Two-Stream Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition
Two-Stream Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition
摘要
基于骨架的动作识别因为其以时空结合图(spatiotemporal graph)的形式模拟了人体骨骼而取得了显著的效果。
在现有的基于图的方法中,图的拓扑结构是手动设置的,而且在所有层以及输入样本中是固定不变的。这样的方法在用在有层级CNN和不同输入样本的动作识别中不是最佳的。
而且骨架中的具有更多细节和判别式信息二级结构(骨骼长度、方向、骨头等)很少在现有的方法中研究使用
作者提出了自适应的双流图网络结构用来进行基于骨架的动作识别,整个网络的拓扑结构可以端到端地学习出来,这种数据驱动的图模型增加了模型的灵活性,并且并且获得了更普适更一般化的特征来适应不同的样本
另外还采用了双流的结构同时模拟一级结构和二级结构,提高了动作识别的准确率
在NTU-RGBD以及Kinetics-Skeleton两个数据集上取得了非常好的结果
总结
- 提出了一个自适应的图卷积网络,可以自动学习出针对不同样本的不同的拓扑结构
- 提出了使用节点信息和骨头信息的双流网络结构
一、引言
目前有3种深度学习方法解决基于骨架的动作识别问题,分别是:将关节点序列表示成关节点向量,然后用RNN进行预测;将关节点信息表示成伪图像,然后用CNN去预测;将关节点信息表示成图结构,用图卷积进行预测。前两种方法不能将骨架信息中的图结构提取出来,也很难适应任意形状的骨架结构。最后一种的典型代表ST-GCN设计了一种时空图卷积网络,将人体的自然骨架结构通过拓扑图表示,动作识别性能得到了质的提升。
然而ST-GCN存在一些缺点:1. 根据人体自然结构预先定义好的拓扑结构图对于动作识别任务来说可能不是最优的;2. ST-GCN网络结构的每一个GCN单元的结构都是固定的,整个网络缺少灵活性;3.一个固定的网络结构对于不同样本的不同种类的动作不是最优的。
针对以上问题,作者提出了一个自适应的双流图网络结构:
- 一个自适应的图网络结构:针对不同的GCN单元和不同的样本自动生成不同的拓扑结构图。主要是通过设置两种不同的参数来对模型的拓扑图结构进行控制,一种是全局图,表示所有数据公有的模式结构,另一种是独立图,表示的是每个数据独特的模式结构。这种数据驱动的方法增加了模型图结构的灵活性,更加普遍适用于各种各样的样本。
- 双流结构:利用关节点和骨头两种信息设计双流网络结构,使用更丰富的骨架信息进行动作识别,显著的提高了识别性能。
- 在NTU RGB+D和kinetics上取得了最好的性能。
二、相关工作
基于骨架的动作识别:RNN、CNN、GCN三种
GCN:spatial perspective(空间), spectral perspective(光谱)
三、GCN
见另外一篇介绍ST-GCN的博文,主要看implementation
