玩透二叉树(Binary-Tree)及前序(先序)、中序、后序【递归和非递归】遍历

基础预热:
结点的度(Degree):结点的子树个数;
树的度:树的所有结点中最大的度数;
叶结点(Leaf):度为0的结点;
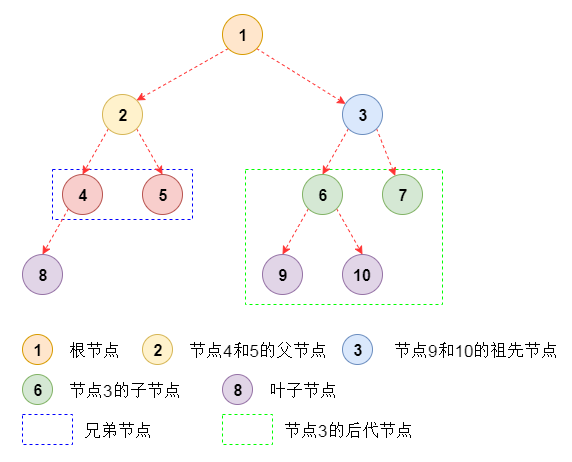
父结点(Parent):有子树的结点是其子树的根节点的父结点;
子结点/孩子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;
兄弟结点(Sibling):具有同一个父结点的各结点彼此是兄弟结点;
路径和路径长度:从结点n1到nk的路径为一个结点序列n1,n2,…,nk。ni是ni+1的父结点。路径所包含边的个数为路径的长度;
祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点;
子孙结点(Descendant):某一结点的子树中的所有结点是这个结点的子孙;
结点的层次(Level):规定根结点在1层,其他任一结点的层数是其父结点的层数加1;
树的深度(Depth):树中所有结点中的最大层次是这棵树的深度;
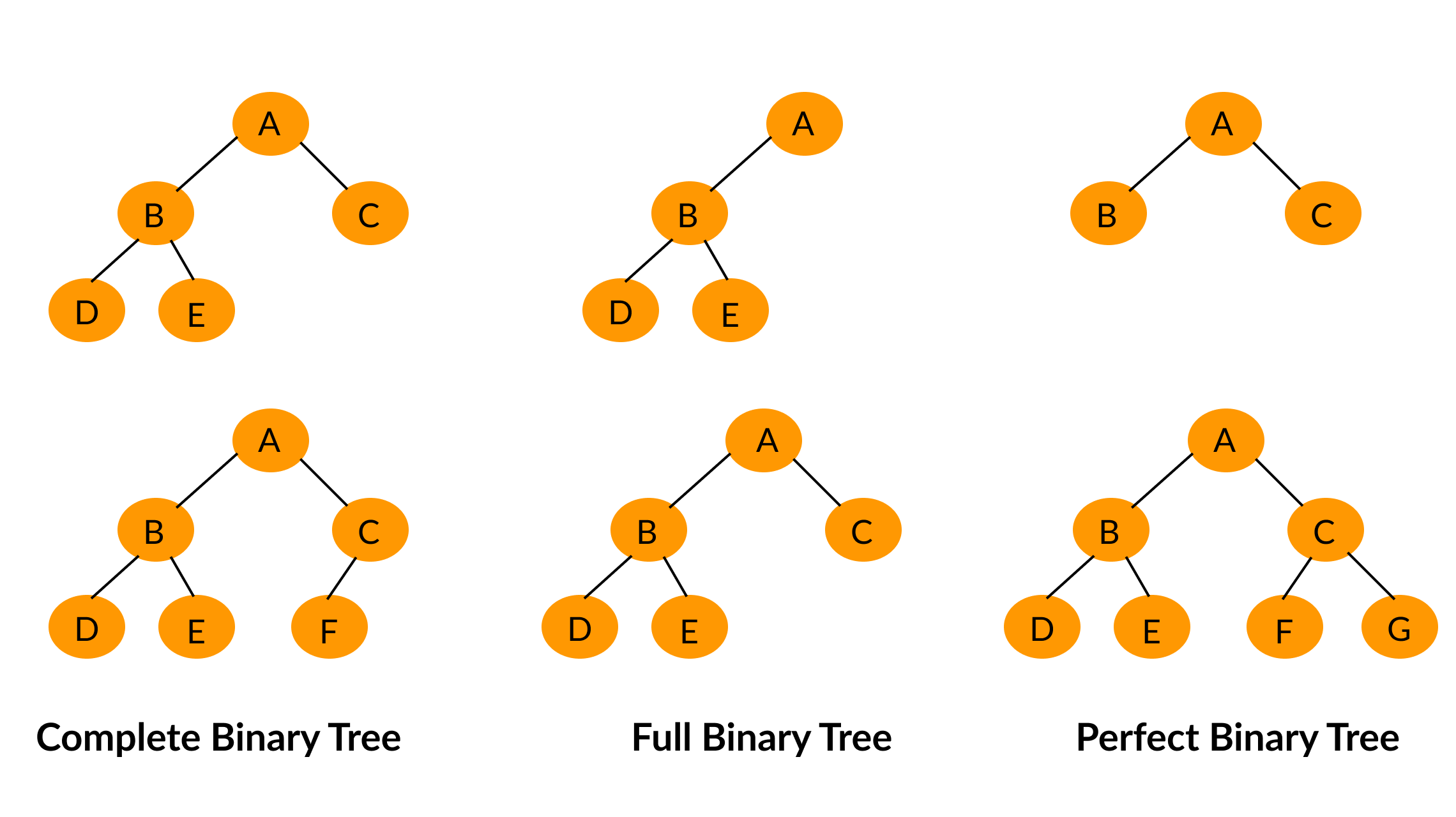
满二叉树
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点二叉树。
完全二叉树
一棵二叉树至多只有最下面的一层上的结点的度数可以小于2,并且最下层上的结点都集中在该层最左边的若干位置上,则此二叉树成为完全二叉树。
平衡二叉树
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
前序、中序、后序
首先给出二叉树节点类:
树节点:
class TreeNode {
int val;
//左子树
TreeNode left;
//右子树
TreeNode right;
//构造方法
TreeNode(int x) {
val = x;
}
}
无论是哪种遍历方法,考查节点的顺序都是一样的(思考做试卷的时候,人工遍历考查顺序)。只不过有时候考查了节点,将其暂存,需要之后的过程中输出。

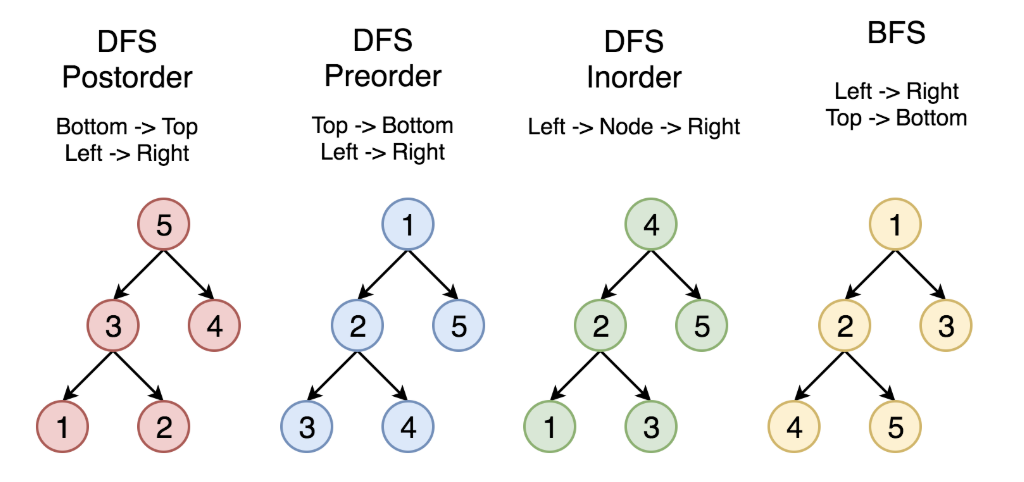
如图1所示,三种遍历方法(人工)得到的结果分别是:
先序:1 2 4 6 7 8 3 5
中序:4 7 6 8 2 1 3 5
后序:7 8 6 4 2 5 3 1
三种遍历方法的考查顺序一致,得到的结果却不一样,原因在于:
先序:考察到一个节点后,即刻输出该节点的值,并继续遍历其左右子树。(根左右)
中序:考察到一个节点后,将其暂存,遍历完左子树后,再输出该节点的值,然后遍历右子树。(左根右)
后序:考察到一个节点后,将其暂存,遍历完左右子树后,再输出该节点的值。(左右根)
先序遍历
递归先序遍历
递归先序遍历很容易理解,先输出节点的值,再递归遍历左右子树。中序和后序的递归类似,改变根节点输出位置即可。
// 递归先序遍历
public static void recursionPreorderTraversal(TreeNode root) {
if (root != null) {
System.out.print(root.val + " ");
recursionPreorderTraversal(root.left);
recursionPreorderTraversal(root.right);
}
}
非递归先序遍历
因为要在遍历完节点的左子树后接着遍历节点的右子树,为了能找到该节点,需要使用栈来进行暂存。中序和后序也都涉及到回溯,所以都需要用到栈。

遍历过程参考注释
// 非递归先序遍历
