Fiddler 手机爬虫
Fiddler抓包工具
配置Fiddler
- 添加证书信任,Tools - Options - HTTPS,勾选 Decrypt Https Traffic 后弹出窗口,一路确认
- ...from browsers only 设置只抓取浏览器的数据包
- Tools - Options - Connections,设置监听端口(默认为8888)
- 关闭Fiddler,再打开Fiddler,配置完成后重启Fiddler(重要)
配置浏览器代理
1、安装Proxy SwitchyOmega插件
2、浏览器右上角:SwitchyOmega->选项->新建情景模式->AID1901(名字)->创建
输入 :HTTP:// 127.0.0.1 8888
点击 :应用选项
3、点击右上角SwitchyOmega可切换代理
Fiddler常用菜单
1、Inspector :查看数据包详细内容
整体分为请求和响应两部分
2、常用菜单
Headers :请求头信息
WebForms: POST请求Form表单数据 :<body>
GET请求查询参数: <QueryString>
Raw 将整个请求显示为纯文本
手机设置
正常版
1、设置手机
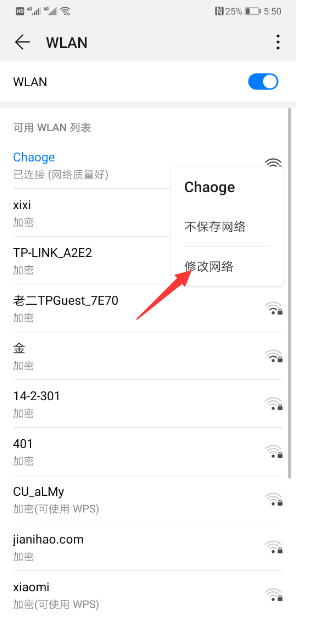
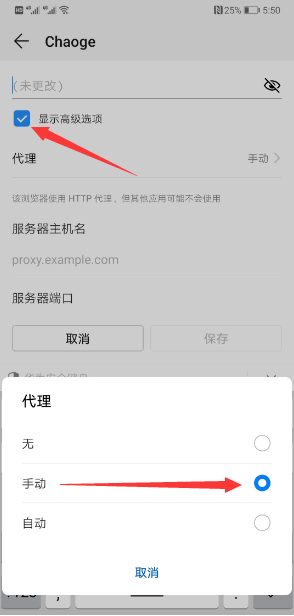
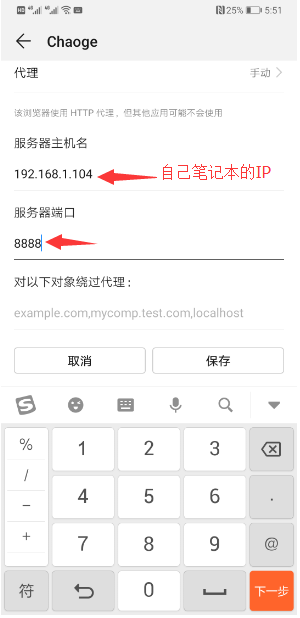

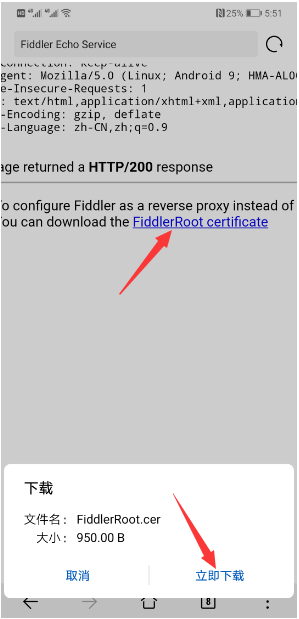

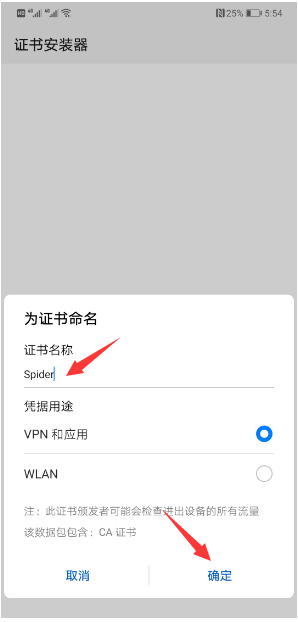
2、设置Fiddler
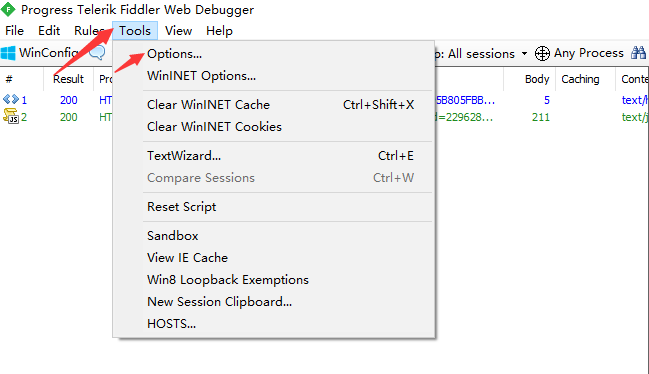
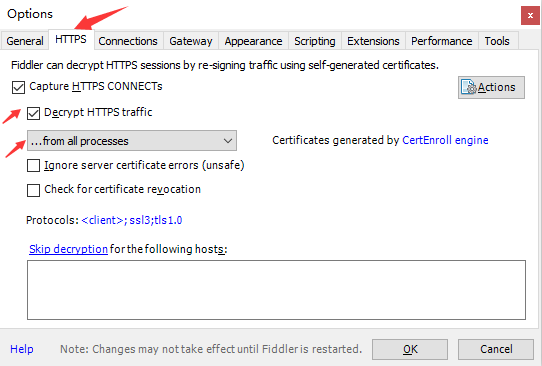
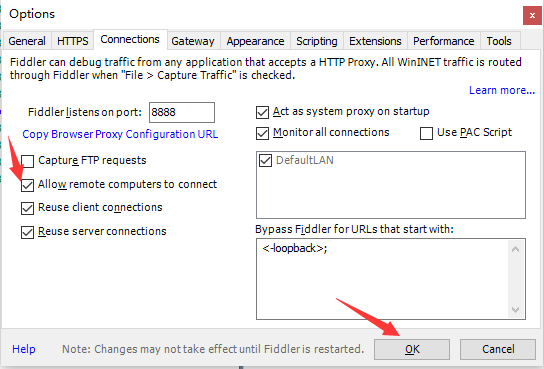
最后重启Fiddler。
如果遇到问题
在计算机中win+R,输入regedit打开注册表,找到fiddler,右键新建点击OWORD(64位)值Q,
名称:80;类型:REG_DWORD;数据:0x00000000(0)
Fiddler在上面的设置下,加上:菜单栏Rules-->Customize Rules...-->重启Fiddler
移动端app数据抓取
有道翻译手机版破解案例
import requests
from lxml import etree
word = input('请输入要翻译的单词:')
url = 'http://m.youdao.com/translate'
data = {
'inputtext': word,
'type': 'AUTO',
}
html = requests.post(url,data=data).text
parse_html = etree.HTML(html)
result = parse_html.xpath('//ul[@id="translateResult"]/li/text()')[0]
print(result)
途牛旅游
目标:完成途牛旅游爬取系统,输入出发地、目的地,输入时间,抓取热门景点信息及相关评论
地址
1、地址: http://www.tuniu.com/
2、热门 - 搜索