四、2s-AGCN
1.自适应卷积层
原始GCN:
\[
\mathbf{f}_{o u t}=\sum_{k}^{K_{v}} \mathbf{W}_{k}\left(\mathbf{f}_{i n} \mathbf{A}_{k}\right) \odot \mathbf{M}_{k} \qquad(公式1)
\]
\(K_v\)指的是区域划分,这里用的是第三种划分方式,即将邻域划分为3个部分,\(W_k\)指的是第\(k\)个区域的参数,\(f_{in}\)指的是网络输入,\(A_k\)指的是邻接矩阵和单位矩阵的和,表示节点之间的连接。\(M_k\)指的是自适应权重矩阵。
\[
\mathbf{f}_{o u t}=\sum_{k}^{K_{v}} \mathbf{W}_{k}\mathbf{f}_{i n} \left(\mathbf{A}_{k}+\mathbf{B}_{k}+\mathbf{C}_{k}\right) \qquad(公式2)
\]
其中\(A_k\)和公式(1)中一样,指的是邻接矩阵
\(B_k\)是一个\(N \times N\)的矩阵,和网络中的其他参数仪器优化训练,没有任何约束,可以是任何元素,不仅可以增强节点之间的连接,而且可以使没有关联的节点之间产生关联。在这里的功能和公式(1)中的\(M_k\)类似,但是\(M_k\)只能改变原来不为零的权重,无法让为零的权重重新变成一个起作用的权重值,比如拥抱的姿势,两个胳膊之间的动作比较相似,有一定的关联,但是人体自然结构无法将这两个节点连接起来,利用这个随机的\(B_k\)参数就可以使得这种没有人体自然结构关联的节点关联到一起。所以\(B_k\)是一项完全由训练数据学习出来的参数,比原始的\(M_k\)更加灵活。
\(C_k\)针对每一个样本学习出一个图,用normalized embedded Gaussian方程来衡量两个节点之间的相似性:
\[
f\left(v_{i}, v_{j}\right)=\frac{e^{\theta\left(v_{i}\right)^{T} \phi\left(v_{j}\right)}}{\sum_{j=1}^{N} e^{\theta\left(v_{i}\right)^{T} \phi\left(v_{j}\right)}} \qquad 公式(3)
\]
对于输入的特征图\(f_{in}\)大小为\(C_{in} \times T \times N\),首先用两个embedding方程\(\theta,\phi\)将其embed成\(C_e \times T \times N\),并将其resize成\(N \times C_eT\)和\(C_eT \times N\),然后将生成的两个矩阵相乘得到\(N \times N\)的相似矩阵\(C_k\),\(C^{ij}_k\)表示节点\(v_i\)和节点\(v_j\)之间的相似性,因为normalized Gaussian和softmax操作是等价的,所以公式(3)等同于公式(4)。如下图所示是AGCN的计算过程示意图。
