【转载】 十图详解tensorflow数据读取机制(附代码)
原文地址:
https://zhuanlan.zhihu.com/p/27238630

------------------------------------------------------------------------------------------------------
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解。确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料。今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下tensorflow的数据读取机制,文章的最后还会给出实战代码以供参考。
一、tensorflow读取机制图解
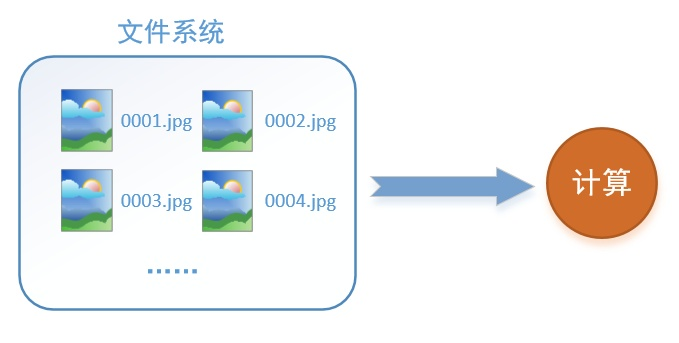
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
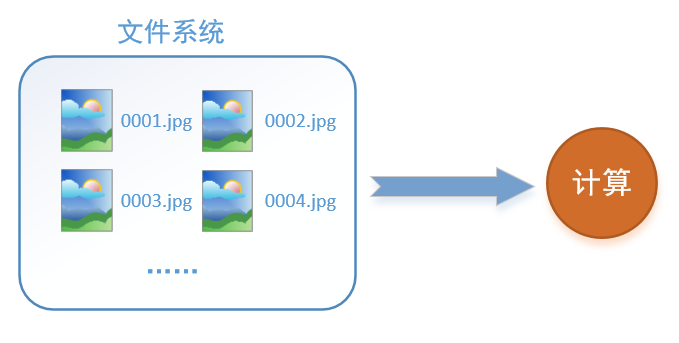
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
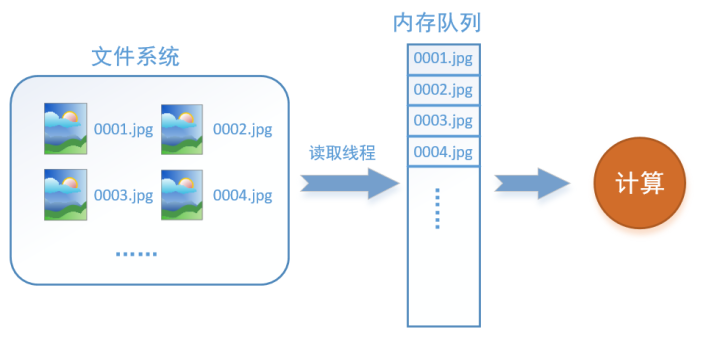
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
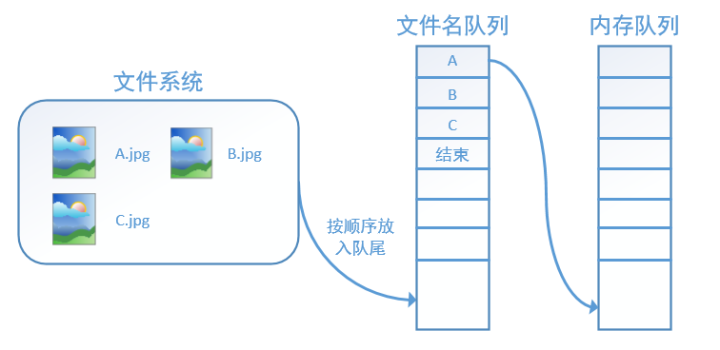
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
tensorflow使用文件名队列+内存队列 双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
程序运行后,内存队列首先读入A(此时A从文件名队列中出队):
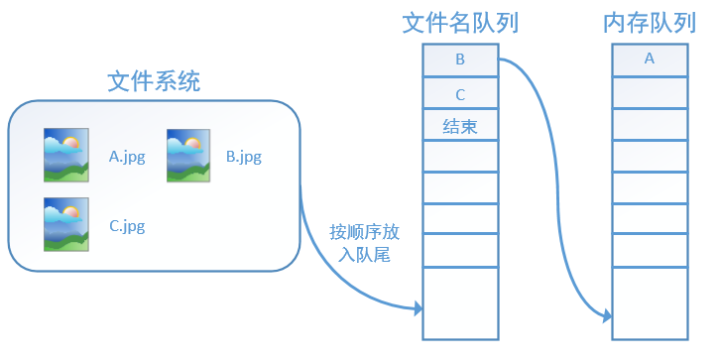
再依次读入B和C:
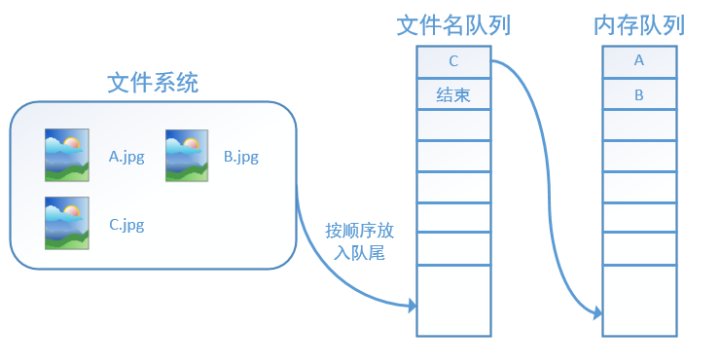
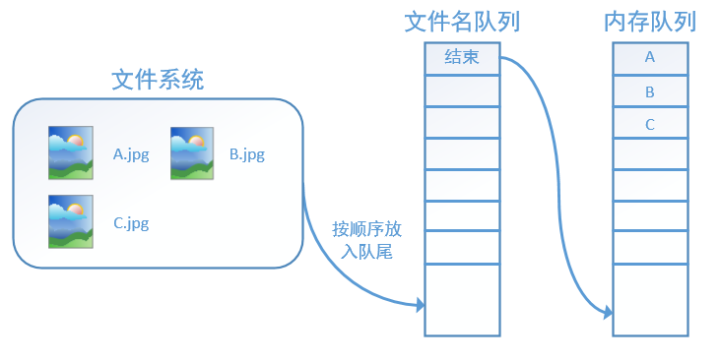
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。 如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
二、tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
对于文件名队列,我们使用 tf.train.string_input_producer 函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
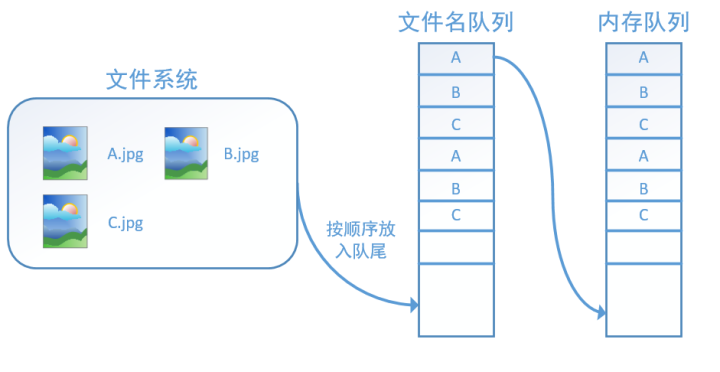
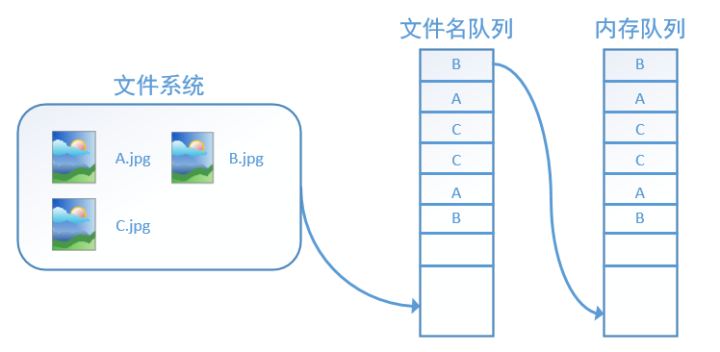
此外 tf.train.string_input_producer 还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
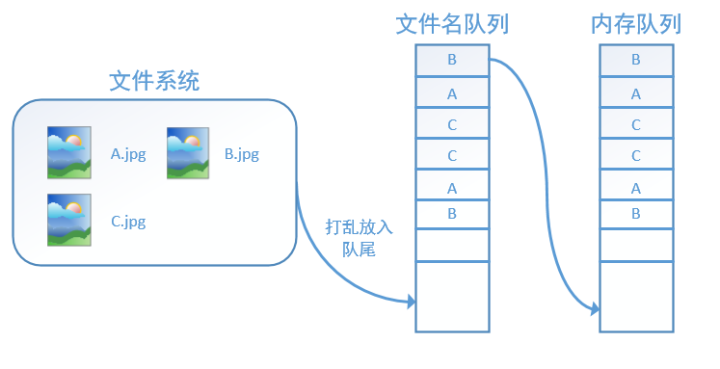
