分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗
数据库自增ID机制原理介绍
在分布式里面,数据库的自增ID机制的主要原理是:数据库自增ID和mysql数据库的replace_into()函数实现的。这里的replace数据库自增ID和mysql数据库的replace_into()函数实现的。这里的replace into跟insert功能类似,不同点在于:replace into首先尝试插入数据列表中,如果发现表中已经有此行数据(根据主键或唯一索引判断)则先删除,再插入。否则直接插入新数据。
单机mysql数据库的自增id实现如下所示 :
首先表结构如下所示
create table t_test(
id bigint(20) unsigned not null auto_increment PRIMARY KEY,
stub char(1) not null default '',
unique key stub (stub)
)
然后我们插入的sql语句和查询的语句如下所示
replace into t_test (stub) values('b');
select last_insert_id();
此时可以看到看到我们刚刚插入的id值是1

以上就是单机版mysql的自增id的实现过程,但是这里讲的是分布式id,所以我们要分析一下数据库的自增ID机制在分布式里面是怎么实现的。
分布式id在数据库里面的实现过程:
既然是分布式id,那么最少要使用两个数据库,这里我们使用3台来讲解,为了保证每一台数据库里面的id自增的时候不会重复,那么我们就要给每一台数据库设置auto-increment-increment和auto-increment-offset这两个属性值(auto-increment-increment表示每一台数据库的起始id值,然后auto-increment-offset表示每一台数据库每一次的增加数字),设置值如下所示
Server1:
auto-increment-increment = 1
auto-increment-offset = 3
Server2:
auto-increment-increment = 2
auto-increment-offset = 3
Server2:
auto-increment-increment = 3
auto-increment-offset = 3
那么如果我们有n台数据库的话,那么上面的auto-increment-increment和auto-increment-offset这两个属性值应该怎么设计呢,我们给每一台数据库设置初始值分别为1,2,3...N,然后每一台数据库自增步长为机器的台数N,如下图所示
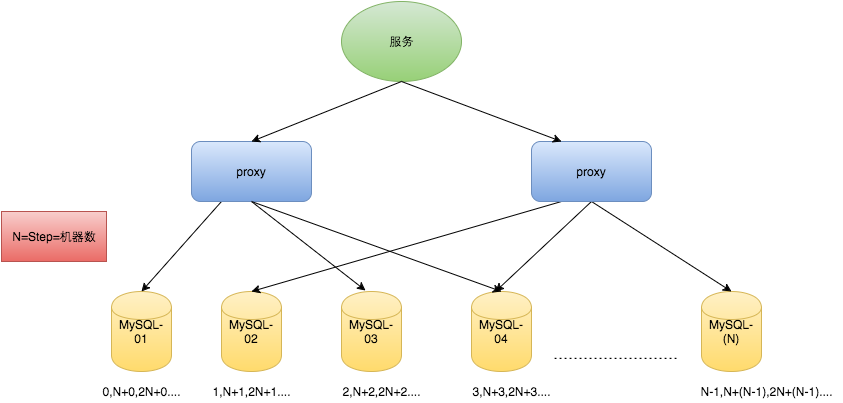
数据库自增ID是否适合做分布式ID:
那数据库自增ID机制适合作分布式ID吗?答案是不太适合,为什么呢,我总结了下面两个原因:
1:系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(主要这里设置14的前提是:在扩容期间第一台机器的ID不可能增加到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合我们定义的号段标准。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
2:数据库压力还是很大,每次获取ID都得读写一次数据库,非常影响性能,不符合分布式ID里面的延迟低和要高QPS的规则(在高并发下,如果都去数据库里面获取id,那是非常影响性能的)
看到这里的同学,觉得好的话就帮忙推荐下吧,Thanks♪(・ω・)ノ
其他分布式ID系列快捷键:
分布式ID系列(1)——为什么需要分布式ID以及分布式ID的业务需求
分布式ID系列(2)——UUID适合做分布式ID吗
分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗
分布式ID系列(4)——Redis集群实现的分布式ID适合做分布式ID吗
分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
分布式ID系列(3)——数据库自增ID机制适合做分布式ID吗的更多相关文章
- 分布式ID系列(2)——UUID适合做分布式ID吗
UUID的生成策略: UUID的方式能生成一串唯一随机32位长度数据,它是无序的一串数据,按照开放软件基金会(OSF)制定的标准计算,UUID的生成用到了以太网卡地址.纳秒级时间.芯片ID码和许多可能 ...
