19、Executor原理剖析与源码分析
一、原理图解
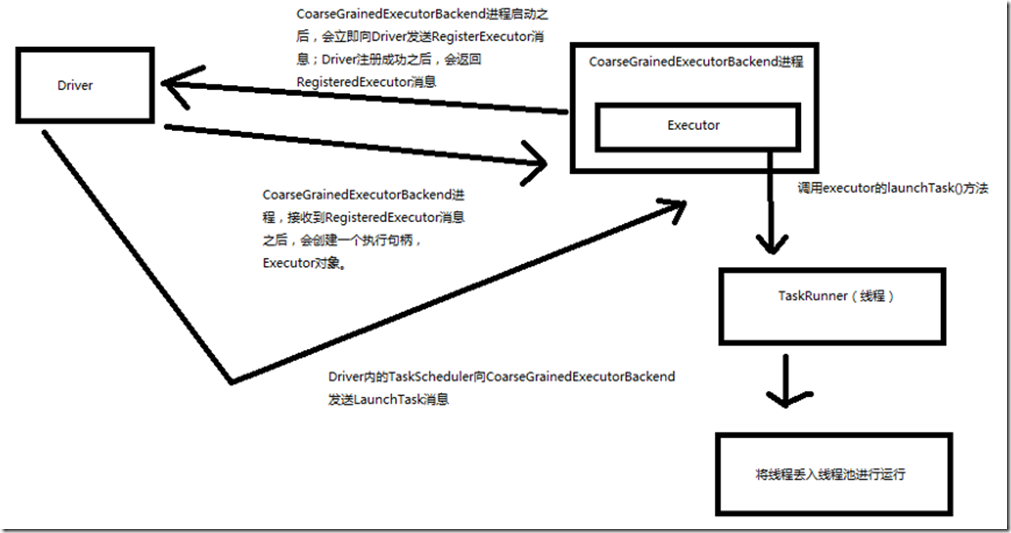
二、源码分析
1、Executor注册机制
worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程; Executor注册机制:
###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala /**
* 在actor的初始化方法中
*/
override def preStart() {
logInfo("Connecting to driver: " + driverUrl)
// 获取了driver的executor
driver = context.actorSelection(driverUrl)
// 向driver发送RegisterExecutor消息,driver是CoarseGrainedSchedulerBackend的一个内部类
// driver注册executor成功之后,会发送回来RegisteredExecutor消息
driver ! RegisterExecutor(executorId, hostPort, cores, extractLogUrls)
context.system.eventStream.subscribe(self, classOf[RemotingLifecycleEvent])
} ###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala override def receiveWithLogging = {
// driver注册executor成功之后,会发送回来RegisteredExecutor消息
// 此时,CoarseGrainedExecutorBackend会创建Executor对象,作为执行句柄
// 其实它的大部分功能,都是通过Executor实现的
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
val (hostname, _) = Utils.parseHostPort(hostPort)
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
3、启动Task
###org.apache.spark.executor/CoarseGrainedExecutorBackend.scala
// 启动task
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
// 反序列化task
val ser = env.closureSerializer.newInstance()
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 用内部的执行句柄,Executor的launchTask()方法来启动一个task
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
###org.apache.spark.executor/Executor.scala
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer) {
// 对于每一个task,都会创建一个TaskRunner
// TaskRunner继承的是Java多线程中的Runnable接口
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
// 将TaskRunner放入内存缓存
runningTasks.put(taskId, tr)
// Executor内部有一个Java线程池,这里其实将task封装在一个线程中(TaskRunner),直接将线程丢入线程池,进行执行
// 线程池是自动实现了排队机制的,也就是说,如果线程池内的线程暂时没有空闲的,那么丢进去的线程都是要排队的
threadPool.execute(tr)
}
19、Executor原理剖析与源码分析的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 21、Shuffle原理剖析与源码分析
一.普通shuffle原理 1.图解 假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core.假如有另外一台节点,上面也运行了4个ResultTask,现 ...
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- [LOJ3083] [GXOI2019] 与或和
题目链接 LOJ:https://loj.ac/problem/3083 洛谷:https://www.luogu.org/problemnew/show/P5300 Solution 逐位考虑,可以 ...
- C# ——Parallel类
一.Parallel类 Parallel类提供了数据和任务的并行性: 二.Paraller.For() Paraller.For()方法类似于C#的for循环语句,也是多次执行一个任务.使用Paral ...
- angular解决跨域问题
通过angular自身的代理转发功能 配置package.json 启动项目通过npm start启动,会自动启动代理服务npm start
- e.preventDefault()与e.stopPropagation()的区别
e.stopPropagation()阻止事件冒泡<table border='1'> <tr> <td><span>冒泡事件测试</span&g ...
- day28-python之property
1.property用法 # class Goods: # def __init__(self): # # 原价 # self.original_price = 100 # # 折扣 # self.d ...
- 解决问题 inner element must either be a resource reference or empty.
-Q: 错误<item>内部元素必须是资源引用或空 升级Andriod Studio之后编译发现如下错误 Android resource compilation failed ***\a ...
- JSP页面嵌套c:forEach
做java web项目有时候会需要在页面使用嵌套<c:forEach>遍历一个List,但是嵌套很容易忽略一些东西导致出错 后台代码: List<Map<String, Obj ...
- 2013.6.24 - OpenNE第四天
今天晚上跟师兄讨论,这那几篇论文,对于<领域多词表 达翻译对的自动抽取及其应用>那篇,我的感觉是跟实体识别不太吻合.他的大概意思就是先讲所有有可能的多词表达都找出来,然后在用C-value ...
- 阿里巴巴开源性能监控神器Arthas jvm
原文:https://www.cnblogs.com/testfan2019/p/11038791.html 如果问性能测试中最难的是哪部分,相信很多人会说“性能调优”.确实是这样,性能调优是一个非常 ...
- RQM — 需求驱动的测试管理工具
嵌入式系统复杂程度越来越高,随之而来的测试要求和任务也越来越繁重,而测试更多的是对产品满足需求情况的测试,因此,在高强度.高频度的测试过程中,难免有需求遗漏.回归测试不充分.缺陷管理不合理.测试人员疏 ...