66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一、数据处理原理剖析
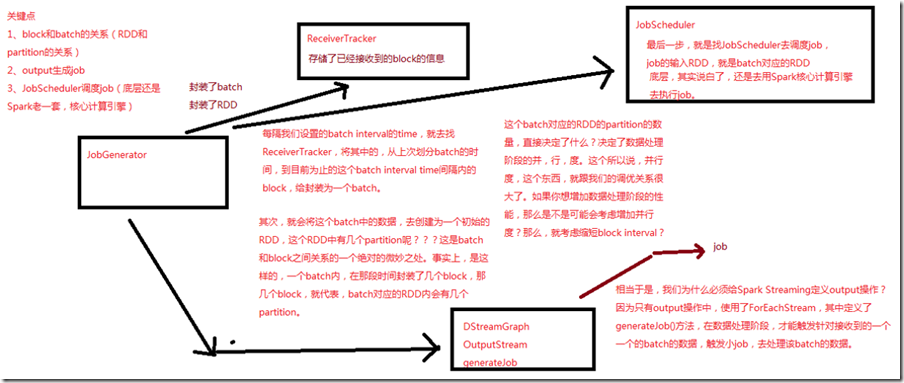
每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval time间隔内的block封装为一个batch; 其次,会将这个batch中的数据,去创建为一个初始的RDD,一个batch内,在这段时间封装了几个block,就代表这个batch对应的RDD内会有几个partition; 这个batch对应的RDD的partition决定了数据处理阶段的并行度,这个跟调优关系很大,如果想增加数据处理阶段的性能,就考虑增加并行度,那么就考虑缩短block interval; 只有output操作中,使用了ForEachStream,其中定义了generatorJob()方法,在数据处理阶段,才触发针对接收到的一个一个batch的数据,触发小的job,去处理该batch的数据; 最后一步,去找JobScheduler去调度job,job的输入RDD,就是batch对应的RDD;
二、源码分析
入口,JobGenerator的generateJobs()方法
###org.apache.spark.streaming.scheduler/JobGenerator.scala /**
* 定时,调度generateJobs()方法,传入一个time,其实就是一个batch interval内的时间段
*/
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
// 找到ReceiverTracker,调用其allocateBlocksToBatch方法,将当前时间段内的block分配给一个batch,并为其
// 创建一个RDD
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
// 调用DSteamGraph的generateJobs()来根据程序定义的DSteam之间的依赖关系和算子,生成job
graph.generateJobs(time) // generate jobs using allocated block
} match {
// 如果成功创建了job
case Success(jobs) =>
// 从ReceiverTracker中,获取当前batch interval对应的block数据
val receivedBlockInfos =
jobScheduler.receiverTracker.getBlocksOfBatch(time).mapValues { _.toArray }
// 用jobScheduler提交job,其对应的原始数据,是那批block
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventActor ! DoCheckpoint(time)
}
66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 21、Shuffle原理剖析与源码分析
一.普通shuffle原理 1.图解 假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core.假如有另外一台节点,上面也运行了4个ResultTask,现 ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 19、Executor原理剖析与源码分析
一.原理图解 二.源码分析 1.Executor注册机制 worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程: ...
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- JS中的逻辑运算符&&、||
原文:JS中的逻辑运算符&&.|| 1.JS中的||符号: 运算方法: 只要"||"前面为false,不管"||"后面是true还是false, ...
- 未能加载文件或程序集 Microsoft.ReportViewer.ProcessingObjectModel, Version=10.0.0.0
写在前面 整理错误集.某一天在启动项目的时候,出现了未能加载文件或程序集 Microsoft.ReportViewer.ProcessingObjectModel, Version=10.0.0.0错 ...
- 【WEB基础】HTML & CSS 基础入门(1)初识
前面 我们每天都在浏览着网络上丰富多彩的页面,那么在网页中所呈现出的绚丽多彩的内容是怎么设计出来的呢?我们想要自己设计一个页面又该如何来做呢?对于刚刚接触网页设计的小伙伴来说,看到网页背后的一堆符号和 ...
- Java自学-数组 复制数组
Java 如何复制数组 数组的长度是不可变的,一旦分配好空间,是多长,就多长,不能增加也不能减少 步骤 1 : 复制数组 把一个数组的值,复制到另一个数组中 System.arraycopy(src, ...
- html解决空格显示问题
在前端里面,大家都知道,html中输入空格或换行是识别不了是空格的,但是有时候需要实现,那么该如何解决呢?主要有以下几个方面: 1:常用的转义: 2:使用全角拼音,然后输入空格也可实现 3:用标签 ...
- Redis安装、主从配置及两种高可用集群搭建
Redis安装.主从配置及两种高可用集群搭建 一. 准备 Kali Linux虚拟机 三台:192.168.154.129.192.168.154.130.192.168.154 ...
- AudioToolbox--AudioQueue实现流播放接口
AudioMedia_ios.h // // AudioMedia_ios.h // mmsplayer // // Created by Weiny on 12-4-4. // Copyri ...
- 使用wxpy这个基于python实现的微信工具库的一些常见问题
使用如下的命令行安装: pip install wxpy Collecting wxpy Downloading https://files.pythonhosted.org/packages/6b/ ...
- EF 批量增删改 EntityFramework.Extensions
EntityFramework.Extensions 1.官方网站 http://entityframework-extensions.net/ 2 破解版 Z.EntityFramework.E ...
- C#-将照片存入到SQL SERVER
将存照片的字段设为image类型. using System; using System.Collections.Generic; using System.ComponentModel; using ...