- 分布式ID系列(4)——Redis集群实现的分布式ID适合做分布式ID吗
首先是项目地址: https://github.com/maqiankun/distributed-id-redis-generator 关于Redis集群生成分布式ID,这里要先了解redis使用l ...
- 分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
介绍Snowflake算法 SnowFlake算法是国际大公司Twitter的采用的一种生成分布式自增id的策略,这个算法产生的分布式id是足够我们我们中小公司在日常里面的使用了.我也是比较推荐这一种 ...
- 使用sequelize对数据库进行增删改查
由于本人对于命令比较执着,所以基本都是在命令下操作的,喜欢使用命令的可以使用Cmder,需要安装.配置的可以参考这篇文章: https://www.cnblogs.com/ziyoublog/p/10 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
- mysql 数据库自增id 的总结
有一个表StuInfo,里面只有两列 StuID,StuName其中StuID是int型,主键,自增列.现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,Stu ...
- 解决数据库自增ID的问题
(1)设置主键自增为何不可取这样的话,数据库本身是单点,不可拆库,因为id会重复. (2)依赖数据库自增机制达到全局ID唯一使用如下语句:REPLACE INTO Tickets64 (stub) V ...
- mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0
mysql数据库表自增ID批量清零 AUTO_INCREMENT = 0 #将数据库表自增ID批量清零 SELECT CONCAT( 'ALTER TABLE ', TABLE_NAME, ' AUT ...
随机推荐
- (数据科学学习手札64)在jupyter notebook中利用kepler.gl进行空间数据可视化
一.简介 kepler.gl是由Uber开发的进行空间数据可视化的开源工具,是Uber内部进行空间数据可视化的默认工具,通过其面向Python开放的接口包keplergl,我们可以在jupyter n ...
- BZOJ 1483:[HNOI2009]梦幻布丁(链表启发式合并)
http://www.lydsy.com/JudgeOnline/problem.php?id=1483 题意:中文. 思路:对于每一种颜色,用一个链表串起来,一开始保存一个答案,后面颜色替换的时候再 ...
- MyBatis 核心配置综述之Executor
目录 MyBatis四大组件之 Executor执行器 Executor的继承结构 Executor创建过程以及源码分析 Executor接口的主要方法 Executor 的现实抽象 上一篇我们对Sq ...
- Linux命令学习-wget命令
Linux系统中的wget是一个下载文件的工具,它用在命令行下,通过它可以方便的下载文件. 我们以百度的logo图片链接地址为例:https://www.baidu.com/img/bd_logo.p ...
- .NET CORE上传文件到码云仓库【搭建自己的图床】
.NET CORE上传文件到码云仓库[搭建自己的图床] 先建一个公共仓库(随意提交一个README文件或者.gitignore文件保证master分支的存在),然后到gitee的个人设置页面找到[私人 ...
- Loadrunner基本概念解析<一>
学习性能测试前需要掌握的基本概念,以下做一个记录,本文会持续更新,我期望的是,用通俗简洁的语言来进行更好的理解. [基本概念如下:] ---并发用户数: 1️⃣错误的理解: 使用系统的全部用户数 ...
- 模拟ssh远程执行命令,粘包问题,基于socketserver实现并发的socket
06.27自我总结 1.模拟ssh远程执行命令 利用套接字编来进行远程执行命令 服务端 from socket import * import subprocess server = socket(A ...
- Error:(949) Multiple substitutions specified in non-positional format; Android格式化string.xml
string.xml问题代码 <string name="msg">书名:%s\n价格:%d</string> 异常信息 Error:(949) Multi ...
- C#2.0新增功能05 迭代器
连载目录 [已更新最新开发文章,点击查看详细] 迭代器可用于逐步迭代集合,例如列表和数组. 迭代器方法或 get 访问器可对集合执行自定义迭代. 迭代器方法使用 yield return 语句返 ...
- Java EE.JavaBean
JavaBean是一组可移植.可重用.并可以组装到应用程序中的Java类.一个Model类(属性+构造函数).