public static void preorderTraversal(TreeNode root) {
// 用来暂存节点的栈
Stack<TreeNode> treeNodeStack = new Stack<TreeNode>();
// 新建一个游标节点为根节点
TreeNode node = root;
// 当遍历到最后一个节点的时候,无论它的左右子树都为空,并且栈也为空
// 所以,只要不同时满足这两点,都需要进入循环
while (node != null || !treeNodeStack.isEmpty()) {
// 若当前考查节点非空,则输出该节点的值
// 由考查顺序得知,需要一直往左走
while (node != null) {
System.out.print(node.val + " ");
// 为了之后能找到该节点的右子树,暂存该节点
treeNodeStack.push(node);
node = node.left;
}
// 一直到左子树为空,则开始考虑右子树
// 如果栈已空,就不需要再考虑
// 弹出栈顶元素,将游标等于该节点的右子树
if (!treeNodeStack.isEmpty()) {
node = treeNodeStack.pop();
node = node.right;
}
}
}
先序遍历结果:
递归先序遍历: 1 2 4 6 7 8 3 5
非递归先序遍历:1 2 4 6 7 8 3 5
中序遍历
递归中序遍历
过程和递归先序遍历类似
// 递归中序遍历
public static void recursionMiddleorderTraversal(TreeNode root) {
if (root != null) {
recursionMiddleorderTraversal(root.left);
System.out.print(root.val + " ");
recursionMiddleorderTraversal(root.right);
}
}
非递归中序遍历
和非递归先序遍历类似,唯一区别是考查到当前节点时,并不直接输出该节点。
而是当考查节点为空时,从栈中弹出的时候再进行输出(永远先考虑左子树,直到左子树为空才访问根节点)。
// 非递归中序遍历
public static void middleorderTraversal(TreeNode root) {
Stack<TreeNode> treeNodeStack = new Stack<TreeNode>();
TreeNode node = root;
while (node != null || !treeNodeStack.isEmpty()) {
while (node != null) {
treeNodeStack.push(node);
node = node.left;
}
if (!treeNodeStack.isEmpty()) {
node = treeNodeStack.pop();
System.out.print(node.val + " ");
node = node.right;
}
}
}
中序遍历结果
递归中序遍历: 4 7 6 8 2 1 3 5
非递归中序遍历:4 7 6 8 2 1 3 5
后序遍历
递归后序遍历
过程和递归先序遍历类似
// 递归后序遍历
public static void recursionPostorderTraversal(TreeNode root) {
if (root != null) {
recursionPostorderTraversal(root.left);
recursionPostorderTraversal(root.right);