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners 。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用 tf.train.string_input_producer 创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
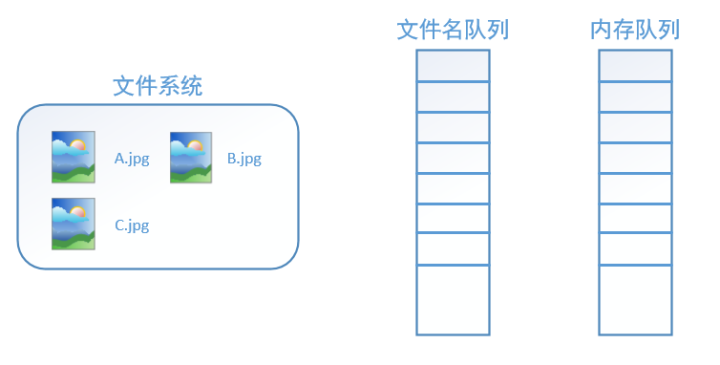
而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。
三、实战代码

对应的代码如下:
# 导入tensorflow
import tensorflow as tf # 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片A.jpg, B.jpg, C.jpg
filename = ['A.jpg', 'B.jpg', 'C.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open('read/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)
我们这里使用 filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5) 建立了一个会跑5个epoch的文件名队列。
并使用reader读取,reader每次读取一张图片并保存。
运行代码后,我们得到就可以看到read文件夹中的图片,正好是按顺序的5个epoch:

如果我们设置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那么在每个epoch内图像就会被打乱,如图所示:

我们这里只是用三张图片举例,实际应用中一个数据集肯定不止3张图片,不过涉及到的原理都是共通的。
四、总结
这篇文章主要用图解的方式详细介绍了tensorflow读取数据的机制,最后还给出了对应的实战代码,希望能够给大家学习tensorflow带来一些实质性的帮助。如果各位小伙伴还有什么疑问,欢迎评论或私信告诉我,谢谢~
------------------------------------------------------------------------------------------------------
【转载】 十图详解tensorflow数据读取机制(附代码)的更多相关文章
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630 在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找 ...
- 十图详解tensorflow数据读取机制
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 十图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 详解Tensorflow数据读取有三种方式(next_batch)
转自:https://blog.csdn.net/lujiandong1/article/details/53376802 Tensorflow数据读取有三种方式: Preloaded data: 预 ...
- Tensorflow数据读取机制
展示如何将数据输入到计算图中 Dataset可以看作是相同类型"元素"的有序列表,在实际使用时,单个元素可以是向量.字符串.图片甚至是tuple或dict. 数据集对象实例化: d ...
- [转载] 多图详解Spring框架的设计理念与设计模式