3、选择: 相关目的地、出发城市、出游时间(出发时间和结束时间)点击确定
4、示例地址如下:
http://s.tuniu.com/search_complex/whole-sh-0-%E7%83%AD%E9%97%A8/list-a{触发时间}_{结束时间}-{出发城市}-{相关目的地}/
项目实现
1、创建项目
scrapy startproject Tuniu
cd Tuniu
scrapy genspider tuniu tuniu.com
2、定义要抓取的数据结构 - items.py
# 一级页面
# 标题 + 链接 + 价格 + 满意度 + 出游人数 + 点评人数 + 推荐景点 + 供应商
title = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
satisfaction = scrapy.Field()
travelNum = scrapy.Field()
reviewNum = scrapy.Field()
recommended = scrapy.Field()
supplier = scrapy.Field()
# 二级页面
# 优惠券 + 产品评论
coupons = scrapy.Field()
cp_comments = scrapy.Field()
3、爬虫文件数据分析与提取
页面地址分析
http://s.tuniu.com/search_complex/whole-sh-0-热门/list-a20190828_20190930-l200-m3922/
# 分析
list-a{出发时间_结束时间-出发城市-相关目的地}/
# 如何解决?
提取 出发城市及目的地城市的字典,key为城市名称,value为其对应的编码
# 提取字典,定义config.py存放
代码实现
# -*- coding: utf-8 -*-
import scrapy
from ..config import *
from ..items import TuniuItem
import json
class TuniuSpider(scrapy.Spider):
name = 'tuniu'
allowed_domains = ['tuniu.com']
def start_requests(self):
s_city = input('出发城市:')
d_city = input('相关目的地:')
start_time = input('出发时间(20190828):')
end_time = input('结束时间(例如20190830):')
s_city = src_citys[s_city]
d_city = dst_citys[d_city]
url = 'http://s.tuniu.com/search_complex/whole-sh-0-%E7%83%AD%E9%97%A8/list-a{}_{}-{}-{}'.format(start_time,end_time,s_city, d_city)
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
# 提取所有景点的li节点信息列表
items = response.xpath('//ul[@class="thebox clearfix"]/li')
for item in items:
# 此处是否应该在for循环内创建?
tuniuItem = TuniuItem()
# 景点标题 + 链接 + 价格
tuniuItem['title'] = item.xpath('.//span[@class="main-tit"]/@name').get()
tuniuItem['link'] = 'http:' + item.xpath('./div/a/@href').get()
tuniuItem['price'] = int(item.xpath('.//div[@class="tnPrice"]/em/text()').get())
# 判断是否为新产品
isnews = item.xpath('.//div[@class="new-pro"]').extract()
if not len(isnews):
# 满意度 + 出游人数 + 点评人数
tuniuItem['satisfaction'] = item.xpath('.//div[@class="comment-satNum"]//i/text()').get()
tuniuItem['travelNum'] = item.xpath('.//p[@class="person-num"]/i/text()').get()
tuniuItem['reviewNum'] = item.xpath('.//p[@class="person-comment"]/i/text()').get()
else:
tuniuItem['satisfaction'] = '新产品'
tuniuItem['travelNum'] = '新产品'
tuniuItem['reviewNum'] = '新产品'
# 包含景点+供应商
tuniuItem['recommended'] = item.xpath('.//span[@class="overview-scenery"]/text()').extract()
tuniuItem['supplier'] = item.xpath('.//span[@class="brand"]/span/text()').extract()
yield scrapy.Request(tuniuItem['link'], callback=self.item_info, meta={'item': tuniuItem})
# 解析二级页面
def item_info(self, response):
tuniuItem = response.meta['item']
# 优惠信息
coupons = ','.join(response.xpath('//div[@class="detail-favor-coupon-desc"]/@title').extract())
tuniuItem['coupons'] = coupons
# 想办法获取评论的地址
# 产品点评 + 酒店点评 + 景点点评
productId = response.url.split('/')[-1]
# 产品点评
cpdp_url = 'http://www.tuniu.com/papi/tour/comment/product?productId={}'.format(productId)
yield scrapy.Request(cpdp_url, callback=self.cpdp_func, meta={'item': tuniuItem})
# 解析产品点评
def cpdp_func(self, response):
tuniuItem = response.meta['item']
html = json.loads(response.text)
comment = {}
for s in html['data']['list']:
comment[s['realName']] = s['content']
tuniuItem['cp_comments'] = comment
yield tuniuItem
4、管道文件处理 pipelines.py
print(dict(item))
5、设置settings.py
获取出发城市和目的地城市的编号
tools.py
# 出发城市
# 基准xpath表达式
//*//*[@id="niuren_list"]/div[2]/div[1]/div[2]/div[1]/div/div[1]/dl/dd/ul/li[contains(@class,"filter_input")]/a
name : ./text()
code : ./@href [0].split('/')[-1].split('-')[-1]
# 目的地城市
# 基准xpath表达式
//*[@id="niuren_list"]/div[2]/div[1]/div[2]/div[1]/div/div[3]/dl/dd/ul/li[contains(@class,"filter_input")]/a
name : ./text()
code : ./@href [0].split('/')[-1].split('-')[-1]
代码实现
import requests
from lxml import etree
url = 'http://s.tuniu.com/search_complex/whole-sh-0-%E7%83%AD%E9%97%A8/'
headers = {'User-Agent':'Mozilla/5.0'}
html = requests.get(url,headers=headers).text
parse_html = etree.HTML(html)
# 获取出发地字典
# 基准xpath
li_list = parse_html.xpath('//*[@id="niuren_list"]/div[2]/div[1]/div[2]/div[1]/div/div[3]/dl/dd/ul/li[contains(@class,"filter_input")]/a')
src_citys = {}
dst_citys = {}
for li in li_list:
city_name_list = li.xpath('./text()')
city_code_list = li.xpath('./@href')
if city_name_list and city_code_list:
city_name = city_name_list[0].strip()
city_code = city_code_list[0].split('/')[-1].split('-')[-1]
src_citys[city_name] = city_code
print(src_citys)
# 获取目的地字典
li_list = parse_html.xpath('//*[@id="niuren_list"]/div[2]/div[1]/div[2]/div[1]/div/div[1]/dl/dd/ul/li[contains(@class,"filter_input")]/a')
for li in li_list:
city_name_list = li.xpath('./text()')
city_code_list = li.xpath('./@href')
if city_name_list and city_code_list:
city_name = city_name_list[0].strip()
city_code = city_code_list[0].split('/')[-1].split('-')[-1]
dst_citys[city_name] = city_code
print(dst_citys)
Fiddler 手机爬虫的更多相关文章
- Fiddler手机抓包工具如何设置过滤域名?
fiddler手机抓包工具如何设置过滤域名?如题.fiddler抓包可以完成我们移动开发者的调试测试需求.所以说抓包尤其重要,但是多余的网页请求和手机的其他链接影响我们手机开发的需求.下面我教大家怎么 ...