System.out.print(root.val + " ");
}
}
非递归后序遍历
后续遍历和先序、中序遍历不太一样。
后序遍历在决定是否可以输出当前节点的值的时候,需要考虑其左右子树是否都已经遍历完成。
所以需要设置一个lastVisit游标。
若lastVisit等于当前考查节点的右子树,表示该节点的左右子树都已经遍历完成,则可以输出当前节点。
并把lastVisit节点设置成当前节点,将当前游标节点node设置为空,下一轮就可以访问栈顶元素。
否者,需要接着考虑右子树,node = node.right。
以下考虑后序遍历中的三种情况:

如图3所示,从节点1开始考查直到节点4的左子树为空。
注:此时的游标节点node = 4.left == null。
此时需要从栈中查看 Peek()栈顶元素。
发现节点4的右子树非空,需要接着考查右子树,4不能输出,node = node.right。

如图4所示,考查到节点7(7.left == null,7是从栈中弹出),其左右子树都为空,可以直接输出7。
此时需要把lastVisit设置成节点7,并把游标节点node设置成null,下一轮循环的时候会考查栈中的节点6。

如图5所示,考查完节点8之后(lastVisit == 节点8),将游标节点node赋值为栈顶元素6,节点6的右子树正好等于节点8。表示节点6的左右子树都已经遍历完成,直接输出6。
此时,可以将节点直接从栈中弹出Pop(),之前用的只是Peek()。
将游标节点node设置成null。
// 非递归后序遍历
public static void postorderTraversal(TreeNode root) {
Stack<TreeNode> treeNodeStack = new Stack<TreeNode>();
TreeNode node = root;
TreeNode lastVisit = root;
while (node != null || !treeNodeStack.isEmpty()) {
while (node != null) {
treeNodeStack.push(node);
node = node.left;
}
//查看当前栈顶元素
node = treeNodeStack.peek();
//如果其右子树也为空,或者右子树已经访问
//则可以直接输出当前节点的值
if (node.right == null || node.right == lastVisit) {
System.out.print(node.val + " ");
treeNodeStack.pop();
lastVisit = node;
node = null;
} else {
//否则,继续遍历右子树
node = node.right;
}
}
}
后序遍历结果
递归后序遍历: 7 8 6 4 2 5 3 1
非递归后序遍历:7 8 6 4 2 5 3 1
完整算法、用例 by Golang
package main
import "fmt"
type Node struct {
V int
L *Node
R *Node
}
//前序
func forwardLook(root *Node) {
if root == nil {
return
}
//输出行的位置在最前面
fmt.Printf("node %v ", root.V)
forwardLook(root.L)
forwardLook(root.R)
}
//var i int
func forwardLoop(root *Node) {
//需要一个堆保存走过的路径
nodes:=[]*Node{}
