Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫
网络爬虫大体可以分为三个步骤。
首先建立请求,爬取所需元素;
其次解析爬取信息,剔除无效数据;
最后将爬取信息进行保存;
今天就先来讲讲第一步,请求库requests
request库主要有七个常用函数,如下所示
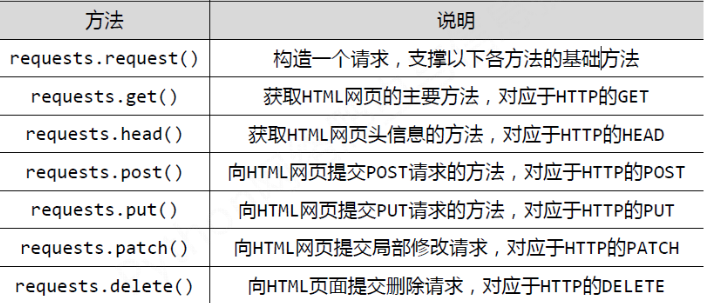
而通过requests创建的数据类型为response
我们以爬取百度网站为例
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
运行结果如下所示
<class 'requests.models.Response'>
[Finished in 1.3s]
那么作为请求对象,具有哪些属性呢?
爬取数据第一步要做的事便是确认是否连接成功
status_code()从功能角度考虑,算的上是一种判断函数,调用将会返还结果是否成功
如果返回结果为200,则代表连接成功,如果返回结果为404,则代表连接失败
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
如图所示返回结果为200,连接成功

那么下一步便是获得网址代码,不过在获得代码之前,还需要做一件事,得到响应内容的编码方式
不同的编码方式将会影响爬取结果
比如说百度网址:https://www.baidu.com/
采用编码方式为ISO-8859-1
获取编码方式为encoding
如下所示
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
print(t.encoding)
结果:
<class 'requests.models.Response'>
200
ISO-8859-1
当然有的网页采用 utf8,也有使用gbk,
不同的编码方式会影响我们获得的源码
也可以通过手动更改来改变获得的编码方式
比如:
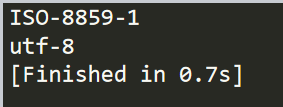
import requests as r
t=r.get("https://www.baidu.com/")
print(t.encoding)
t.encoding="utf-8"
print(t.encoding)
结果
也可以试着备选码方式,apparent_encoding
之后我们就可以获得源代码了,我们需要将源代码以字符串类型输出保存
这就需要用到text
如下所示:
import requests as r
t=r.get("https://www.baidu.com/")
print(t.text)
结果:

这样我们就获得了对应网站的源码,完成了爬虫的第一步
Python爬虫的开始——requests库建立请求的更多相关文章
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
随机推荐
- python学习-面向对象(六)
1.类中的实例方法 self参数最大的作用是引用当前方法的调用者 类调用实例方法,python不会位为一个参数绑定调用者(因为实例方法的调用者应该是对象,而此时是类) 2.类方法与静态方法
- odoo联调
odoo联调(剑飞花 373500710) 1.准备工作 1.1.参考文章“odoo8.0+PyCharm4.5开发环境配置”配置好odoo开发环境 1.2.下载Chrome浏览器,安装. 1.3.下 ...
- C#数据转换
C 货币 2.5.ToString("C") ¥2.50 D 十进制数 25.ToString("D5") 00025 E 科学型 25000.ToString ...
- Vue系列---源码调试(二)
我们要对Vue源码进行分析,首先我们需要能够对vue源码进行调式(这里的源码调式是ES6版本的,不是打包后的代码),因此首先我们要去官方github上克隆一份vue项目下来,如下具体操作: 1. cl ...
- 云计算 docker 容器使用命令
docker 使用命令: docker version 查看docker版本号 vi /etc/docker/daemon.json { "registry-mirrors": [ ...
- 下载达 10 万次的 IDEA 插件,K8s 一键部署了解一下?
作者 | 铃儿响叮当 导读:涉及开发的技术人员,永远绕不开的就是将应用部署到相应服务器上,本文将给大家讲解:对于容器服务 ACK,怎么实现真正"一键部署",提高开发部署效率,在 K ...
- java 实现基于opencv全景图合成
因项目需要,自己做了demo,从中学习很多,所以分享出来,希望有这方面需求的少走一些弯路,opencv怎么安装网上教程多多,这里不加详细说明,我安装的opencv-3.3.0 如上图所示,找到相应的j ...
- Redis备忘(二)
内存回收: 有时候发现10g的Redis删掉1g的key,内存占用没啥变化,因为内存页分配,有的页面可能还存在key,整个页面不能回收. 主从同步: CAP原理:一致性 可用性 分区容忍性 redis ...
- OptimalSolution(8)--位运算
一.不用额外变量交换两个整数的值 如果给定整数a和b,用以下三行代码即可交换a和b的值.a = a ^ b; b = a ^ b; a = a ^ b; a = a ^ b :假设a异或b的结果记为c ...
- 修改vuex状态机中的数据
vuex状态机中的数据是必须提交mutation来修改,如果现实开发中,我们需要修改,而又不想提交mutaition,应该怎么做呢? 先来回顾一下场景,有一个列表是存在vuex中的 这个列表展 ...