转载自http://developer.51cto.com/art/201006/205212_all.htm Spring作为现在最优秀的框架之一,已被广泛的使用,51CTO也曾经针对Spring框 ...
- 面渣逆袭:Spring三十五问,四万字+五十图详解
大家好,我是老三啊,面渣逆袭 继续,这节我们来搞定另一个面试必问知识点--Spring. 有人说,"Java程序员都是Spring程序员",老三不太赞成这个观点,但是这也可以看出S ...
- Transformer各层网络结构详解!面试必备!(附代码实现)
1. 什么是Transformer <Attention Is All You Need>是一篇Google提出的将Attention思想发挥到极致的论文.这篇论文中提出一个全新的模型,叫 ...
随机推荐
- python高级特性-迭代
概述 for v in d.values(): for k,v in d.items(): for a in 'adfa': #判断对象是否可迭代 from collections i ...
- 使用AutoIt实现文件上传
在网页上上传文件的时候,Selenium无法直接操作如Flash.JavaScript 或Ajax 等技术所实现的上传功能,这时候我们需要借用一个叫做AutoIt的软件来帮助我们事先自动化的上传操作. ...
- Kotlin数据类深度解析与底层剖析
今天来学习一下全新关于Kotlin的概念---数据类[data class],也是非常有用的东东,下面先来对其进行理论化的了解: 数据类其实跟java的实体类(model)很类似,像Java定义一个P ...
- Handling skewed data---trading off precision& recall
preision与recall之间的权衡 依然是cancer prediction的例子,预测为cancer时,y=1;一般来说做为logistic regression我们是当hθ(x)>=0 ...
- 火狐谷歌webdriver驱动地址
ChormeDrive下载 打开百度搜索Chromedriver官网下载,点击进入这个页面,链接为:http://npm.taobao.org/mirrors/chromedriver/2.41/ ...
- gdb, pdb笔记
gdb gdb --args yourprogram 常用命令 r(run):从头开始运行 c(continue):继续运行 b(breakpoint) filepath:line or namesp ...
- Tensorflow细节-P186-队列与多线程
先感受一下队列之美 import tensorflow as tf q = tf.FIFOQueue(2, "int32") # 创建一个先进先出队列 # 队列中最多可以保存两个元 ...
- Mac 下Wireshark 找不到网卡
终端上面,执行如下命令: sudo chgrp admin /dev/bpf* sudo chmod g+rw /dev/bpf*
- learning java AWT 画图
import javax.swing.*; import java.awt.*; import java.util.Random; public class SimpleDraw { private ...
- 在Ubuntu 或 Debian 系统环境安装MYSQL数据库
一.第一步下载myslq安装程序 sudo apt-get install mysql-server mysql-client apt-get程序会自动下载安装最新的mysql版本.在安装的最后,它会 ...