storm 介绍+八种grouping方法
Storm主要的应用场景就是流式数据处理,例如实时推荐系统,实时监控系统等。
storm中的相关概念
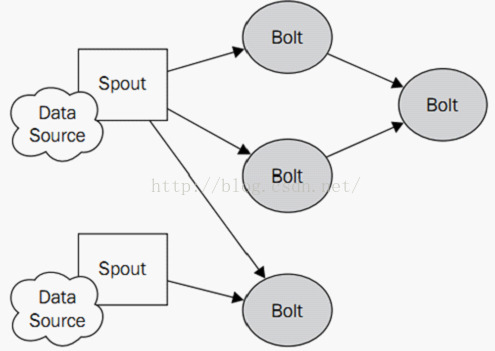
在storm中,分布式的计算结构指的是一个topology(拓扑),一个topology由流式数据,spouts(流生产者),以及bolts(具体操作者)组成。Storm的topologies和其他的批处理任务系统很类似,例如Hadoop,这类批处理任务都定义了清晰的开始和结束点,然而storm的topologies是永不停息的在运行的,除非杀死或者反部署这个topologies。
Topology:storm都是以topology为单位运行的,topology就相当于网络中的拓扑图一样。
Tuple:tuple是storm结构中的核心数据,一个tuple可以简单的理解为一系列的的键值对(key-value pairs),是storm结构中最小的数据单元。如果你对CEP(complex event processing)熟悉的话,你可以认为tuples就是事件集。
Streams:streams是由无限的tuples组成。
Spouts:spouts代表一个storm topology的数据入口,spouts扮演者适配器的作用,连接着一个个的数据源,并将数据转换成tuples,同时以数据流的方式发送tuples。数据源的来源有如下几种:1、网络或者是移动应用;2、推特或者是微博等社交网络;3、传感器输出;4、应用日志事件。典型的spouts不会实现任何的特定业务逻辑,所以spouts可以经常被重复交叉的被多个topologies使用
Bolts:bolts可以想象成计算的操作者或者是一个函数,他们可以接收任意的数据流或者被处理过的数据,而且还可以随意的发送一个或多个tuples,bolts可以订阅spouts或者是其他bolts发送过来的数据流,bolts可以创造一个复杂的数据传输网络。bolts的典型作用如下:1、过滤tuples;2、连接或者是聚合;3、计算
一个简单的topology如下图所示:
cleanup()方法,该方法只有在本地模式下才起作用,在集群模式下,是不起作用的,由于我们是在本地测试,所以我们使用的是storm的本地模式,storm的本地模式对我们的开发,测试,调试有很大的帮助作用,在我们部署成集群模式之前,我们可以充分的发挥本地模式的功能,在本地模式下,kill和关闭topology的时候,会调用这个cleanup()方法,从而实现我们打印统计结果的需求。

1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
2. Fields Grouping(相同fields去分发到同一个Bolt)
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,把tuple分配给task id最低的task 。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8.customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
总结:前4种用的多些,后面4种用的少些。
1. Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
2. Fields Grouping(相同fields去分发到同一个Bolt)
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
3. All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping
全局分组,把tuple分配给task id最低的task 。
5. None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8.customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
总结:前4种用的多些,后面4种用的少些。
1. builder.setBolt("bolt", new MyBolt(), 2).allGrouping("spout");//两个spot并行 所有都分发

2. builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout")其实就是随机往下游去发,不自觉的做到了负载均衡

3.builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id")); // fieldsGrouping其实就是MapReduce里面理解的Shuffle,根据fields求hash来取模,相同的名称的fields分发到一个bolt里面。

4.builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout"); // 只往一个里面发,往taskId小的那个里面去发送