\[
\mathbf{C}_k = softmax(\mathbf{f}_{in}^T\mathbf{W}_{\theta k}^T\mathbf{W}_{\theta k}\mathbf{f}_{in})
\]
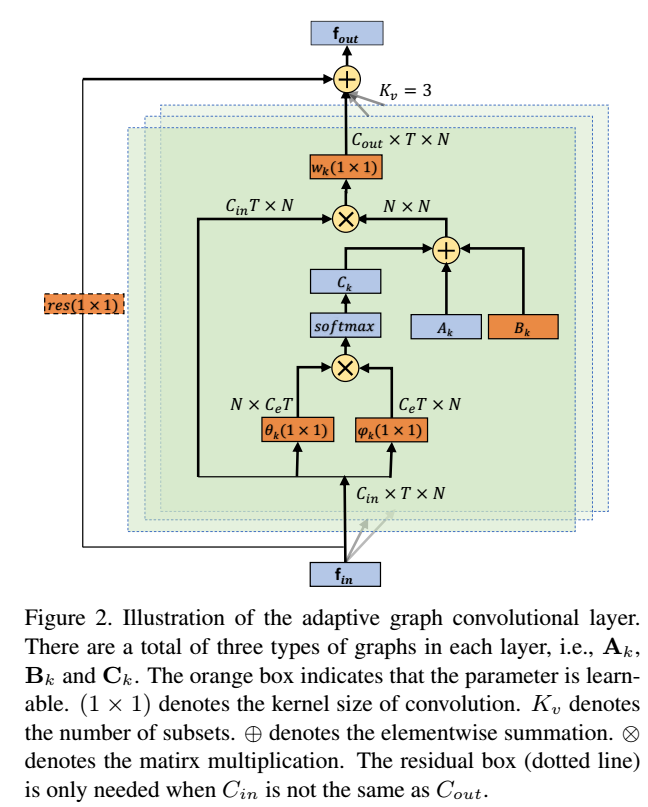
2. 自适应图卷积块
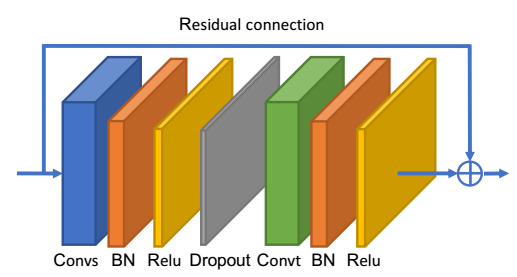
网络的时域和ST-GCN一样,都是对\(C \times T \times N\)的特征图进行\(K_t \times 1\)的卷积,空间域的GCN块(Convs)和时间域的GCN块(Convt)联合起来组成GCN块,如下图所示。
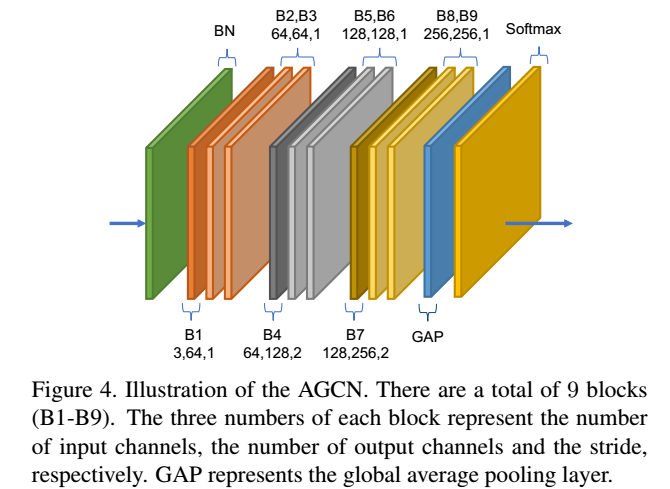
3. 自适应的图卷积网络
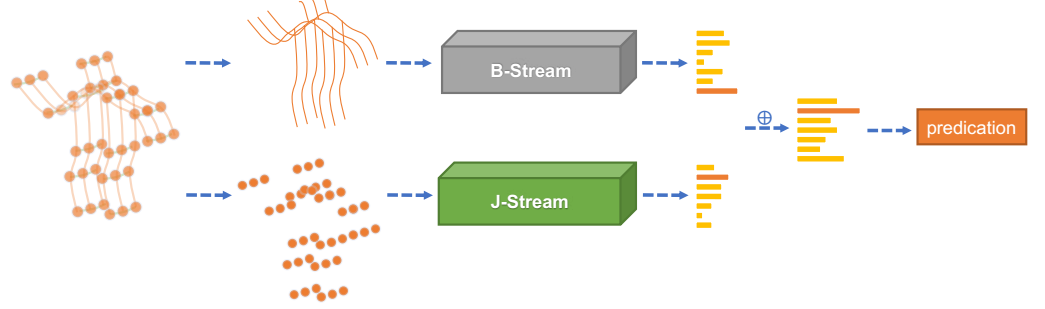
4. 双流网络
计算骨头信息作为第二类信息,源点\(v_1 = (x_1, y_1, z_1)\),目标点\(v2 = (x_2, y_2, z_2)\),则骨头\(e_{v_1,v_2} = (x_2-x_1, y_2-y_1, z_2-z_1)\),因为边数总比节点数少一个,所以增加一个中心点自环的一个长度为0的边。最后将两支网络输出的softmax打分值加和作为最后的分数去预测动作标签。
五、实验
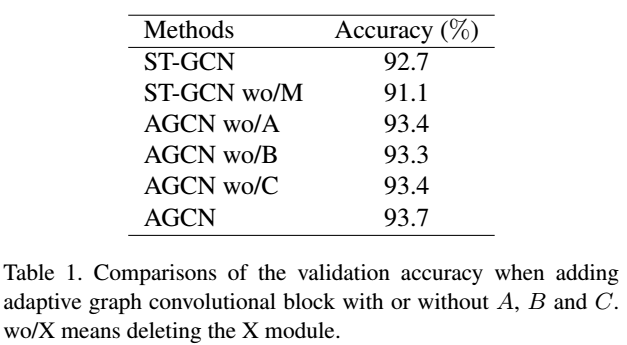
1.消融实验

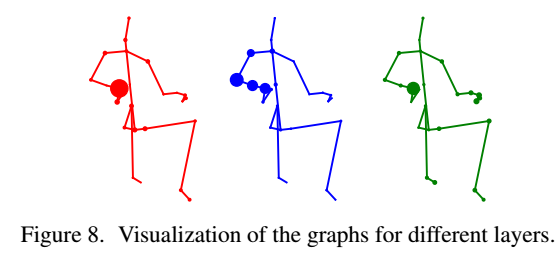
2.图的可视化
一个样本的不同层的图结构是不同的,而且每个节点的重要性是
不同的
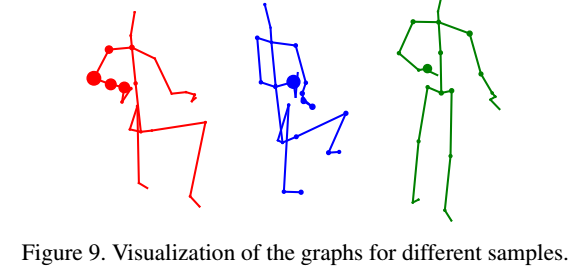
不同样本相同层的图结构是不同的
3.和state-of-the-arts比较

版权声明:本文为博主原创文章,未经博主允许不得转载。
Two-Stream Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition的更多相关文章
- 《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 代码解读
论文链接:https://arxiv.org/abs/1811.05320 博客原作者Missouter,博客链接https://www.cnblogs.com/missouter/,欢迎交流. 解读 ...
- Graph Convolutional Network
How to do Deep Learning on Graphs with Graph Convolutional Networks https://towardsdatascience.com/h ...