- fiddler 手机 https 抓包 以及一些fiddler无法解决的https问题http2、tcp、udp、websocket证书写死在app中无法抓包
原文: https://blog.csdn.net/wangjun5159/article/details/52202059 fiddler手机抓包原理 fiddler手机抓包的原理与抓pc上的web ...
- 使用Fiddler手机抓包https-----重要
Fiddler不仅可以对手机进行抓包,还可以抓取别的电脑的请求包,今天就想讲一讲使用Fiddler手机抓包! 使用Fiddler手机抓包有两个条件: 一:手机连的网络或WiFi必须和电脑(使用fidd ...
- Fiddler手机https抓包
Fiddler手机抓包:https://blog.csdn.net/wangjun5159/article/details/52202059 fiddler 使用说明:https://www.cnbl ...
- fiddler手机抓包配置方法
一.下载工具包 百度搜索”fiddler 下载“ ,安装最新版本 下载的软件安装包为“fiddler_4.6.20171.26113_setup.exe”格式,双击安装.安装成功,在“开始”-“所有程 ...
- fiddler 手机 https 抓包
fiddler手机抓包原理fiddler手机抓包的原理与抓pc上的web数据一样,都是把fiddler当作代理,网络请求走fiddler,fiddler从中拦截数据,由于fiddler充当中间人的角色 ...
- fiddler手机抓包教程
序言 记录一下自己第一次使用fiddler抓取手机的信息,做一个备忘 实现步骤 一.首先设置一下fiddler,使其对HTTPS协议进行抓包 二.然后设置fidder使得fiddler支持远程计算机连 ...
- [fiddler] 手机抓包
最近工作涉及到与原生app联调,需要抓取手机上的请求.借此机会研究了下fiddler,简直神器. 以下简单介绍通过fiddler进行手机抓包的方法,之后也会陆续更新fiddler的其他功能 设置fid ...
- 使用fiddler手机抓包
Fiddler不但能截获各种浏览器发出的HTTP请求, 也可以截获各种智能手机发出的HTTP/HTTPS请求. Fiddler能捕获IOS设备发出的请求,比如IPhone, IPad, MacBook ...
随机推荐
- wamp不显示文件图标
wamp不显示文件图标 效果如下图 右键图片"在新的标签页打开图片"后会跳转到404页面,并显示The requested URL /icons/unknown.gif was n ...
- html的一些基本语法学习与实战
其实在学校前端开始之前,问过自己为什么要学,因为自己学的比较杂,直到现在刚刚毕业出来工作了,才明确了方向了,要往嵌入式方向走,但是随着时代的发展,在编程和智能硬件结合的越来越紧密,特别是物联网这一块, ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- indexedDB添加,删除,获取,修改
[toc] 在chrome(版本 70.0.3538.110)测试正常 编写涉及:css, html, js 在线演示codepen html代码 <h1>indexedDB</h1 ...
- 剑指offer-链表
1. 链表中环的入口节点 给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null. 思路一:用哈希表存已经遍历过的节点,O(1)复杂度查找,如果再次遇到就是环入口 # -*- cod ...
- mybatis学习的终极宝典
**********************************************************************************************一:myba ...
- 如何在GitHub上上传自己本地的项目?(很适合新手使用哦!)
这是我看了一些大佬们的博客后,尝试了几次,终于成功了上传项目,所以想做一下总结,以便以后查看,同时想分享给才接触GitHub的新手们,希望能够有所帮助~ 条条大路通罗马,上传的方法肯定不止一种,等我学 ...
- Tomcat源码分析 (八)----- HTTP请求处理过程(一)
终于进行到Connector的分析阶段了,这也是Tomcat里面最复杂的一块功能了.Connector中文名为连接器,既然是连接器,它肯定会连接某些东西,连接些什么呢? Connector用于接受请求 ...
- springboot+mybatis+druid+atomikos框架搭建及测试
前言 因为最近公司项目升级,需要将外网数据库的信息导入到内网数据库内.于是找了一些springboot多数据源的文章来看,同时也亲自动手实践.可是过程中也踩了不少的坑,主要原因是我看的文章大部分都是s ...
- 使用docker快速搭建本地环境
在平时的开发中工作中,环境的搭建其实一直都是一个很麻烦的事情 特别是现在,系统越来越复杂,所需要连接的一些中间件也越来越多. 然而要顺利的安装好这些中间件也是一个比较费时费力的工作. 俗话说" ...