为什么要用group?
栗子:
builder.setBolt(SPLIT_BOLT_ID, splitBolt).fieldsGrouping(SENTENCE_SPOUT_ID, new Fields("sentence"))
/*
* SplitSentenceBolt --> WordCountBolt
* 注意,此处需要使用fieldsGrouping来分组,要不然统计的数据会不准,例如一个Bolt中接收到{"word":"dog","count":"1"}
* 然后又来了一个{"word":"dog","count":"1"},但是又没有发送到同一个Bolt中,那么就会重新统计
*/
storm 介绍+八种grouping方法的更多相关文章
- WordPress慢的八种解决方法(用排查法解决)
WordPress的打开速度慢会影响到用户体验和关键词的稳定排名,WordPress为什么加载慢呢?其实很简单的,就是WordPress水土不服,用WordPress的大家都知道,WordPress是 ...
- springdata-jpa 八种查询方法
使用:maven+Spring+jpa+Junit4 查询方式:SQL,JPQL查询,Specification多条件复杂查询 返回类型:list<POJO>,list<Stinrg ...
- selenium—八种定位方法
find_element_by_id() find_element_by_name() find_element_by_class_name() find_element_by_tag_name() ...
- Storm-6 Storm的并行度、Grouping策略以及消息可靠处理机制简介
概念: 配置并行度 动态的改变并行度 流分组策略----Stream Grouping 消息的可靠处理机制 概念: Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程.一 ...
- mysql主从数据库不同步的2种解决方法(转)
今天发现Mysql的主从数据库没有同步 先上Master库: mysql>show processlist; 查看下进程是否Sleep太多.发现很正常. show master status; ...
- mysql主从数据库不同步的2种解决方法 (转载)
今天发现Mysql的主从数据库没有同步 先上Master库: mysql>show processlist; 查看下进程是否Sleep太多.发现很正常. show master status; ...
- 今天介绍一个渐变的方法,在shell里面自动生成注释简介
在编辑sh脚本时,我经常在shell中写一些注释.今天我介绍一种渐变方法,它可以在每次vim shell脚本时自动在shell中生成注释和其他信息. 让我们共享一个shell脚本模板文件,将其复制到用 ...
- http 中定义的八种请求的介绍
在http1.1协议中,共定义了8种可以向服务器发起的请求(这些请求也叫做方法或动作),本文对这八种请求做出简要的介绍: 1.PUT:put的本义是推送 这个请求的含义就是推送某个资源到服务器,相当于 ...
- Linux 的shell 字符串截取很有用。有八种方法。
一 Linux 的字符串截取很有用.有八种方法. 假设有变量 var=http://www.linuxidc.com/123.htm 1 # 号截取,删除左边字符,保留右边字符. echo ${va ...
随机推荐
- Asp.net MVC企业级开发(04)---SignalR消息推送
Asp.net SignalR是微软为实现实时通信而开发的一个类库.可以适用于以下场景: 聊天室,如在线客服系统,IM系统等 股票价格实时更新 消息的推送服务 游戏中人物位置的实时推送 SignalR ...
- Markdown温故知新(3):六个实用扩展语法
目录 1.表格(Table) 2.待办事项或清单(To Do List) 3.自动目录 TOC 4.流程图 5.时序图 6.甘特图 7.总结 1.表格(Table) 没用过 Markdown 表格的人 ...
- 详解Go变量类型的内存布局
定义 每当我们编写任何程序时,我们都需要在内存中存储一些数据/信息.数据存储在特定地址的存储器中.内存地址看起来像0xAFFFF(这是内存地址的十六进制表示). 现在,要访问数据,我们需要知道存储它的 ...
- 并发编程-线程,JMM,JVM,volatile
1.线程 相信大家对线程这个名词已经很不陌生了,从刚开始学习java就接触到线程,先说说进程吧,进程就是系统分配资源的基本单位,线程是调度cpu的基本单位,进程由线程组成,一个进程至少又一个线程组成, ...
- 为python脚本增加命令行参数
from argparse import ArgumentParser p = ArgumentParser() p.add_argument('-b', '--body', help='Return ...
- C#常用集合类的实现以及基本操作复杂度
List 集合类是顺序线性表,Add操作是O(1)或是O(n)的,由于List的容量是动态扩容的,在未扩容之前,其Add操作是O(1),而在需要扩容的时候,会拷贝已存在的那些元素同时添加新的元素,此时 ...
- vue底部导航的精准显示
让底部导航只显示在一级页面: 路由中的写法: import Vue from 'vue' import Router from 'vue-router' //import HelloWorld fro ...
- 如何构思你的iOS App应用
转自:http://mobile.51cto.com/hot-311134.htm 在twitter上,听到不少人问,我也有App 在App Store上面卖,为什么我的App卖得这么少啊?于是我就上 ...
- 利用Python读取图片exif敏感信息
众所周知,现在很多的照相机等软件,拍摄会有选项,是否包含位置信息等. 当然有的人会说,我在微信中查看图片exif信息并没有啊,这是因为你发送到微信服务器的时候,微信帮你完成了保密工作. 常见的图片中包 ...
- ta和夏天一起来了
目录 ta和夏天一起来了 上半年,过去的就让去过去,遗憾的也别再遗憾. 下半年,拥有的请好好珍惜,想要的请努力去追. ta和夏天一起来了 转眼结束了2019的上半年,在这个月末, 季度末, 周末, ...