- GRAPH CONVOLUTIONAL NETWORK WITH SEQUENTIAL ATTENTION FOR GOAL-ORIENTED DIALOGUE SYSTEMS
面向领域特定目标的对话系统通常需要建模三种类型的输入,即(i)与领域相关的知识库,(ii)对话的历史(即话语序列)和(iii)需要生成响应的当前话语. 在对这些输入进行建模时,当前最先进的模型(如Me ...
- GCN(Graph Convolutional Network)的简单公式推导
第一步:从前一个隐藏层到后一个隐藏层,对结点进行特征变换 第二步:对第一步进行具体实现 第三步:对邻接矩阵进行归一化(行之和为1) 邻接矩阵A的归一化,可以通过度矩阵D来实现(即通过D^-1*A来实现 ...
- GCN: Graph Convolutional Network
从CNN到GCN的联系与区别: https://www.zhihu.com/question/54504471/answer/332657604 更加详解Laplacian矩阵: https://ww ...
- 关于Graph Convolutional Network的初步理解
为给之后关于图卷积网络的科研做知识积累,这里写一篇关于GCN基本理解的博客.GCN的本质是一个图网络中,特征信息的交互+与传播.这里的图指的不是图片,而是数据结构中的图,图卷积网络的应用非常广泛 ,经 ...
- 《T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction》 论文解读
论文链接:https://arxiv.org/abs/1811.05320 最近发现博客好像会被CSDN和一些奇怪的野鸡网站爬下来?看见有人跟爬虫机器人单方面讨论问题我也蛮无奈的.总之原作者Misso ...
- 基于3D卷积神经网络的行为识别:3D Convolutional Neural Networks for Human Action Recognition
简介: 这是一片发表在TPAMI上的文章,可以看见作者有余凯(是百度的那个余凯吗?) 本文提出了一种3D神经网络:通过在神经网络的输入中增加时间这个维度(连续帧),赋予神经网络行为识别的功能. 相应提 ...
- 论文笔记之:Semi-supervised Classification with Graph Convolutional Networks
Semi-supervised Classification with Graph Convolutional Networks 2018-01-16 22:33:36 1. 文章主要思想: 2. ...
随机推荐
- MySQL日记
MySQL日记 MySQL——day01:https://www.cnblogs.com/noonjuan/diary/2019/07/24/11241543.html MySQL——day02:ht ...
- Centos 7使用docker部署LAMP搭建wordpress博客系统
0.简要概述 LAMP是目前比较流行的web框架,即Linux+Apache+Mysql+PHP的网站架构方案.docker是目前非常流行的虚拟化应用容器,可以为任何应用创建一个轻量级.可移植的容器. ...
- [LeetCode] 683. K Empty Slots K个空槽
There is a garden with N slots. In each slot, there is a flower. The N flowers will bloom one by one ...
- javaSript 处理电脑和浏览器pc端缩放对页面的影响
由于用户的个人习惯或其他原因,可能会调整到电脑上的缩放比例或者浏览器的缩放比例,如果访问页面会看起来比较不好看, 电脑上的缩放: 浏览器上的缩放: 解决方法: function detectZoom( ...
- mysql 基本操作 四
1.临时表 当绘画结束时,临时表会自动销毁,无法用show tables 查看 临时表. MariaDB [jason]> create temporary table tmp(pro ),ci ...
- Python - 批量下载 IIS 共享的文件
1.说明 用 IIS 以WEB形式发布了本地文件夹,提供文件下载,并设置了访问权限:默认下载需要点击一个一个的下载,web界面如下: 3.脚本 执行脚本批量下载文件,会在当前目录创建文件夹,并压缩该文 ...
- ascii码对照表(收藏)
https://blog.csdn.net/yueyueniaolzp/article/details/82178954 十进制代码 十六进制代码 MCS 字符或缩写 DEC 多国字符名 ASCII ...
- 转《深入理解 Java 内存模型》读书笔记
转:https://mp.weixin.qq.com/s/2hA6u4hLEPWlTPdD-XB-bg 前提 <深入理解 Java 内存模型>程晓明著,该书在以前看过一遍,现在学的东西越多 ...
- PyCharm创建Django项目并连接mysql数据库
0. 安装Django pip install django 1. 新建项目 注:我的Pycharm为社区版,创建项目时,File->New Project- 显示为: 注意勾选内容. 如果 ...
- 删除链表中的倒数第N个节点
题目 给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点. 示例: 给定一个链表: ->->->->, 和 n = . 当删除了倒数第二个节点后,链表变为 -&g ...