for len(nodes) != || root != nil {
//一直往左走
for root != nil{
nodes=append(nodes, root)
fmt.Printf("node %v ",root.V)
root = root.L
}
//说明左子结点为空,那么就看右结点
if len(nodes) > {
root=nodes[len(nodes)-]
//用完最近一个结点后,删除它,删除后最后的结点一定是父结点
nodes=nodes[:len(nodes)-]
//左子结点遍历完了,所以这里只看当看结点的右子结点
root=root.R
}else{
root = nil
}
}
}
//中序
func middleLook(root *Node) {
if root == nil {
return
}
middleLook(root.L)
//输出行的位置在中间
fmt.Printf("node %v ", root.V)
middleLook(root.R)
}
//后序
func backwardLook(root *Node) {
if root == nil {
return
}
//输出行的位置在后面
backwardLook(root.L)
backwardLook(root.R)
fmt.Printf("node %v ", root.V)
}
func main(){
tree:=&Node{,
&Node{,
&Node{, nil, nil}, &Node{, nil, nil},
},
&Node{,
&Node{, nil, nil}, &Node{, nil, nil},
},
}
fmt.Println("\nforwardLook ")
forwardLook(tree)
fmt.Println("\nforwardLoop ")
forwardLoop(tree)
fmt.Println("\nmiddleLook ")
middleLook(tree)
fmt.Println("\nbackwardLook ")
backwardLook(tree)
tree=&Node{,
&Node{,
nil,
&Node{,
nil,
&Node{,
&Node{, nil, nil},
&Node{, nil, nil},
},
},
},
&Node{,
nil, &Node{, nil, nil},
},
}
fmt.Println("\nforwardLook ")
forwardLook(tree)
fmt.Println("\nforwardLoop ")
forwardLoop(tree)
fmt.Println("\nmiddleLook ")
middleLook(tree)
fmt.Println("\nbackwardLook ")
backwardLook(tree)
}
总结
玩透二叉树(Binary-Tree)及前序(先序)、中序、后序【递归和非递归】遍历的更多相关文章
- [LeetCode] 889. Construct Binary Tree from Preorder and Postorder Traversal 由先序和后序遍历建立二叉树
Return any binary tree that matches the given preorder and postorder traversals. Values in the trave ...
- 二叉树(Binary Tree)相关算法的实现
写在前面: 二叉树是比较简单的一种数据结构,理解并熟练掌握其相关算法对于复杂数据结构的学习大有裨益 一.二叉树的创建 [不喜欢理论的点我跳过>>] 所谓的创建二叉树,其实就是让计算机去存储 ...
