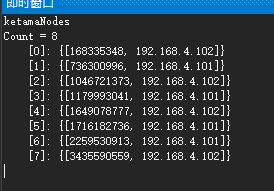
核心代码
public class KetamaNodeLocator
{
private SortedList<long, string> ketamaNodes = new SortedList<long, string>();
private HashAlgorithm hashAlg;
private int numReps = 160;
public KetamaNodeLocator(List<string> nodes, int nodeCopies)
{
ketamaNodes = new SortedList<long, string>();
numReps = nodeCopies;
//对所有节点,生成nCopies个虚拟结点
foreach (string node in nodes)
{
//每四个虚拟结点为一组
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0));
return rv;
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//如果找到这个节点,直接取节点,返回
if (!ketamaNodes.ContainsKey(key))
{
//得到大于当前key的那个子Map,然后从中取出第一个key,就是大于且离它最近的那个key 说明详见: http://www.javaeye.com/topic/684087
var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == 0)
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
}
public class HashAlgorithm
{
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 + nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 + nTime * 4] & 0xFF) << 8)
| ((long)digest[0 + nTime * 4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider();
byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
最后贴上了实现代码,可以运行跑跑,加深理解,希望对您有所帮助,码字不易请多多支持。
参考
代震军----https://www.cnblogs.com/daizhj/archive/2010/08/24/1807324.html
10分钟了解一致性hash算法的更多相关文章
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- [转载] 一致性hash算法释义
转载自http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Ka ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 分布式算法(一致性Hash算法)
一.分布式算法 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法( ...
- 一致性Hash算法及使用场景
一.问题产生背景 在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求.然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的. 那 ...
随机推荐
- Java并发包中线程池ThreadPoolExecutor原理探究
一.线程池简介 线程池的使用主要是解决两个问题:①当执行大量异步任务的时候线程池能够提供更好的性能,在不使用线程池时候,每当需要执行异步任务的时候直接new一个线程来运行的话,线程的创建和销毁都是需要 ...
- 对比 C++ 和 Python,谈谈指针与引用
花下猫语:本文是学习群内 樱雨楼 小姐姐的投稿.之前已发布过她的一篇作品<当谈论迭代器时,我谈些什么?>,大受好评.本文依然是对比 C++ 与 Python,来探讨编程语言中极其重要的概念 ...
- Java NIO学习系列四:NIO和IO对比
前面的一些文章中我总结了一些Java IO和NIO相关的主要知识点,也是管中窥豹,IO类库已经功能很强大了,但是Java 为什么又要引入NIO,这是我一直不是很清楚的?前面也只是简单提及了一下:因为性 ...
- redis快速部署
1. 场景描述 以前是直接使用公司提供的redis集群,只使用不负责维护,因项目用到负载均衡,需要使用redis做session共享,存储session信息,所以就部署了下,记录下以便后续能快速部署. ...
- linux修改时间显示格式
1. 问题描述 Linux下经常使用 "ls - ll"命令查看文件夹或文件创建及权限信息,但是满屏的Mar .May.Jul有点小难受. 2. 解决方案 修改bash_profi ...
- 自定义ApplicationContextInitializer接口实现
简介 ApplicationContextInitializer是Spring框架提供的接口, 该接口的主要功能就是在接口ConfigurableApplicationContext刷新之前,允许用户 ...
- 原创:Python编写通讯录,支持模糊查询,利用数据库存储
1.要求 数据库存储通讯录,要求按姓名/电话号码查询,查询条件只有一个输入入口,自动识别输入的是姓名还是号码,允许模糊查询. 2.实现功能 可通过输入指令进行操作. (1)首先输入“add”,可以对通 ...
- Java虚拟机知识点【内存】
运行时数据区 程序计数器(Program Counter) 每个线程独占自己的程序计数器.如果当前执行的方式不是native的,那程序计数器保存JVM正在执行的字节码指令的地址,如果是native ...
- ajax同步与异步 理解
例如,小明去餐馆排队点餐,前台服务员将小明的菜单告诉厨师进行制作,此时小明后面排队的人就一直等着,直到厨师制作完成,把饭菜送到小明手里后离开,后面的人才能继续点餐:这就是同步处理 但是,如果前台服务员 ...
- sql server中format函数的yyyyMMddHHmmssffff时间格式兼容旧版sql写法
问题:博主看到项目脚本,有些地方使用了format函数来把当前日期转换成yyyyMMddHHmmssffff的格式,但在测试环境数据库是sql 2008 r2,是不支持format这个函数的.脚本会报 ...