- DS Tree 已知先序、中序 => 建树 => 求后序
参考:二叉树--前序和中序得到后序 思路历程: 在最初敲的时候,经常会弄混preorder和midorder的元素位置.大体的思路就是在preorder中找到根节点(根节点在序列的左边),然后在mid ...
- C实现二叉树(模块化集成,遍历的递归与非递归实现)
C实现二叉树模块化集成 实验源码介绍(源代码的总体介绍):header.h : 头文件链栈,循环队列,二叉树的结构声明和相关函数的声明.LinkStack.c : 链栈的相关操作函数定义.Queue. ...
- 已知树的前序、中序,求后序的java实现&已知树的后序、中序,求前序的java实现
public class Order { int findPosInInOrder(String str,String in,int position){ char c = str.charAt(po ...
- 数据结构二叉树的递归与非递归遍历之java,javascript,php实现可编译(1)java
前一段时间,学习数据结构的各种算法,概念不难理解,只是被C++的指针给弄的犯糊涂,于是用java,web,javascript,分别去实现数据结构的各种算法. 二叉树的遍历,本分享只是以二叉树中的先序 ...
- 二叉树3种递归和非递归遍历(Java)
import java.util.Stack; //二叉树3种递归和非递归遍历(Java) public class Traverse { /******************一二进制树的定义*** ...
- JAVA递归、非递归遍历二叉树(转)
原文链接: JAVA递归.非递归遍历二叉树 import java.util.Stack; import java.util.HashMap; public class BinTree { priva ...
- 二叉树前中后/层次遍历的递归与非递归形式(c++)
/* 二叉树前中后/层次遍历的递归与非递归形式 */ //*************** void preOrder1(BinaryTreeNode* pRoot) { if(pRoot==NULL) ...
- 二分查找(Binary Search)的递归和非递归
Binary Search 有时候我们也把它叫做二进制查找 是一种较为高效的再数组中查找目标元素的方法 我们可以通过递归和非递归两种方式来实现它 //非递归 public static int bin ...
随机推荐
- lvm调整卷大小
lvreduce -L 10240M /dev/rhel/home pvchange -xn /dev/sdb1 pvmove -i /dev/sdb1 vgreduce rhel /dev/sdb1 ...
- Celery详解(3)
1.什么是Celery? Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统 专注于实时处理的异步任务队列,同时也支持任务调度 2.Celery架构 Celery的架构由三部分组成,消息中 ...
- c# 第15节 StringBuilder
本节内容: 1:StringBuilder 2:内容总结 1:StringBuilder 实例: 2:内容总结 项目:
- 1. jenkins 安装部署
参考文档: https://jenkins.io/zh 准备环境 - jdk 路径: https://www.oracle.com/technetwork/java/javase/a ...
- 网络服务—NFS
什么是NFS ? NFS 是Network File System的缩写,即网络文件系统.一种使用于分散式文件系统的协定,由Sun公司开发,于1984年向外公布.功能是通过网络让不同的机器.不同的操作 ...
- 打开navicat 报错????
好心好意打开数据库图形化管理工具居然报错了???? 那怎么办呢????? google一下吧...... 下载两个文件 就是这两个 放入你的图形化页面的目录中 就可以正常打开了 帅不帅??? 那怎么下 ...
- Tomcat服务部署与Nginx负载均衡配置
一.中间键产品介绍 目前来说IBM的WebSphere,Oracle的Weblogic占据了市场上java语言Web站点的部分份额,该两种软件都是商业化的软件,由于性能优越,可靠性高等优点应用于大型互 ...
- Zabbix设置邮件报警
邮件报警 概述当监控项收集了数据后,触发器会根据异常状态触发报警.根据一些报警机制,它也会通知我们一些重要的事件,而不需要我们直接在Zabbix前端进行查看.这就是通知(Notifications)的 ...
- AtCoder Grand Contest 035
Preface Atcoder的题都好劲啊,都是我做不动的计数与构造 就当锻炼自己的思维能力了(基本都是bzt教的) A - XOR Circle bzt说这题数据太水了只要判一下所有数异或值是否为\ ...
- [LeetCode] 230. Kth Smallest Element in a BST 二叉搜索树中的第K小的元素
Given a binary search tree, write a function kthSmallest to find the kth smallest element in it. Not ...